







 本文深入解读Kafka,阐述其作为分布式消息系统的特性,如持久化、高吞吐和容错性,介绍消息在Broker、Topic、Partition和Replication中的工作原理,以及数据存储的Offset和索引机制。重点讲解了如何通过Zookeeper实现高可用的双层选举机制。
本文深入解读Kafka,阐述其作为分布式消息系统的特性,如持久化、高吞吐和容错性,介绍消息在Broker、Topic、Partition和Replication中的工作原理,以及数据存储的Offset和索引机制。重点讲解了如何通过Zookeeper实现高可用的双层选举机制。
Kafka简介
Kafka是一个基于发布/订阅的分布式消息系统。
可以理解成一个小存储,我们可以往上发东西,回头会有人去那里读出来。
特性
- 消息持久化:采用时间复杂度O(1)的磁盘存储结构,即使TB级以上数据也能保证常数时间的访问速度
- 高吞吐:即使在廉价的商用机器上,也能达到单机每秒10万条消息的传输
- 高容错:多分区多副本
- 易扩展:新增机器,集群无需停机,自动感知
- 同时支持实时和离线数据处理(更多用在实时)
原理
基本概念
角色:
- Broker(代理)
Kafka的一个实例或节点,一个或多个Broker组成Kafka集群 - Topic(主题)
Topic是Kafka中同一类数据的集合(贴同一标签),相当于数据库中的表;Producer将同一类数据写入同一个Topic,Consumer从同一个Topic中读取同类数据;Topic是逻辑概念,只需指定Topic就可以生产或消费数据,不必关心数据的物理存储 - Partition(分区)
- 分区是一个有序的、不可修改的消息队列,分区内消息有序存储;
