



 本文深入探讨了支持向量机(SVM)的理论基础,包括优化目标、大边界的直观理解以及核函数的应用。通过分析正则化参数C和核函数参数σ的影响,帮助读者理解如何调整参数以避免过拟合或欠拟合。同时,提供了SVM编程作业的实现代码,包括Gaussian核函数和参数选择的方法。
本文深入探讨了支持向量机(SVM)的理论基础,包括优化目标、大边界的直观理解以及核函数的应用。通过分析正则化参数C和核函数参数σ的影响,帮助读者理解如何调整参数以避免过拟合或欠拟合。同时,提供了SVM编程作业的实现代码,包括Gaussian核函数和参数选择的方法。
支持向量机(SVM,Support Vector Machine)
一、理论基础
1.优化目标
!在这里插入图片描述
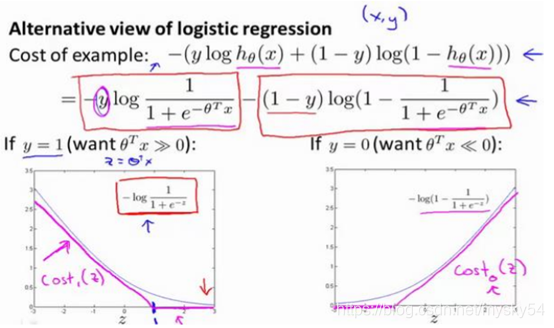
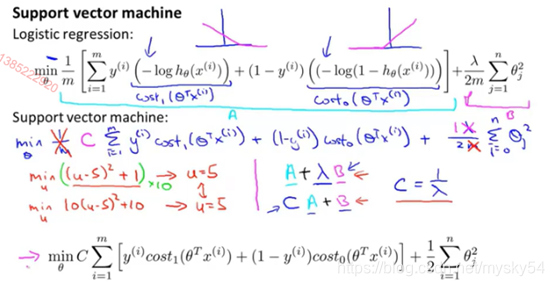
解释:可以去掉常数项1/m,因为它并不影响我们最小化θ的取值

与逻辑回归不同的是,支持向量机不会输出概率,当最小化代价函数,获得参数𝜃时,支持向量机所做的是它来直接预测𝑦的值等于 1,还是等于 0。
2.大边界的直观理解
支持向量机有时被称为大间距分类器

考察这样一个数据集,其中有正样本,也有负样本,可以看到这个数据集是线性可分的。存在一条直线把正负样本分开。当然有多条不同的直线,可以把正样本和负样本完全分开。
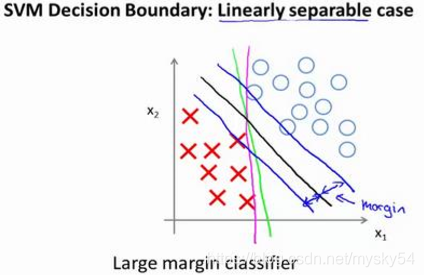
黑线看起来是更稳健的决策界。在分离正样本和负样本上它显得的更好。这条黑线有更大的距离,这个距离叫做间距(margin)
事实上,支持向量机现在要比这个大间距分类器所体现得更成熟,尤其是当你使用大间距分类器的时候,你的学习算法会受异常点(outlier) 的影响。比如我们加入一个额外的正样本。
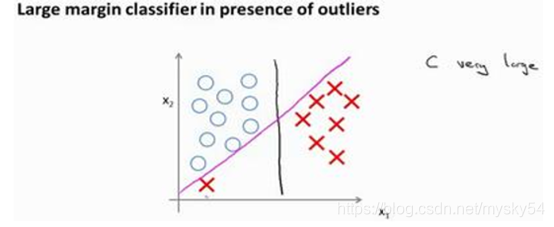
仅仅基于一个异常值,仅仅基于一个样本,就将我的决策界从这条黑线变到这条粉线,这实在是不明智的。而如果正则化参数𝐶,设置的非常大,这事实上正是支持向量机将会做的。 它将决策界,从黑线变到了粉线,但是如果𝐶设置的小一点,如果你将 C 设置的不要太大,则你最终会得到这条黑线。
𝐶的作用类似于1/𝜆,𝜆是我们之前使用过的正则化参数。实际上应用支持向量机的时候,当𝐶不是非常非常大的时候,它可以忽略掉一些异常点的影响,得到更好的决策界。
回顾 𝐶 = 1/𝜆,因此:
𝐶 较大时,相当于 𝜆 较小,可能会导致过拟合,高方差。
𝐶 较小时,相当于 𝜆 较大,可能会导致低拟合,高偏差。
3.核函数
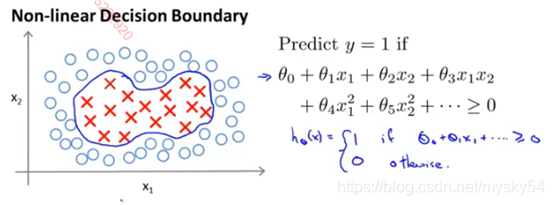
对于这个训练集,如果需要拟合一个非线性的判定边界来区别正负实例,一种办法就是构造一个复杂多项式的特征集合


