



项目使用的框架,数据库
开发语言用的是java,框架是springBoot,后管理系统使用的的是Layui框架,涉及html,css,javascripse,js,等。
mysql索引有哪些,有什么区别,什么作用,哪些情况会使索引失效,所以如果失效了怎么处理。
索引就是键,索引的存在可以简化查询,是用于快速查找记录的一种数据结构,当数据量大的的时候索引的效果就越重要。
索引分类:
(1)普通索引`index`
(2)唯一索引分 主键索引`primary key `
(3)唯一索引`unique`
(4)联合索引
(5)全文索引
(6)空间索引。
导致索引失效原因:
(1)like 操作符的使用不当
(2)or语句的使用
(3)在索引列上使用函数或计算
(4)使用不等于操作符
(5)is null 和 is not null
(6)数据类型隐式转换
(7)组合索引的使用不当
(8)全表扫描速度比索引速度快时。
哪知道了这些原因会使索引失效,那就在查询的时候避免出现这些会索引失效的用法,就可以解决索引失效了(夸夸自己真是个小机灵鬼~,此处应该有掌声,哈哈哈哈哈~)
注:常用的索引三种index、primery key、unique。
共同的特点:
字段值的都使唯一不可重复的。
常使用的区别:
ndex可以设置多个字段为index并且多个index字段之间没有关系,primery key本身就叫主键索引所以主键主键特点在于`主`也就是唯一,一个表中有且只有一个字段可以被设置primery key。unique叫唯一他的特点使限制字段值,所以unique也可以设置多个字段为unique,并且既可以单独设置某个字段值的唯一也可以设置多个字段联合约束值的唯一
MySQL 引擎有哪些,什么作用,区别是什么。
常用的两种引擎InnoDB和MyIsam,MyIsam曾经是MySQL的默认引擎,它不支持事务但是提供了全文索引和表锁结构(当事务操作某个数据表的时候在事务没有结束之前被操作的表是被锁住不能进行其他事务的操作)。 InnoDB是MySQL现在默认的事务型引擎,也是使用最广泛的存储引擎,它提供了事物安全,行锁(在事务操作某个数据表的时候在事务没有结束之前只对对应正在操作事务的行进行锁的操作,对其他行不受影星)和外键约束功能。
Spring,Spring Boot,Spring Could 框架,有什么区别
StringBoot框架可以是说是ssm框架的升级,ssm框架包括Spring框架,StringBoot框架简化了bean.xml文件的编写,通过注解的方式简化了Spring框架
SpringBoot 常用的注解有 哪些,什么作用,作用原 理是什么
SpringBoot常用的注解SpringBoot 注解-优快云博客
依赖注入:@Autowired
控制器:@Controller
业务层:@Service
数据访问层(持久层):@Dao
请求映射:@RequestMapping
响应机构:@ResponseBody
映射器:@Mapper
重写、重载 :@Override
前端发起请求之后首先通过 请求映射 的接口找到对应的 业务层 在向下找到对应的方法,在业务层里做了一个 依赖注入 用于注入我们写好的请求映射需要的动作 业务层 ,在业务层动作处理中有些事需要进行对持久层进行增删改查的操作就可以 再 导入对应的 持久层 进行调用,在持久层里框架做了映射关系的处理,通过注解映射方法找到配置文件对应的数据库操作命令并进行处理,然后在逐步返回数据 响应(响应机构)到前端进行前端数据的渲染。
inner join ,left join, right join查询数据结果的不同
1、left join (左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
2、right join (右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
3、inner join (等值连接或者叫内连接):只返回两个表中连接字段相等的行。
表连接首先是查询语法,查询的结果是根据on条件进行筛选
