




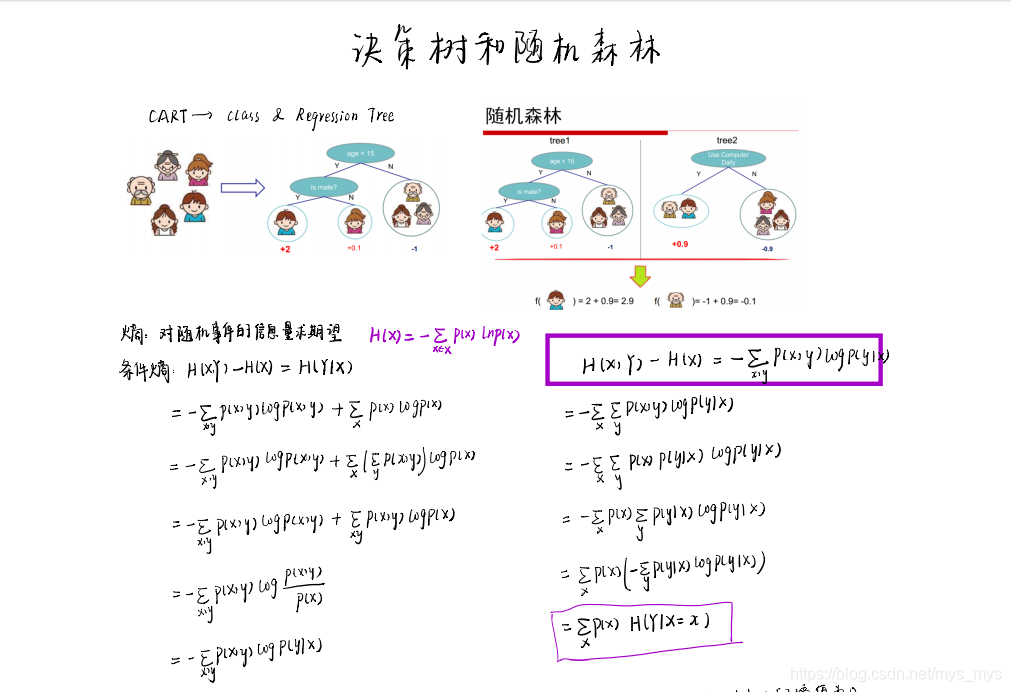
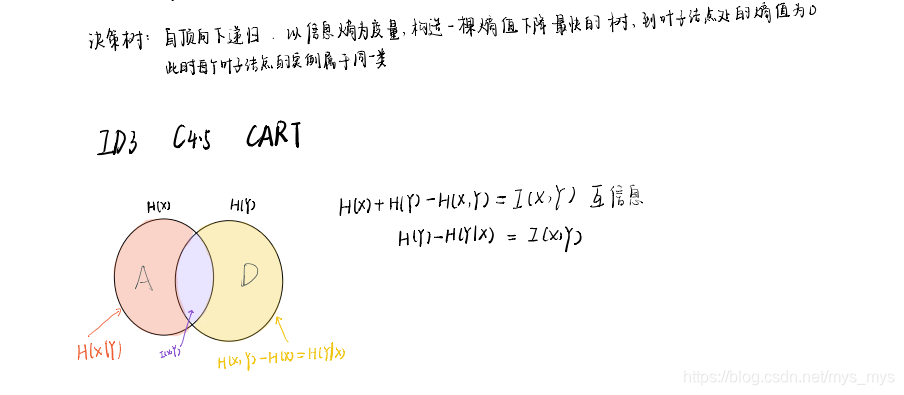
理论笔记
代码








DecisionTree
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
import pydotplus
if __name__ == "__main__":
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False
iris_feature_E = 'sepal length', 'sepal width', 'petal length', 'petal width'
iris_feature = '花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度'
iris_class = 'Iris-setosa', 'Iris-versicolor', 'Iris-virginica'
path = 'iris.data'
data = pd.read_csv(path, header=None)
x = data[list(range(4))]
y = LabelEncoder().fit_transform(data[4])
# 为了可视化,只显示前两列特征
x = x[[0, 1]]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)
# 决策树参数估计
model = DecisionTreeClassifier(criterion='entropy') # criterion选择特征的标准,默认gini
model.fit(x_train, y_train)
y_train_pred = model.predict(x_train)
print('训练集正确率:', accuracy_score(y_train, y_train_pred))
y_test_hat = model.predict(x_test)
print('测试集正确率', accuracy_score(y_test, y_test_hat))
# 保存
# 1.输出
tree.export_graphviz(model, out_file='iris.dot', feature_names=iris_feature_E[0:2], class_names=iris_class,
filled=True, rounded=True, special_characters=True)
# 2.给定文件名
# tree.export_graphviz(model, out_file='iris.dot')
# 3.输出为pdf格式
dot_data = tree.export_graphviz(model, out_file=None, feature_names=iris_feature_E[0:2], class_names=iris_class,
filled=True, rounded=True, special_characters=True)
# graph = pydotplus.graph_from_dot_data(dot_data)
# graph.write_pdf('iris.pdf')
# f = open('iris.png', 'wb')
# f.write(graph.create_png())
# f.close()
# 画图
N, M = 60, 60 # 横纵采样各多少值
x1_min, x2_min = x.min()
x1_max, x2_max = x.max()
t1 = np.linspace(x1_min, x2_min, N)
t2 = np.linspace(x1_max, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_show = np.stack((x1.flat, x2.flat), axis=1) # 测试点
print(x_show.shape)
print(('x_show = \n', x_show))
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_show_hat = model.predict(x_show) # 预测值
print(y_show_hat.shape)
print(y_show_hat)
y_show_hat = y_show_hat.reshape(x1.shape) # 使之与输入的形状相同
print(y_show_hat)
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_show_hat, cmap=cm_light) # 预测值显示
plt.scatter(x_test[0], x_test[1], c=y_test.ravel(), edgecolors='k', s=100,
zorder=10, cmap=cm_dark, marker="*")
plt.scatter(x[0], x[1], c=y.ravel(), edgecolors='k', s=20, cmap=cm_dark)
plt.xlabel(iris_feature[0], fontsize=13)
plt.ylabel(iris_feature[1], fontsize=13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid(b=True, ls=':', color='#606060')
plt.title('鸢尾花数据的决策树分类', fontsize=15)
plt.show()
# 训练集上的预测结果
y_test = y_test.reshape(-1)
print(y_test_hat)
print(y_test)
result = (y_test_hat == y_test)
acc = np.mean(result)
print('准确度:%.2f%%' % (100 * acc))
# 过拟合:错误率
depth = np.arange(1, 15)
err_train_list = []
err_test_list = []
clf = DecisionTreeClassifier(criterion='entropy')
for d in depth:
clf.set_params(max_depth=d)
clf.fit(x_train, y_train)
y_train_pred = clf.predict(x_train)
err_train = 1 - accuracy_score(y_train, y_train_pred)
err_train_list.append(err_train)
y_test_pred = clf.predict(x_test)
err_test = 1 - accuracy_score(y_test, y_test_pred)
err_test_list.append(err_test)
print(d, ' 测试集错误率: %.2f%%' % (100 * err_test))
plt.figure(facecolor='w')
plt.plot(depth, err_test_list, 'ro-', markeredgecolor='k', lw=2, label='测试集错误率')
plt.plot(depth, err_train_list, 'go-', markeredgecolor='k', lw=2, label='训练集错误率')
