




 本文介绍了分组卷积的概念,它通过将输入数据按深度分成多个组,每组使用独立的卷积核进行卷积运算,从而减少参数数量,降低了对存储器容量的需求。分组卷积保持了输出通道数,但每个卷积核的深度减小,实现了并行计算,提高了计算效率。
本文介绍了分组卷积的概念,它通过将输入数据按深度分成多个组,每组使用独立的卷积核进行卷积运算,从而减少参数数量,降低了对存储器容量的需求。分组卷积保持了输出通道数,但每个卷积核的深度减小,实现了并行计算,提高了计算效率。
首先讲解卷积
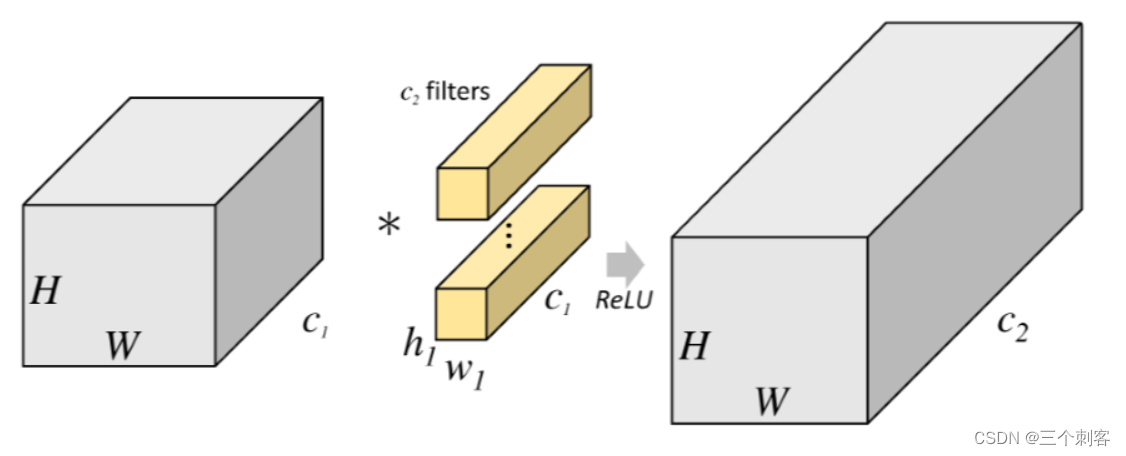
从上图可以看出,一般的卷积会对输入数据的整体一起做卷积操作,即输入数据:H1xW1xC1,而卷积核大小h1xw1,通道为c1,一共有c2个,然后卷积得到的输出数据就是H2xW2xC2,这里我们假设输入和输出的分辨率是不变的,这对存储器的容量提出了明显的要求。但是分组卷积就没有那么多的参数 。对于上面所说的同一个参数,分组卷积如下图所示,
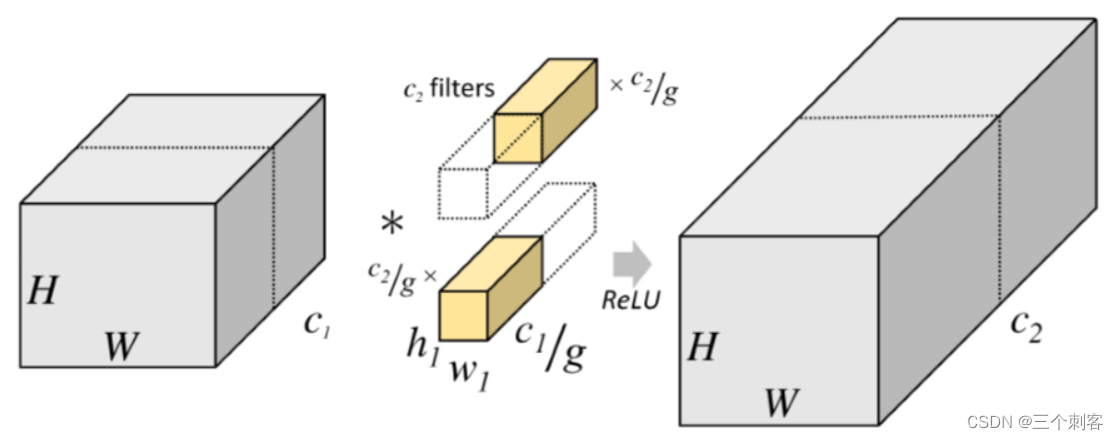
可以看出,图中将输入数据分成了2组(组数为g),需要注意的是这种分组只是在深度上进行划分,即某几个通道编为一组,这个具体的数量由C1/g决定,因为输出数据的改变,卷积核的数量也要跟着改变。即每组卷积核的深度变为C1/g,而每组卷积核的大小是不需要跟着改变的,此时每组卷积核的个数变成C2/g,而不是原来的C2了。然后用每组的卷积核同他们对应组内的输入数据卷积,得到了输出数据后,再用concatenate的方式组合起来,最终的输出数据的通道还是C2。也就是说分组数g确定后,我们将并行的运算g个相同的卷积过程,每个过程里,输入数据为H1xW1xC1/g,卷积核大小h1xw1xC1/g,一共有C2/g个,输出数据H2xW2xC2/g。
参考:https://blog.youkuaiyun.com/shentu7/article/details/105574369

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