- 一个Topic可分为多个分区,相当于把一个数据集分成多份,分别存储不同的分区中
- Parition是物理概念,每个分区对应一个文件夹,存储分区的数据和索引文件
- Replication(副本)
一个分区可以设置多个副本,副本存储在不同的Broker中 - Producer(消息生产者)
- Consumer(消息消费者)
- Consumer Group(CG,消费者组)
使用组的好处就是组内互斥:一个CG中只能有一个Consumer可以读取该消息;组间共享:对于Topic中的某一消息,不同的CG可以重复读取该消息 - Zookeeper
Kafka将主要的元数据保存在Zookeeper中,ZooKeeper也负责Kafka集群管理,包括配置管理、动态扩展、Broker负载均衡、Leader选举等
工作机制
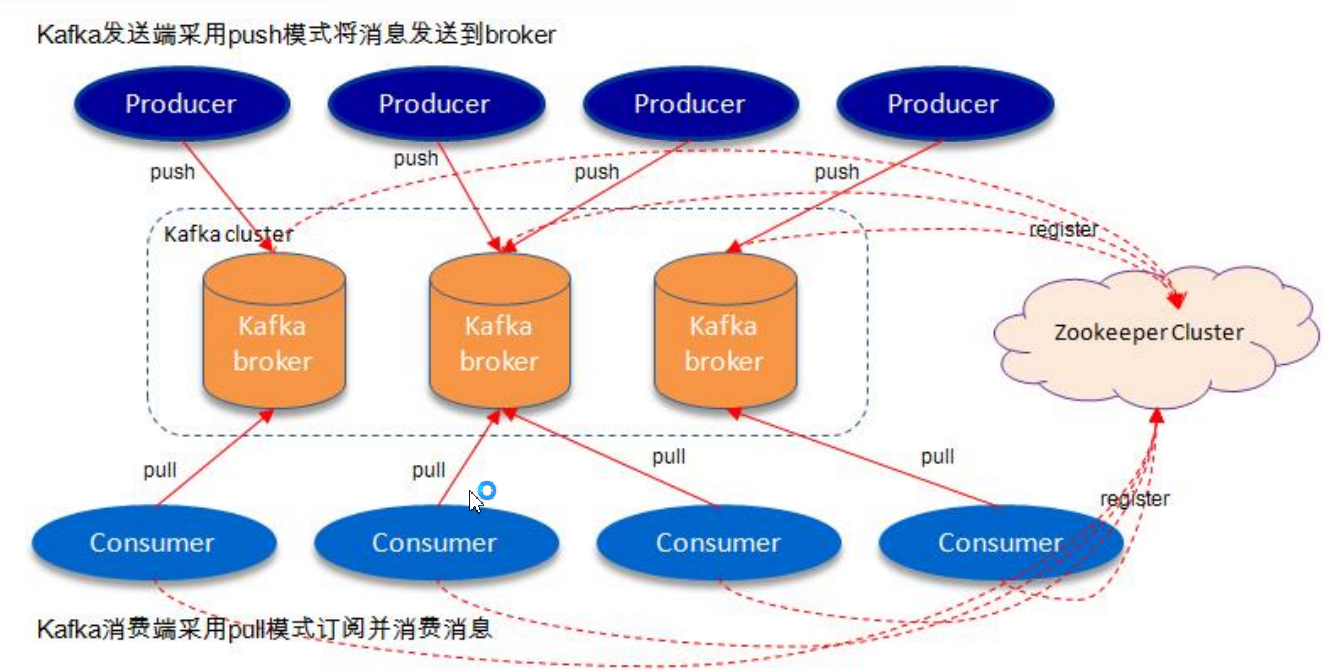
消息在Broker中按Topic(主题)进行分类,相当于为每个消息打个标签。一个Topic可分为多个Partition(分区),每个Partition可以有多个Replication(副本),消息存储在Broker的某一Topic的某一Partition中,同时存在多个副本。
Partition是一个FIFO队列, 发布消息采用在队列尾部追加的方式,消费消息采用在队列头部顺序读取的方式。一个Topic可分为多个Partition,仅保证同一分区内消息有序存储,不保证Topic整体(多个分区之间)有序。
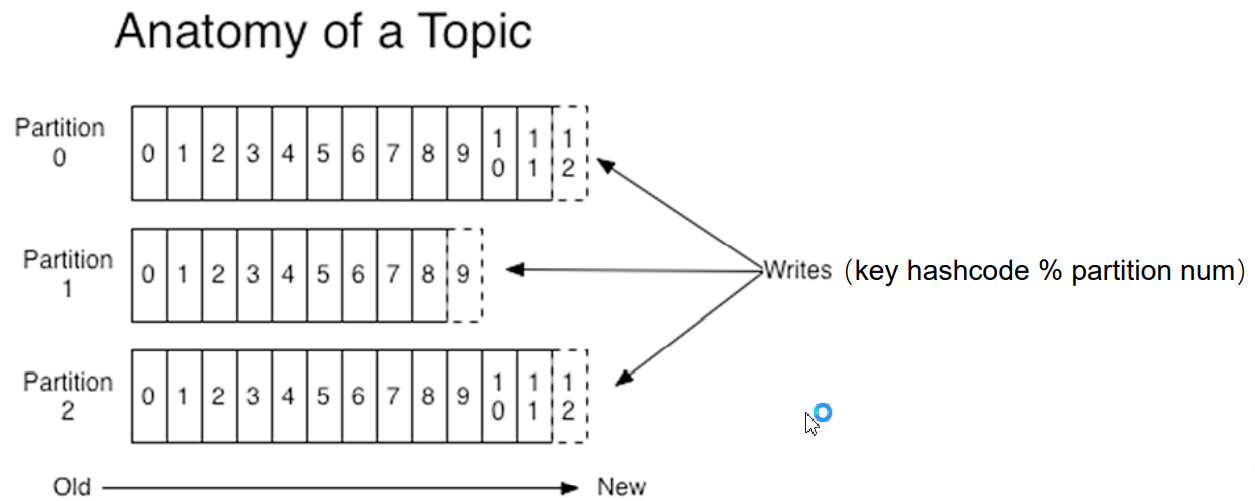
为了加快读取速度,多个Consumer可划分为一个组(Consumer Group, CG),并行消费同一个Topic。