plt.xlabel('决策树深度', fontsize=13)
plt.ylabel('错误率', fontsize=13)
plt.legend(loc='lower left', fontsize=13)
plt.title('决策树深度与过拟合', fontsize=15)
plt.grid(b=True, ls=':', color='#606060')
plt.show()
XGBoost
import xgboost as xgb
import numpy as np
import pandas as pd
import csv
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestClassifier
def show_accuracy(a, b, tip):
acc = a.ravel() == b.ravel()
acc_rate = 100 * float(acc.sum()) / a.size
return acc_rate
def load_data(file_name, is_train):
data = pd.read_csv(file_name)
print(data.describe())
# 性别
data['Sex'] = data['Sex'].map({'female':0, 'male':1}).astype(int)
# 补全船票价格缺失值
if len(data.Fare[data.Fare.isnull()]) > 0:
fare = np.zeros(3)
for f in range(0, 3):
fare[f] = data[data.Pclass == f + 1]['Fare'].dropna().median()
for f in range(0, 3):
data.loc[(data.Fare.isnull()) & (data.Pclass == f + 1), 'Fare'] = fare[f]
# 年龄:使用均值代替缺失值
if is_train:
# 年龄:使用随机森林预测年龄缺失值
print('随机森林预测年龄缺失1: --start--')
data_for_age = data[['Age', 'Survived', 'Fare', 'Parch', 'SibSp', 'Pclass']]
age_exist = data_for_age.loc[(data.Age.notnull())] # 年龄不缺失的数据
age_null = data_for_age.loc[(data.Age.isnull())] # 年龄缺失的数据
x = age_exist.values[:, 1:]
y = age_exist.values[:, 0]
rfr = RandomForestRegressor(n_estimators=1000)
rfr.fit(x, y)
age_hat = rfr.predict(age_null.values[:, 1:])
data.loc[(data.Age.isnull()), 'Age'] = age_hat
print('随机森林预测缺失年龄1:--over--')
else:
print('随机森林预测缺失年龄2:--start--')
data_for_age = data[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
age_exist = data_for_age.loc[(data.Age.notnull())] # 年龄不缺失的数据
age_null = data_for_age.loc[(data.Age.isnull())]
# print age_exist
x = age_exist.values[:, 1:]
y = age_exist.values[:, 0]
rfr = RandomForestRegressor(n_estimators=1000)
rfr.fit(x, y)
age_hat = rfr.predict(age_null.values[:, 1:])
# print age_hat
data.loc[(data.Age.isnull()), 'Age'] = age_hat
print('随机森林预测缺失年龄2:--over--')
# 起始城市
data.loc[(data.Embarked.isnull()), 'Embarked'] = 'S' # 保留缺失出发城市
embarked_data = pd.get_dummies(data.Embarked)
embarked_data = embarked_data.rename(columns=lambda x : 'Embarked_' + str(x))
data = pd.concat([data, embarked_data], axis=1)
print(data.describe())
data.to_csv('New_data.csv')
x = data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y = None
if 'Survived' in data:
y = data['Survived']
x = np.array(x)
y = np.array(y)
x = np.tile(x, (5, 1))
y = np.tile(y, (5, ))
if is_train:
return x, y
return x, data['PassengerId']
def write_result(c, c_type):
file_name = '12.Titanic.test.csv'
x, passenger_id = load_data(file_name, False)
if type == 3:
x = xgb.DMatrix(x)
y = c.predict()
y[y > 0.5] = 1
y[~ (y > 0.5)] = 0
predicitions_file = open("Prediction_%d.csv" % c_type, 'wb')
open_file_object = csv.writer(predicitions_file)
open_file_object.writerow(predicitions_file)
open_file_object.writerows(zip(passenger_id, y))
predicitions_file.close()
if __name__ == "__main__":
x, y = load_data('12.Titanic.train.csv', True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.5, random_state=1)
lr = LogisticRegression(penalty='l2')
lr.fit(x_train, y_train)
y_hat = lr.predict(x_test)
lr_rate = show_accuracy(y_hat, y_test, 'Logistict回归')
rfc = RandomForestClassifier(n_estimators=100)
rfc.fit(x_train, y_train)
y_hat = rfc.predict(x_test)
rfc_rate = show_accuracy(y_hat, y_test, '随机森林')
data_train = xgb.DMatrix(x_train, label=y_train)
data_test = xgb.DMatrix(x_test, label=y_test)