左连接:是指左表是主表,右表是副标。用主表的每条数据根据on条件查询副标的每条数据数据,在副标中有符合on条件的数据,那么就会将主表的查询字段加上副标这条符合数据的查询字段作为一条新的数据查询出来,如果查询之后副标中没有满足on条件的数据,那么主表的查询字段依然可以查询出来对应查询的有表字段值这是null然后作为一条数据查询出来
右连接:指右表是主表,左表是副标。查询顺序和原理和左连接一样
内连接:是指查询两个表共同满足on条件的数据每条数据的查询字段分别拼接为新的数据作为查询结果导出
项目缓存怎么处理的
使用redis缓存
rides 缓存有哪些数据类型,长使用的数据类型有哪些
rides缓存总共有八种,常用的五大数据类型:String、list、set、hash、zset
都那些情况需要使用到缓存
(1)用户登录之后信息和token有效期
数据库连接使用的那种方式
数据库连接在代码上区别有两种,一种是JDBC编写配置类连接,第二种是通过编写配置文件连接连接,因为要连接数据库所以无论是配置类还是配置文件的方式,首先都需要数据库驱动,然后通过主机ID、端口号(mysql默认是3306)、数据库名称、用户名、用户密码
配置文件配置:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url:jdbc:mysql://124.0.0.01:3306/jingcheng_testuseUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123
//用户名:username: root
//用户密码:password: 123
//
//主机ID:124.0.0.01
//
//端口号:3306
//
//数据库名称:jingcheng_test
//
//编码:useUnicode=true&characterEncoding=utf8
//
//不用通过证书或者令牌进行安全验证:useSSL=false
//
//时区设置:serverTimezone=GMT%2B8JDBC代码连接:第一个JDBC程序 | FrogInTheWell
java数据类型有哪些
java数据类型分为`基本数据类型`和`引用数据类型`
基本数据类型:
1.整型
byte (字节型)、short (短整型)、int(整型) 、long(长整型)
2.浮点型
float(单精度) 、 double(双精度)
3.字符型
char
4.布尔型
boolean
引用数据类型:常见的引用数据类型有:类、接口、数组、枚举等。String类就是引用数据类型
String、StringBuffer、StringBuilder 之间的关系和区别
首先String字符串的值是不可以被改变,final类,代表不可变的字符序列 ,当你创建了一个String对象 (在栈里)也就相当于创建了一个指针,但是目前这个指针没有指向,但是当你给这个对象赋值的时候,首先是在堆里创建了一个地址存放"xiaoming",然后又将name这个指针指向指向存放"xiaoming"得地址,以此类推,当我们去改变name这个字符串值得时候本质上是修改得地址指向,没修改一次就会创建一个地址,所以说String的值是不可以被修改的。
String name = new String();
name = "xiaoMing";
StringBuilder也是被final类不可被继承,不可变字符序列,他和StringBuffer的区别是StringBuffer被Serializable修饰但是StringBuilder没有,所以在单线程操作下,StringBuilder类的操作数据的效率应该比StringBuffer高,因为StringBuffer类型数据被加了一次线程控制的保护操作。
所以说,一般在单线程操作下,StringBuilder、StringBuffer和String类型数据的操作效率是:
StringBuilder>StringBuffer>String
mysql 外键的使用
Hoodpoop
子类和父类的关系
子类可以继承父类的所有非私有(private 私有的)属性和方法这些被继承的方法也可以被重写(也可以说事覆盖)被重写的方法只对子类有效,会父类没有影响。子类可以添加父类所没有(扩展)的属性和方法。子类对象可以赋值给父类引用变量,这称为向上转型(多态)。一个类只能继承一个父类(单继承),但是允许多级继承实现。
