



本文将介绍一篇来自复旦大学、上海财经大学和字节跳动的最新综述论文《Multimodal Referring Segmentation: A Survey》。该研究全面系统地梳理了多模态指代分割(Multimodal Referring Segmentation)领域的背景、关键技术、主流方法和未来趋势。
多模态指代分割,旨在让计算机根据用户的自然语言描述(文本)或语音指令(音频),在图像、视频、3D场景等多种视觉媒介中,精确地分割出目标物体。这项技术是实现高级人机交互、具身智能等前沿应用的核心,拥有巨大的发展潜力。

论文标题: Multimodal Referring Segmentation: A Survey
作者团队: Henghui Ding, Song Tang, Shuting He, Chang Liu, Zuxuan Wu, Yu-Gang Jiang
所属机构: 复旦大学、上海财经大学、字节跳动
论文地址: https://arxiv.org/pdf/2508.00265v1
项目主页: https://github.com/henghuiding/Awesome-Multimodal-Referring-Segmentation
研究背景与意义
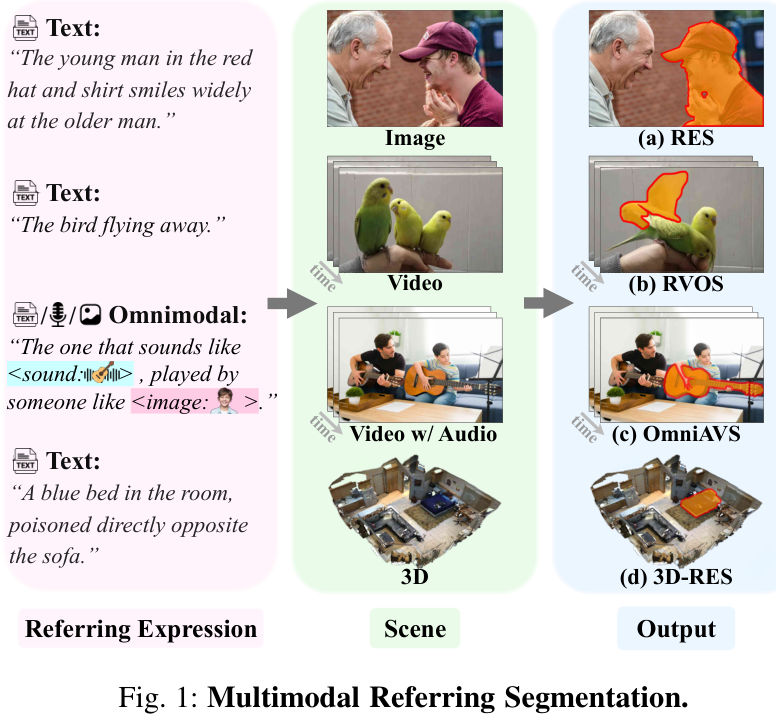
传统的图像分割技术,如语义分割和实例分割,通常只能识别和分割预定义的、有限的物体类别(例如“人”、“车”)。然而,在现实世界中,人们常常需要更灵活、更精细的指令,比如“分割出那个戴着红帽子、笑得很开心的人”,或者“把视频里飞走的那只鸟标出来”。
多模态指代分割技术正是为了解决这一挑战而生。它通过理解自由形式的指代表达(referring expressions),实现了对任意物体的精确分割,极大地提升了人机交互的自然性和效率。如下图所示,该任务涵盖了从图像、视频到3D场景的多种视觉数据,并能处理文本、音频甚至图文混合的指令。