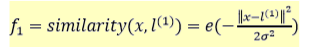
𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(𝑥,𝑙(1))就是核函数,具体而言,这里是一个高斯核函数(Gaussian Kernel)。
注:这个函数与正态分布没什么实际上的关系,只是看上去像而已。

假设我们的训练实例含有两个特征[𝑥1 𝑥2],给定地标𝑙(1)与不同的𝜎值,下面的图我们可以看出δ2δ2对函数图形的改变,见下图:
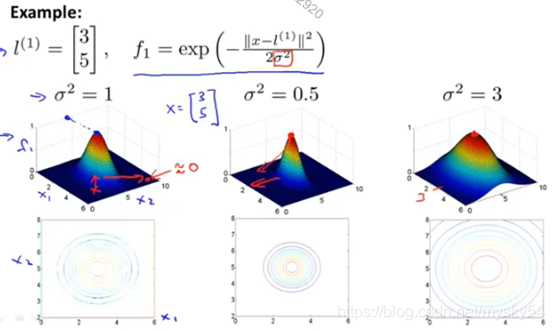
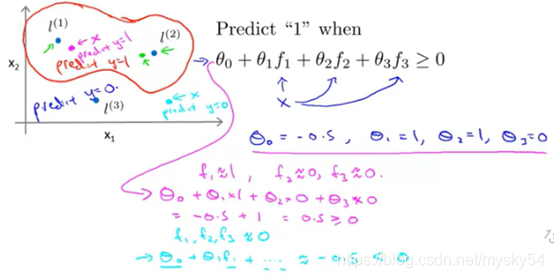

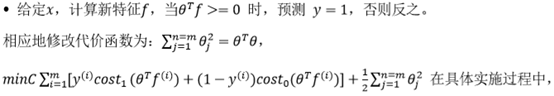

下面是支持向量机的两个参数𝐶和𝜎的影响: 𝐶 = 1/𝜆
𝐶 较大时,相当于𝜆较小,可能会导致过拟合,高方差;
𝐶 较小时,相当于𝜆较大,可能会导致低拟合,高偏差;
𝜎较大时,可能会导致低方差,高偏差;
𝜎较小时,可能会导致低偏差,高方差。
二、编程作业
1.gaussianKernel.m - Gaussian kernel for SVM :implement a Gaussian kernel
Gaussian kernel function:
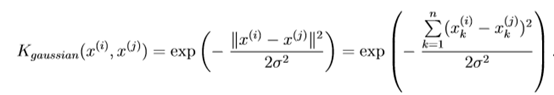
代码:
function sim = gaussianKernel(x1, x2, sigma)
% Ensure that x1 and x2 are column vectors
x1 = x1(:); x2 = x2(:);
% You need to return the following variables correctly.
sim = 0;
sim=exp(-sum((x1-x2).^2)/(2*sigma^2));
end
2.dataset3Params.m - Parameters to use for Dataset 3
代码:
function [C, sigma] = dataset3Params(X, y, Xval, yval)
% You need to return the following variables correctly.
C = 1;
sigma = 0.3;
value = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30];
minC = 0;
minSigma = 0;
% 最小值设为交叉验证集的用例数
minError = size(Xval,1);
for i = 1:length(value)
for j = 1:length(value)
model= svmTrain(X, y, value(i), @(x1, x2) gaussianKernel(x1, x2, value(j)));
predictions = svmPredict(model,Xval);
error = mean(double(predictions ~= yval));
if minError > error
minError = error;
minC = value(i);
minSigma = value(j);
end;
end;
end;
C = minC;
sigma = minSigma;
end
3.processEmail.m - Email preprocessing:look up the word in the vocabulary list vocabList and find if the word exists in the vocabulary list. If the word exists, you should add the index of the word into the word indices variable. If the word does not exist, and is therefore not in the vocabulary, you can skip the word.
代码:
4.emailFeatures.m - Feature extraction from emails:xi = 1 if the i-th word is in the email and xi = 0 if the i-th word is not present in the email.
代码:
function x = emailFeatures(word_indices)
% Total number of words in the dictionary
n = 1899;
% You need to return the following variables correctly.
x = zeros(n, 1);
x(word_indices) = 1;
end

















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}