== 和 equals,两者判断的时候是否相同,有什么区别
==比较的是两个对象的地址,当地址指向是一个地址的时候判断两个对象相等。
equals比较的是哈希值是否相等,比如1=1数值相等则判断两个对象相等。
数据库的三大泛式
第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列)
第二范式(2NF):满足第一范式;且不存在部分依赖,即非主属性必须完全依赖于主属性。(主属性即主键;完全依赖是针对于联合主键的情况,非主键列不能只依赖于主键的一部分)
第三范式(3NF):满足第二范式;且不存在传递依赖,即非主属性不能与非主属性之间有依赖关系,非主属性必须直接依赖于主属性,不能间接依赖主属性。(A -> B, B ->C, A -> C)
微信支付之后怎么对账
数据库ACID
数据库的ACID也是事务的特点:
① 原子性:事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用。
② 一致性: 确保从一个正确的状态转换到另外一个正确的状态,这就是一致性;
③ 隔离性:并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
④ 持久性:一个事务被提交之后,对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
数据库的隔离
由低到高分:
1.读未提交 (Read uncommitted)
顾名思义就是可以读取还没有提交的数据,比如说有两个事务a(读),b(写)。a事务先于b,当b事务处理但是还没有提交的时候说明b事务不一定成功有可能失败,这条数据写操作是失败的,正长情况下会根据事务的概念要么全成功要么全部成功,那么事务b显然是不成功的,但是同事事务a有读取了这个还未成功的数据,就会导致“脏读”
2.读提交(Read Committed)
3.可重复读(Repeated Read)
4.序列化 Serializable
并发事务中的问题 脏读,脏写,不可重复读,幻读
脏读:指当一个事务正在访问数据,并且对数据进行了修改,而这种数据还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据还没有提交那么另外一个事务读取到的这个数据我们称之为脏数据。依据脏数据所做的操作肯能是不正确的。
不可重复读:指在一个事务内,多次读同一数据。在这个事务还没有执行结束,另外一个事务也访问该同一数据,那么在第一个事务中的两次读取数据之间,由于第二个事务的修改第一个事务两次读到的数据可能是不一样的,这样就发生了在一个事物内两次连续读到的数据是不一样的,这种情况被称为是不可重复读。
幻象读:一个事务先后读取一个范围的记录,但两次读取的纪录数不同,我们称之为幻象读(两次执行同一条 select 语句会出现不同的结果,第二次读会增加一数据行,并没有说这两次执行是在同一个事务中)
什么是MQ消息队列
数据库事务
事务是逻辑上的一组数据库操作,要么都执行,要么都不执行。
存储过程
(PROCEDURE)是事先经过编译并存储在数据库中的一段SQL语句的集合。调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是很有好处的。
队列和栈
进出:栈先进后出,队列是先进先出
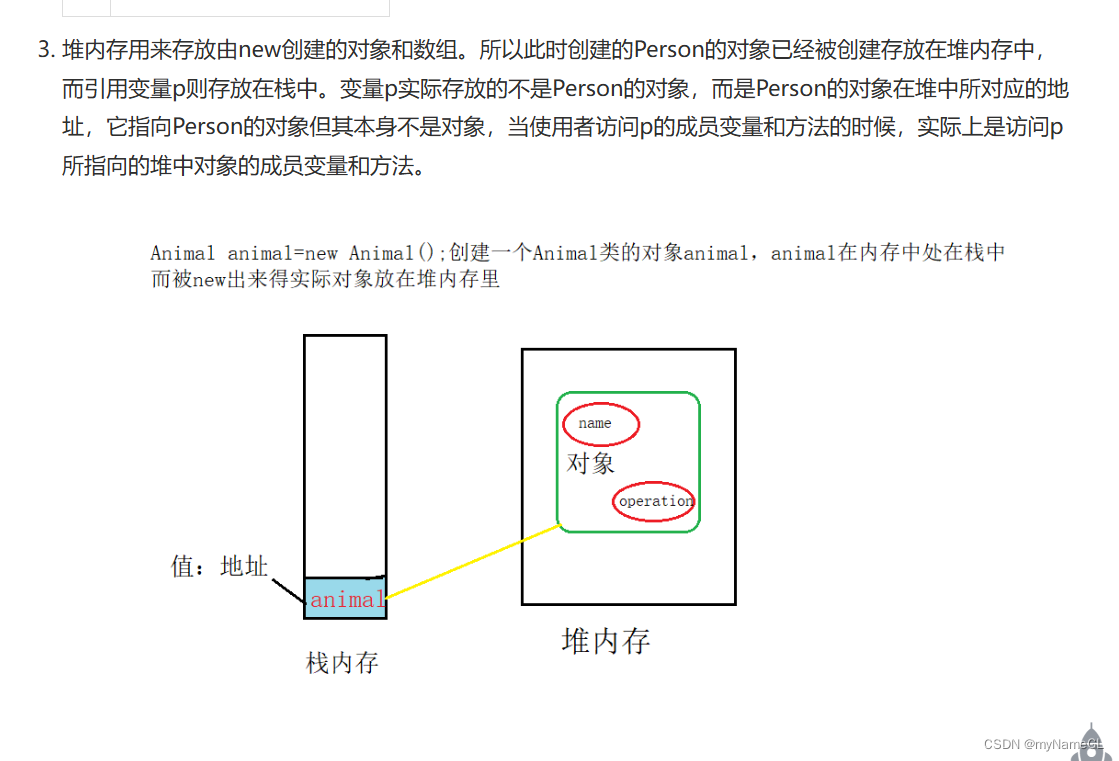
栈和堆
栈由操作系统自动分配释放 ,用于存放函数的参数值、局部变量等,其操作方式类似于数据结构中的栈。
堆由开发人员分配和释放, 若开发人员不释放,程序结束时由 OS 回收,分配方式类似于链表
什么是SQL优化
SQL优化就是优化SQL语句,让其处理数据的效率更高,更快。
定时任务是通过什么方式做的,在分布式系统中,怎么控制定时任务的合理调用
定时任务通过

















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









