




写在前面
刚刚结束了Transformers介绍课程,发现纸上谈兵终究不足。要真正理解和吸收这个算法,最好的方式还是从代码角度进行实现。因此,本文将主要介绍Transformers的核心思想、数学原理,并最终展示如何仅用一个PyTorch库实现Transformers。
思想层面
在进入代码之前基于我个人的理解简单说一下Transformers算法逻辑。我们都知道Transformers是由encoder和decoder两个
模块组成,如图所示:
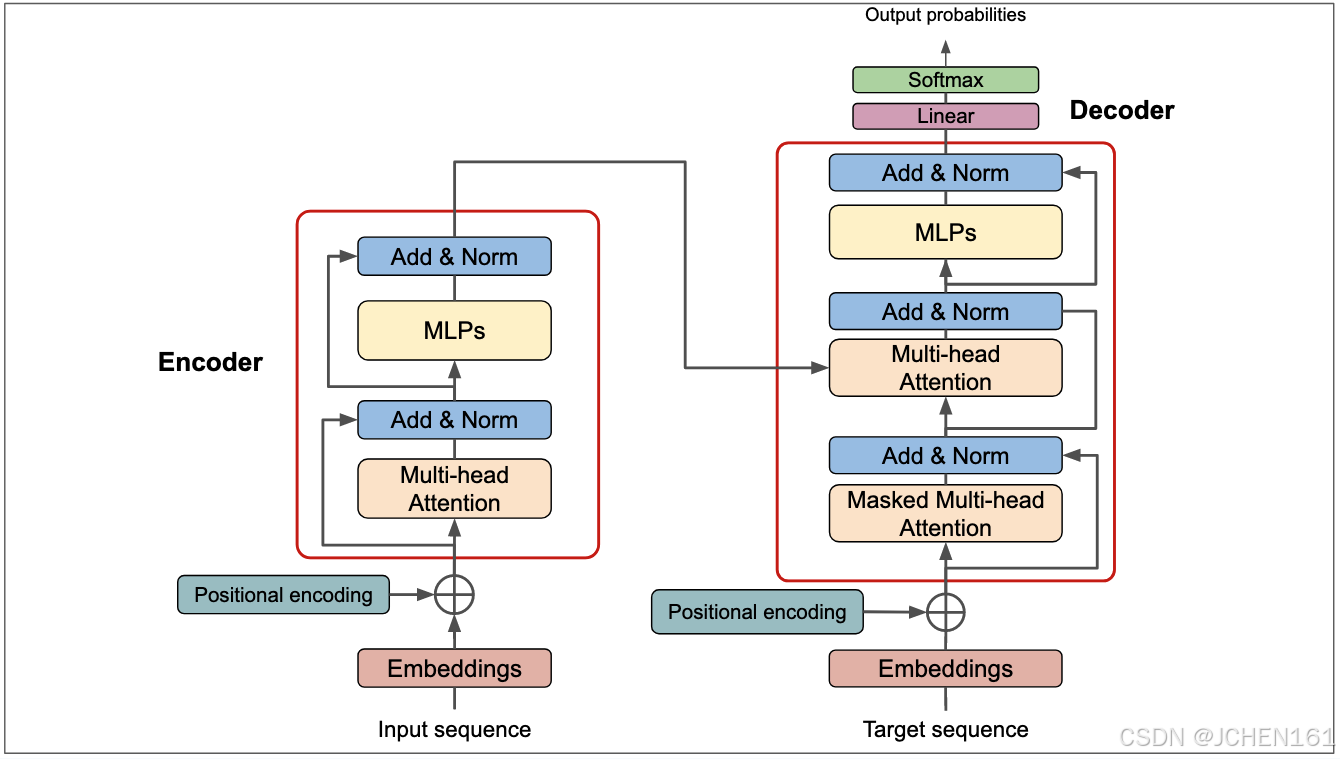
对一个n个tokens的语句输入sequence在embedding和positional encoding之后会进入多头注意力机制,该机制也是Transformers的核心部分。该部分为每个token定义了Q,K,V,即Query,Key,Value,可以具象地理解这三个term。想象要去图书馆查一本书,那么你要查的这本书的主题就是Q,图书馆里其他书的标签就是Key,每本书的内容就是Value。最后可以根据你要找的那本书和其他所有书的匹配程度来定义权重,并和每本书的内容做加权和,这就是最终你要得到的书的内容,而这里的每本书也就是每个token。这就是自注意力机制。对于多头我们可以把每个头类比成一个专家,对于同样的输入不同的专家关注的点不同,这样你所得到的结果就会更加全面。比如秋天到了,叶子飘落了,如果是生物学家他关注的可能是叶子里面的化学物质导致的,而文学家可能关注的是作一首诗或者写一篇文章,这也就符合咱们古人常说的兼听则明思想。其实这就是多头注意力机制的思想内核,我希望通过这样通俗的例子让各位在即使不了解数学公式和代码的情况下也能对Transformers有个直观的理解。那么下面进一步会说明为了表示这样的思想具体是如何通过数学公式实现的。
数学层面
在大致清晰了transformers的思想后,下面我们从数学角度来看如何实现这些思想的。让我们逐步推导各个张量的维度变化:
1. 输入维度分析
- Input sequence的维度是[B, L, D_in]
- B: batch size (批次大小)
- L: sequence length (序列长度)
- D_in: 输入维度 (一般是word embedding的维度)
2. Embedding和Position Encoding
- Word Embedding: [B,L,Dmodel][B, L, D_{model}][B,L,Dmodel]
- Position Encoding: [B,L,Dmodel][B, L, D_{model}][B,L,Dmodel]
- 相加后维度保持: [B,L,Dmodel][B, L, D_{model}][B,L,Dmodel]
- DmodelD_{model}Dmodel是token的embedding维度,通常是512或768等
3. Self-Attention计算过程
Q=Input×WQQ = Input × W_QQ=Input×WQ [B,L,Dmodel]×[Dmodel,Dk]=[B,L,Dk][B, L, D_{model}] × [D_{model}, D_k] = [B, L, D_k][B,L,Dmodel]×[Dmodel,Dk]=[B,L,Dk]
K=Input×WKK = Input × W_KK=Input×WK [B,L,Dmodel]×[Dmodel,Dk]=[B,L,Dk][B, L, D_{model}] × [D_{model}, D_k] = [B, L, D_k][B,L,Dmodel]×[Dmodel,Dk]=[B,L,Dk]
V=Input×WVV = Input × W_VV=Input×WV [B,L,Dmodel]×[Dmodel,Dk]=[B,L,Dk][B, L, D_{model}] × [D_{model}, D_k] = [B, L, D_k][B,L,Dmodel]×[D
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









