




 本文深入解析希尔排序算法,探讨其作为插入排序的一种改进形式的基本思想、方法思路及算法实现过程。希尔排序通过预先分割序列并进行初步排序,再进行整体排序,有效提升了排序效率。
本文深入解析希尔排序算法,探讨其作为插入排序的一种改进形式的基本思想、方法思路及算法实现过程。希尔排序通过预先分割序列并进行初步排序,再进行整体排序,有效提升了排序效率。
希尔排序
希尔排序是插入排序的一种
直接插入排序在基本有序时或待排序的记录个数较少时效率较高,且比较一次,移动一步。
希尔排序基本思想:
先将整个待排记录序列分割成若干自序列,分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
方法思路:
- 定义增量序列 Dk:Dm > Dm-1 > … >D1=1
- 对每个 Dk 进行插入排序
特点:
- 一次移动,移动位置较大,跳跃式地接近排序后的最终位置
- 最后一次只需少量移动
- 增量序列必须是递减的,最后一个必须是1
- 增量序列应该是互质的
图示:
每次移动步数很大,使接近最终位置
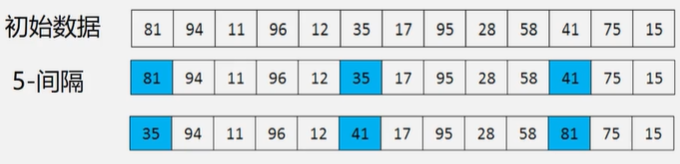
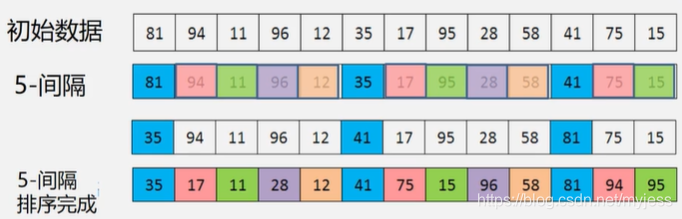
再重新划分间隔:

再进行整体的排序即1间隔:

算法实现:
//排序用的顺序表
#define MAXSIZE 100
typedef struct
{
int r[MAXSIZE + 1];
int length; //顺序表的长度
}Sqlist;
void ShellSort(Sqlist &L,int dt[],int t)
{
//按增量序列dt[0...t-1]对顺序表 L 作希尔排序
// dk的值即增量序列依次存储在dt[]中
int k;
for(k = 0;k < t;k++)
{
ShellInsert(L,dt[k]); //一趟增量为dt[k]的插入排序
}
}
//其中某一趟的排序操作
void ShellInsert(Sqlist &L,int dk)
{
//dk为步长
int i,j;
for(i = dk+1;i < L.length;i++)
{
if(L.r[i] < L.r[i-dk])
{
L.r[0] = L.r[i];
for(j = i-dk;j > 0 && (L.r[0] < L.r[j]);j = j-dk)
{
L.r[j+dk] = L.r[j];
}
L.r[j+dk] = L.r[0];
}
}
}

















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