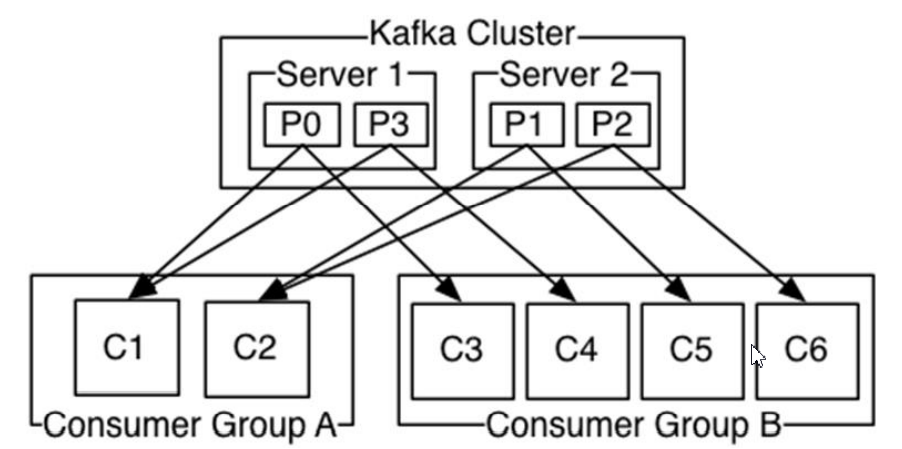
一个Topic可以被多个CG订阅,CG之间是平等的,即一个消息可同时被多个CG消费
一个CG可以有多个Consumer,CG中的Consumer之间是竞争关系,即一个消息在一个CG中只能被一个Consumer消费
数据存储
文件
每个Partition副本都是一个目录,目录中包含若干Segment文件(段文件,Kafka的最小数据存储单元)
Segment文件由以消息在Partition中的起始偏移量命名的数据文件( .log)和索引文件 . index、 .timeindex)组成。
offset
采用**Offset(偏移量)**是定位分区中消息的顺序编号,用于在分区中唯一标识消息。推荐由Kafka(不推荐采用Zookeeper,效率会受到影响)来存储和维护Offset,即在Broker中记录和重置每个Comsumer读取分区消息的偏移量。
索引
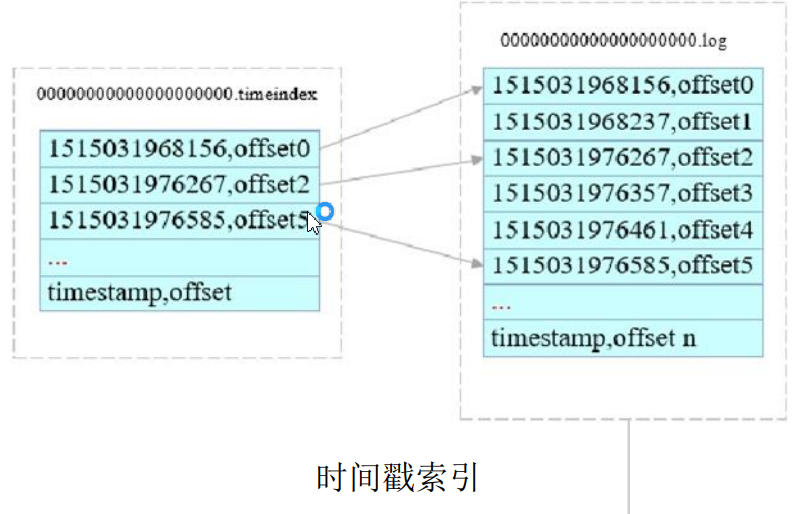
为了提高消息写入和查询速度,为每个Partition创建索引,索引文件存储在Partition文件夹下。
分为偏移量索引和时间戳索引。
偏移量索引件以offset偏移量为名称,以index为后缀,数据格式为:<offset, position>。采用稀疏存储方式,二分法访问index,查找在log里面的位置。
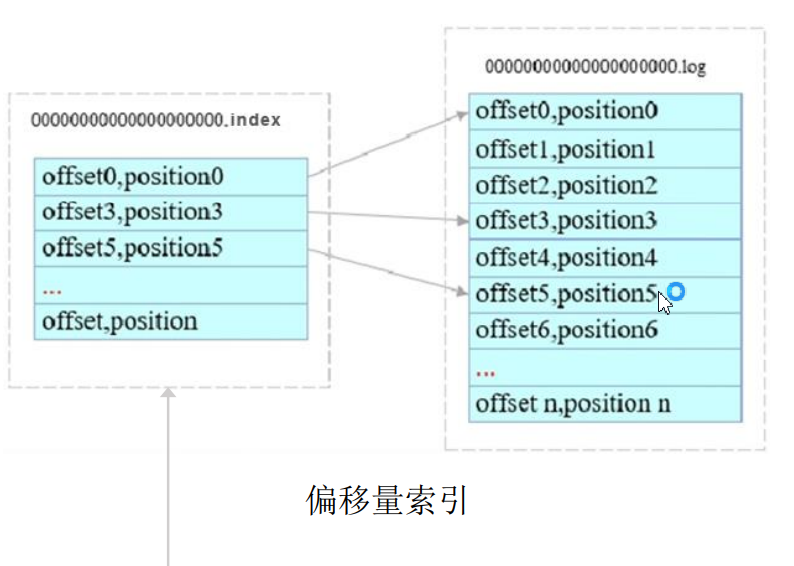
时间戳索引文件以timeindex为后缀,数据格式:<timestamp, offset>
