









 本文深入探讨线性回归的原理及应用,包括何时使用线性回归、基本数学模型、损失函数和最小二乘法等核心概念。同时介绍了如何通过计算自变量和因变量之间的皮尔逊系数来评估线性关系的强度。
本文深入探讨线性回归的原理及应用,包括何时使用线性回归、基本数学模型、损失函数和最小二乘法等核心概念。同时介绍了如何通过计算自变量和因变量之间的皮尔逊系数来评估线性关系的强度。
线性回归描述
线性回归的实质是通过一个线性函数能够较好的描述所给的数据特征。例如,下图所给的数据,通过房子的大小来预测房子的销售均价。根据现实生活中的经验,房子越大,那么每平米的房子价格会更贵一点,但是两者又不是一个纯粹的线性关系,不能用具体的函数描述。那么如果我现在手上有一个某大小的房子,我该怎么设置他的定价最合适呢?
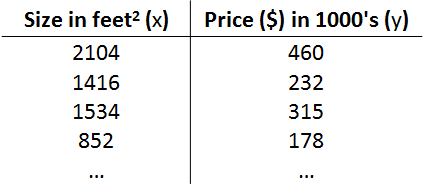
我们可以通过线性回归的方式,来寻找一个较优的函数来描述这种现有的数据,虽然不是精确地,但是是我在现有知识下已经达到的较好甚至最好方法了,也是可以的。
线性回归,从名字上来看,包含两个方面的内容,一是线性,表示的是模拟的特征描述函数是线性的,这包含一元线性的和多元线性的;另一方面是回归,表征的是数据特征,是在线性函数周围波动的。
何时使用线性回归?
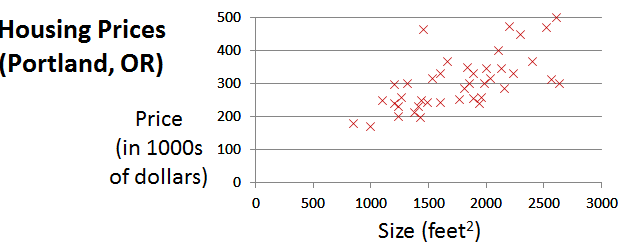
一般来说,线性回归是一个基本的数学方法,首先我们要考虑我们现有的数据特征是否符合现象回归的方法,做常用的办法是使用散点图的办法看一下数据的分布是否是线性得分布在坐标平面上。
基本数学模型
一元线性回归实质上是描述的一个自变量和一个因变量之间的关系,考虑一元函数常数项的话可以假设数据具有如下的函数类型:
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_θ (x)=θ_0+θ_1 x
hθ(x)=θ0+θ1x
我们常称
x
x
x为feature,
h
(
x
)
h(x)
h(x)为hypothesis。可以想象,该函数是二维平面中的线
而类似的多元线性回归只是在自变量数量上有所不同。因此可以得到类似的假设形式:
h
θ
(
X
i
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
i
x
i
+
⋯
h_θ (X_i )=θ_0+θ_1 x_1+θ_2 x_2+⋯+θ_i x_i+⋯
hθ(Xi)=θ0+θ1x1+θ2x2+⋯+θixi+⋯
在应用过程中只用找到对应的参数θ_i即可。文章讨论一元数据与多元数据是没有太大影响的,考虑到模型的普遍性,本文主要对多元回归进行介绍。
设已知数据集, X = X 1 , X 2 , … , X n T X={X_1,X_2,…,X_n }^T X=X1,X2,…,XnT,对于每个 X i X_i Xi又包含m个维度的数据,即 X i = x i 1 , x i 2 , … , x i m X_i={x_{i1},x_{i2},…,x_{im}} Xi=xi1,xi2,…,xim,对应的结果数据集为 Y = y 1 , y 2 , … , y n T Y={y_1,y_2,…,y_n }^T Y=y1,y2,…,ynT.
损失函数
那么我们可以通过已知的Y有监督的去寻找一系列最符合要求的
θ
i
θ_i
θi。首先定义我们需要的损失函数,即怎样才能算是“最符合”要求。通常情况下我们会定义预测输出与实际输出的平方误差最小为我们的目标函数,我们称此时的参数为最符合我们要求的,
J
(
θ
)
=
∑
i
=
1
n
(
h
θ
(
X
i
)
−
y
i
)
2
=
(
X
θ
−
Y
)
(1)
J(θ)=\sum_{i=1}^n(h_θ (X_i )-y_i )^2 =(Xθ-Y) \tag{1}
J(θ)=i=1∑n(hθ(Xi)−yi)2=(Xθ−Y)(1)
参数优化的目标就是让上式尽可能的小,最好能有最小值(尽管在最小值是也不一定是最优的参数组合,但是已经是一个比较好的参数组合了)。
最小二乘
传统的计算方法是通过最小二乘的方法得到得到损失函数的最小值,通过梯度下降法对参数求导数:
∂
J
(
θ
)
∂
θ
=
2
X
T
(
X
θ
−
Y
)
\frac{∂J(θ)}{∂θ}=2X^T (Xθ-Y)
∂θ∂J(θ)=2XT(Xθ−Y)
然后利用导数等于零,求的最小值:
X
T
X
θ
=
X
T
Y
⇒
θ
=
(
X
T
X
)
(
−
1
)
X
T
Y
X^T Xθ=X^T Y⇒θ=(X^T X)^(-1) X^T Y
XTXθ=XTY⇒θ=(XTX)(−1)XTY
通过公式直接计算即可。
该方法主要存在以下几个特点:
- 矩阵的逆可能不存在
- 该过程实际上是一个解线性方程组的过程,
- 计算量比较大
机器学习基本模型
既然作为一个基本的机器学习的算法,那么该算法也可以通过机器学习的模式进行考量。机器学习的最基础模型是一个简单的感知机模型,感知机模型的本质实际上是一个线性函数拟合器,我们把输入向量定义为 X i X_i Xi的m个维度数据,输出向量定义为 y i y_i yi,那么线性回归就可以归结为一个包含偏置的(m+1)输入,单输出的感知机模型。针对于目标函数,可以通过随机梯度函数的方式进行优化,对式(1)进行展开,即可按照以下模式进行优化:

参考文章:
https://zhuanlan.zhihu.com/p/45023349
https://blog.youkuaiyun.com/xbinworld/article/details/43919445
https://blog.youkuaiyun.com/xiazdong/article/details/7950084
https://www.cnblogs.com/pinard/p/5976811.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









