




 本文详细描述了解决Microsoft Visual C++依赖问题,指导读者如何在Python 3.6环境中安装JPype1和PyHanLP,避免常见错误。重点在于环境配置和版本匹配。
本文详细描述了解决Microsoft Visual C++依赖问题,指导读者如何在Python 3.6环境中安装JPype1和PyHanLP,避免常见错误。重点在于环境配置和版本匹配。
折腾了好久,分享给大家,少走弯路!!!
试了好多方法,出现了这样报错,那样报错,最折腾的莫过于microsoft visual c++ 14.0 is required 的问题!!!
其实没有Microsoft Visual c++环境没有也是可以的 !!! 关键是 jpype1 和 pyhanlp 还有 python的版本要对得上!!!
这里我成功安装是采用的 Python 3.6 , 不多说,直接来操作!!!
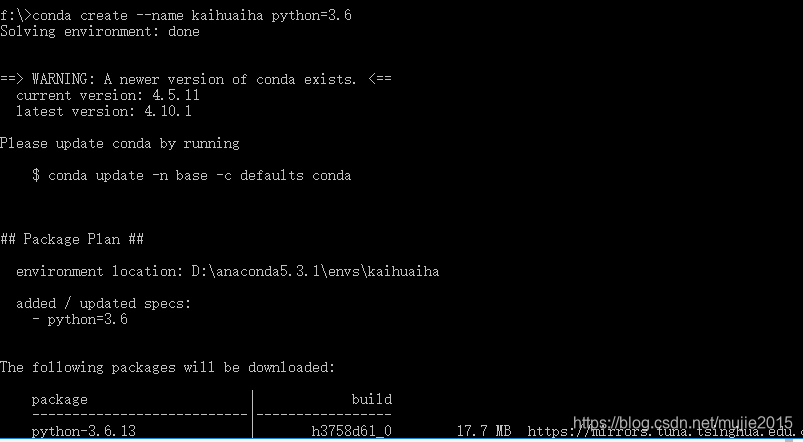
1 重新创建一个conda环境指定Python 3.6 : conda create --name kaihuaiha python=3.6
2 jpype1 下载参考:https://blog.youkuaiyun.com/qq_19741181/article/details/79414202?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162175550516780255293661%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162175550516780255293661&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-79414202.first_rank_v2_pc_rank_v29&utm_term=jpype1%E5%AE%89%E8%A3%85%E5%A4%B1%E8%B4%A5&spm=1018.2226.3001.4187
先激活工作区间:activate kaihuaiha , 再安装 pip install JPype1-1.1.2-cp36-cp36m-win_amd64.whl
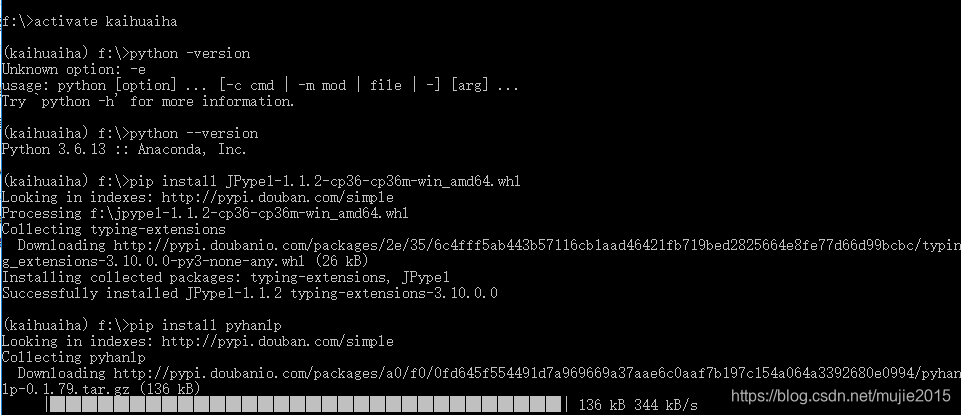
3 最后 pip install pyhanlp
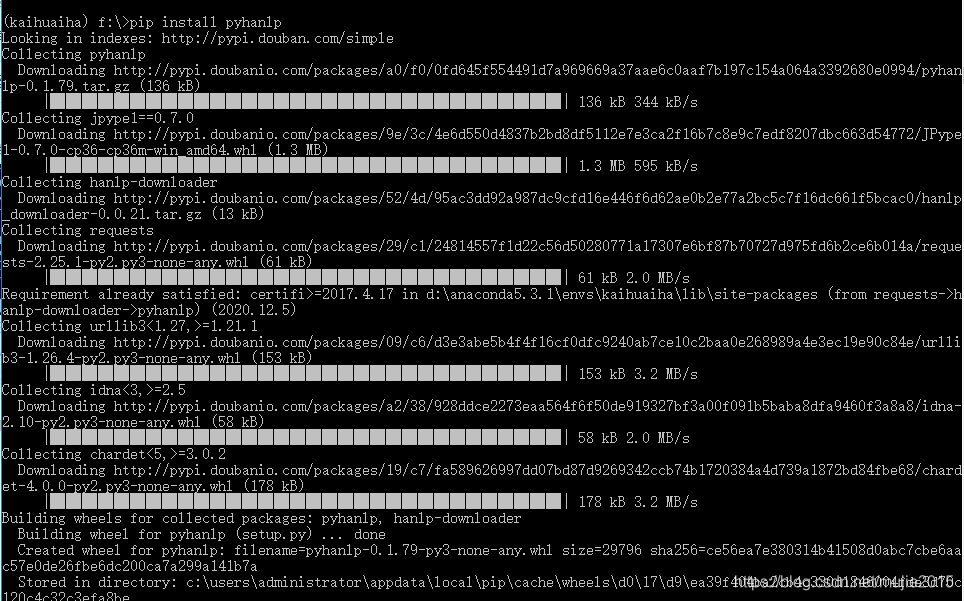
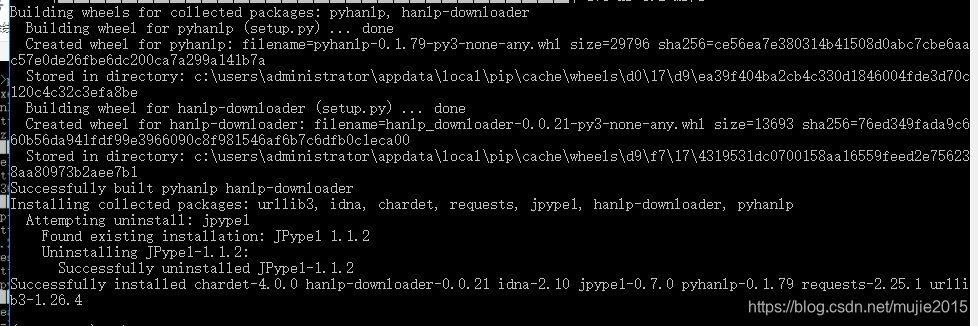
上面安装成功!
4 引用下载pyhanlp相关数据

另外附上未解决的问题:
python和Microsoft Visual C++ Build Tools的关系,还要安装c++ ,要安装证书 +包损坏下载不下来请全局翻墙!!
http://www.aobosir.com/blog/2016/11/26/download-install-Miarosoft-Visual-Studio-2015-software-tutorial/
https://zhuanlan.zhihu.com/p/355576233
https://blog.youkuaiyun.com/qq_15158911/article/details/107887490
这几种都试过,不太管用!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