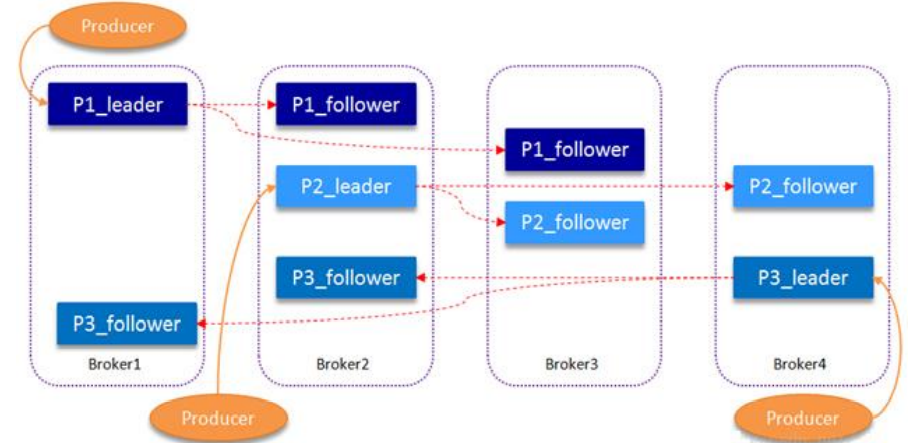
高可用
从一个分区的多个副本中选举一个Partition Leader,由Leader负责读写,其他副本作为Follower从Leader同步消息。
双层选举
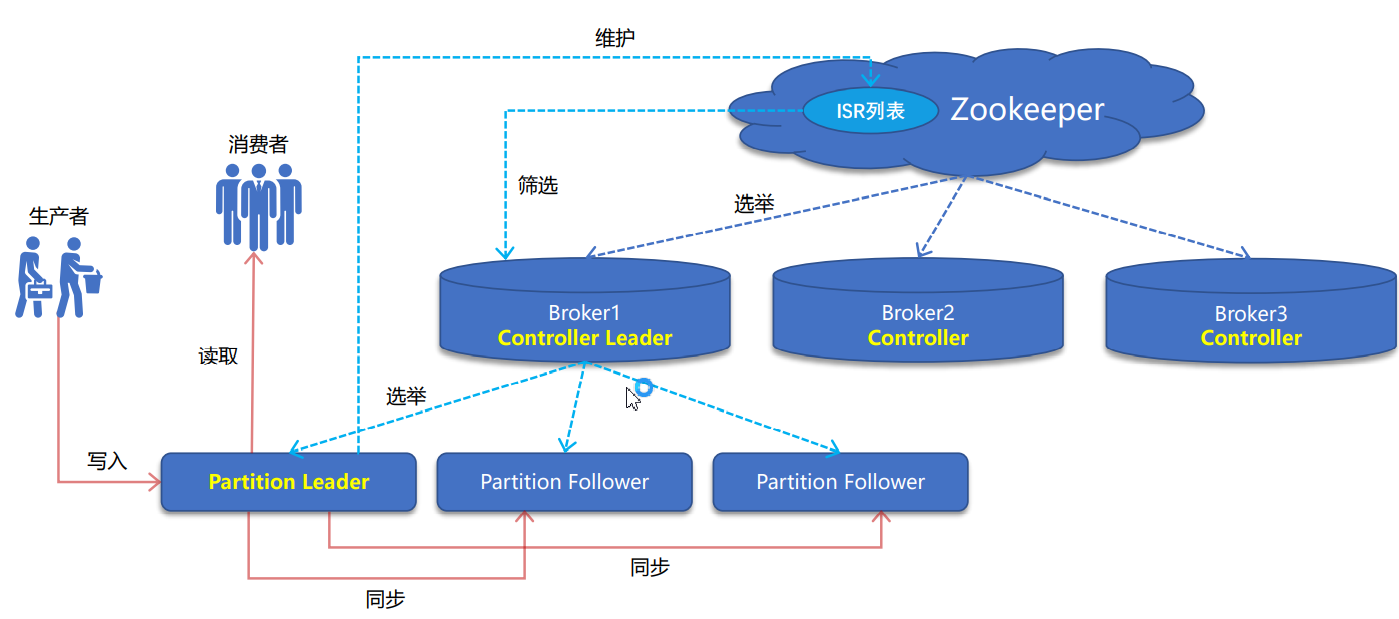
Controller Leader选举:
每个Broker启动时都会创建一个Controller进程,通过Zookeeper,从Kafka集群中选举出一个Broker作为Controller LeaderController Leader负责管理分区和副本状态,避免分区副本直接在Zookeeper上注册Watcher和竞争创建临时Znode,导致Zookeeper集群负载过重.
Partition Leader选举:
Controller Leader负责Partition Leader的选举。在ZooKeeper上维护一个ISR列表(In Sync Replica,候选分区副本同步列表)。ISR列表负责保存候选分区副本(Partition Follower)的状态信息,Partition Leader负责跟踪和维护ISR,定期从Leader同步数据,若Follower心跳超时或消息落后太多,将被移除出ISR。
Partition Leader挂掉后,Controller Leader从ISR中选择一个Follower作为新的Leader。
参考
课程内容来自:南京大学+星环科技课程,大数据大数据理论与实践课程

















 5714
5714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