watch_list = [(data_test, 'eval'), (data_train, 'train')]
param = {'max_depth':8, 'eta':0.6, 'silent':1, 'objective':'binary:logistic'}
bst = xgb.train(param, data_train, num_boost_round=100, evals=watch_list)
y_hat = bst.predict(data_test)
y_hat[y_hat > 0.5] = 1
y_hat[~ (y_hat > 0.5)] = 0
xgb_rate = show_accuracy(y_hat, y_test, 'XGBoost')
print('Logistic回归:%.3f%%' % lr_rate)
print('随机森林:%.3f%%' % rfc_rate)
print('XGBoost:%.3f%%' % xgb_rate)
Adaboost
非sklearn
import numpy as np
import matplotlib.pyplot as plt
def loadSimpData():
"""
创建单层决策树的数据集
Parameters:
无
Returns:
dataMat - 数据矩阵
classLabels - 数据标签
"""
datMat = np.matrix([[ 1. , 2.1],
[ 1.5, 1.6],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def showDataSet(dataMat, labelMat):
"""
数据可视化
Parameters:
dataMat - 数据矩阵
labelMat - 数据标签
Returns:
无
"""
data_plus = [] #正样本
data_minus = [] #负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #转换为numpy矩阵
data_minus_np = np.array(data_minus) #转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #负样本散点图
plt.show()
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
"""
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小于阈值,则赋值为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大于阈值,则赋值为-1
return retArray
def buildStump(dataArr,classLabels,D):
"""
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClasEst - 最佳的分类结果
"""
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = float('inf') #最小误差初始化为正无穷大
for i in range(n): #遍历所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特征中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #计算步长
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #计算阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#计算分类结果
errArr = np.mat(np.ones((m,1))) #初始化误差矩阵
errArr[predictedVals == labelMat] = 0 #分类正确的,赋值为0
weightedError = D.T * errArr #计算误差
# print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError: #找到误差最小的分类方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
"""
使用AdaBoost算法提升弱分类器性能
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
numIt - 最大迭代次数
Returns:
weakClassArr - 训练好的分类器
aggClassEst - 类别估计累计值
"""
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m) #初始化权重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D) #构建单层决策树
# print("D:",D.T)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16))) #计算弱学习算法权重alpha,使error不等于0,因为分母不能为0
bestStump['alpha'] = alpha #存储弱学习算法权重
weakClassArr.append(bestStump) #存储单层决策树
# print("classEst: ", classEst.T)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst) #计算e的指数项
D = np.multiply(D, np.exp(expon))
D = D / D.sum() #根据样本权重公式,更新样本权重
#计算AdaBoost误差,当误差为0的时候,退出循环
aggClassEst += alpha * classEst #计算类别估计累计值
# print("aggClassEst: ", aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m,1))) #计算误差
errorRate = aggErrors.sum() / m
# print("total error: ", errorRate)
if errorRate == 0.0: break #误差为0,退出循环
return weakClassArr, aggClassEst
def adaClassify(datToClass,classifierArr):
"""
AdaBoost分类函数
Parameters:
datToClass - 待分类样例
classifierArr - 训练好的分类器
Returns:
分类结果
"""
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)): #遍历所有分类器,进行分类
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
print(aggClassEst)
return np.sign(aggClassEst)
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, classLabels)
print(adaClassify([[0,0],[5,5]], weakClassArr))


















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









