




 本文介绍了一个Python脚本的调试过程,该脚本用于根据表格内容和流量包进行流量包的切分。文章详细记录了从无法运行到解决各种问题,最终实现正确输出的全过程。
本文介绍了一个Python脚本的调试过程,该脚本用于根据表格内容和流量包进行流量包的切分。文章详细记录了从无法运行到解决各种问题,最终实现正确输出的全过程。
Python脚本debug 切包
过程总结:
拿到了脚本,发现无法运行输出内容,说明也写的非常模糊,脚本要实现的功能是根据一个对应的表格内容和流量包,对流量包进行切分,分为各个漏洞的对应的包
开始debug
1、梳理各部分函数功能与内容
主函数:
 分析:
分析:
Pcap_dir = sys.argv[1]
sys.argv[]:读取运行时命令行输入的参数
命令行输入时可以输入一个文件夹或者一个pcap结尾的流量包,输入文件夹时会寻找文件夹中的pcap结尾的流量包,然后一个个遍历,进行read函数的操作,如果输入单个包,直接进行read
read函数:


read函数是主要功能,将表格和流量包的内容生成字典,key为Ip流
然后进行write
write函数:
 生成一个pcap包名+_ip的文件夹,如果已经存在就删除(shutil.rmtree),里面存放切好的包
生成一个pcap包名+_ip的文件夹,如果已经存在就删除(shutil.rmtree),里面存放切好的包
判断两个字典是否有交集,如果有,以漏洞名为包名输出,循环
2、出现的问题解决
1、无输出内容
经过在各个函数部分进行print输出操作后,发现是两个字典没有交集,然后将代码改成了

此时有了输出,但是包里的IP与表格是无法对应的,经群里大佬指点,才理解这是对字典的交集判断,而不是普通的判断循环。接下来就尝试输出了字典的Key,发现Ip对应不上,查找read函数中关于key和Ip的定义
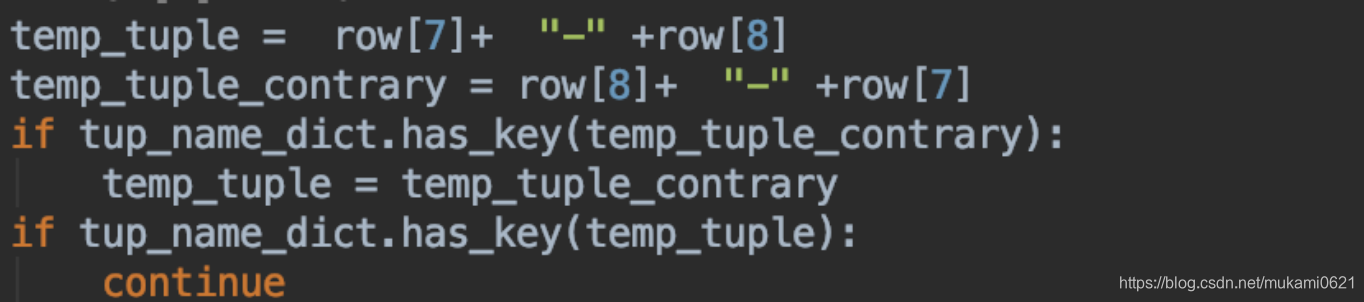
row[7]和row[8]并不是表格中对应的Ip值,统一改成row[8]和row[9]后成功输出
2、输出的包数和表格内漏洞的数量对应不上
经过大致浏览表格中的名称,发现有重复名称,经过输出字典内容查看,发现字典中由于key不同,是可以存在同一个名称的漏洞内容,所以问题是出在输出文件时,由于名字重复所以会有覆盖的情况

进行更改。在此之前,有另一个想法是在生成表格字典时,对表格先进行处理,如对重复的文件进行重命名,然后尝试了一堆操作,可以成功更改并输出,但是由于表格列数众多,最后选择直接改输出的函数
 进行修改,但是输出包时数量还是有误,经判断发现表格里有重复三四次名称的文件,这样修改依旧不能全部输出,最后改为如下:
进行修改,但是输出包时数量还是有误,经判断发现表格里有重复三四次名称的文件,这样修改依旧不能全部输出,最后改为如下:
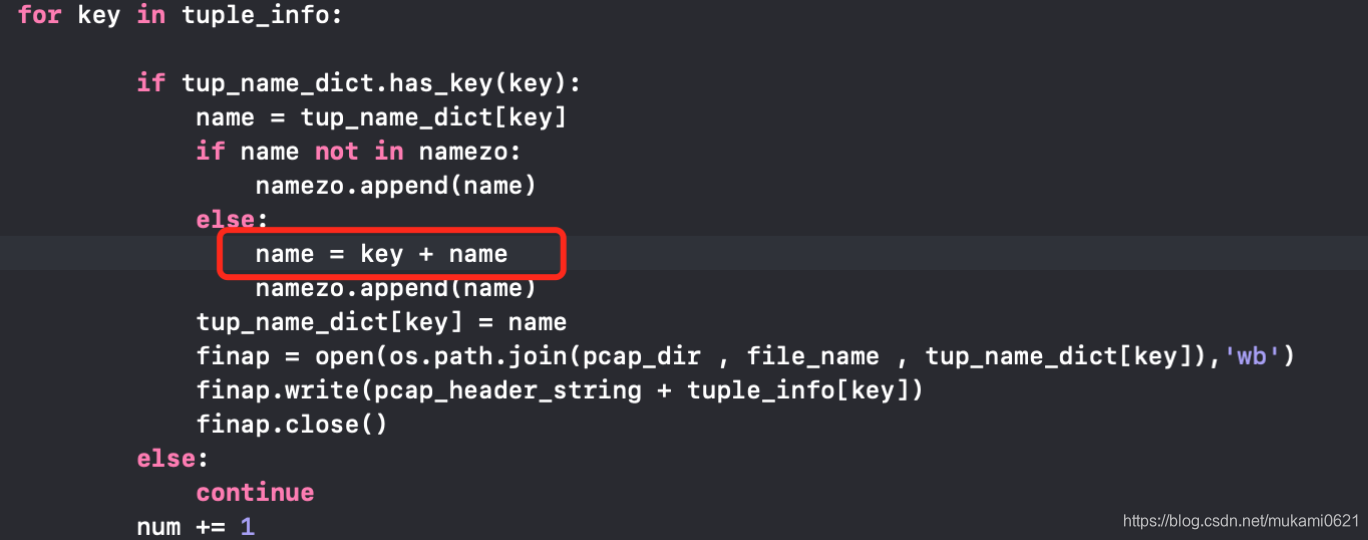
但是此时仍然数量对应不上,由于给的例子数量众多(1500),先进行了少量筛选,找到一个没有输出的包,然后删除大部分数据,留存了一个没有输出的包和两个重复名称和两个正常输出的包进行试验。对这些包的字典进行打印,查看key值,发现是Ip方向相反,流量包中第一个请求包的方向存在正反两个方向,只有正向的可以输出,询问需求后决定写成两个脚本,正反各运行一次然后合并,反向的只要将Ip方向对调即可
此时仍有一个数量对应不上,1500个中只输出了1499个包
将表格名称与输出的包的名称全部输入到两个txt中,文件夹中所有文件名称输出:dir /b *.pcap > 1.txt
用beyond compare进行对比,找到了没有输出的漏洞的包,在流量包中寻找对应IP,发现没有,所以脚本已经完成没有问题
将debug过程中没有必要的文件删除,在文件中重点处编写注释,并重新编写了使用说明,打包,到此完成。
脚本文件放在:https://github.com/Kamimuka/cut-pacp

















 3231
3231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