近年来,随着卷积神经网络(CNNs)、Transformer以及大语言模型(LLMs)的飞速发展,多模态感知能力得到了显著增强,推动了指代分割研究的蓬勃发展。下图展示了该领域在顶级会议和期刊上发表论文数量的快速增长趋势。
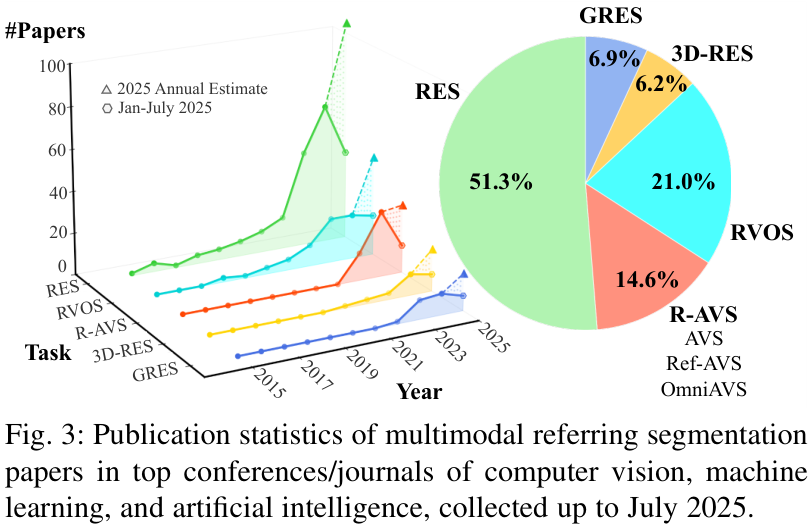
然而,现有综述大多局限于特定场景(如2D图像)或单一模态,缺乏一个全面、系统的梳理。这篇论文的出现,填补了这一空白,为研究者提供了该领域的全景图。
论文核心内容:一个统一的框架
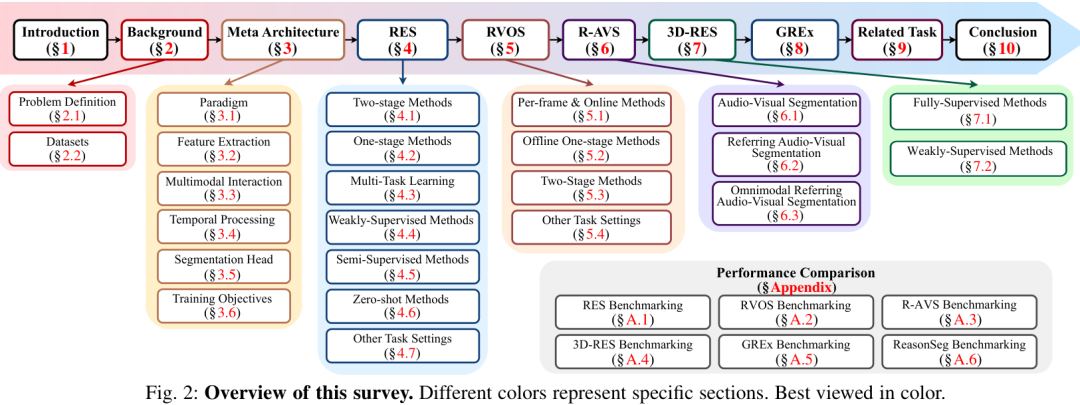
这篇综述的核心贡献之一是提出了一个统一的元架构(meta-architecture),系统地组织了该领域的各项任务和技术。下图清晰地展示了本综述的整体结构。
1. 任务定义与分类
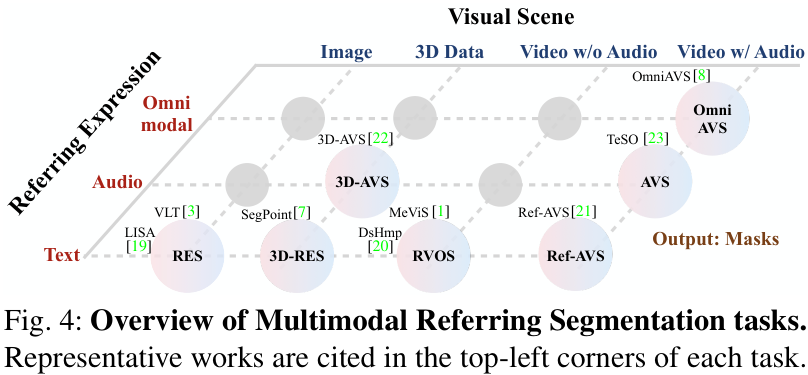
论文首先对多模态指代分割的各类任务进行了统一的形式化定义和归类。如下图所示,根据视觉场景(图像、视频、3D)和指代模态(文本、音频、多模态混合)的不同,该领域可以细分为多个子任务。
一个特别值得关注的概念是广义指代表达分割(Generalized Referring Expression Segmentation, GRES)。传统的指代分割(RES)通常假设指令只对应一个目标物体。然而,GRES打破了这一限制,能够处理更复杂的真实世界场景,包括:
多目标指代(如“穿长袖的人们”)
无目标指代(如“穿棕色皮夹克的女孩”,但图中并没有)
这种泛化能力极大地增强了技术的实用性。下图直观地对比了经典指代任务与广义指代任务的区别。

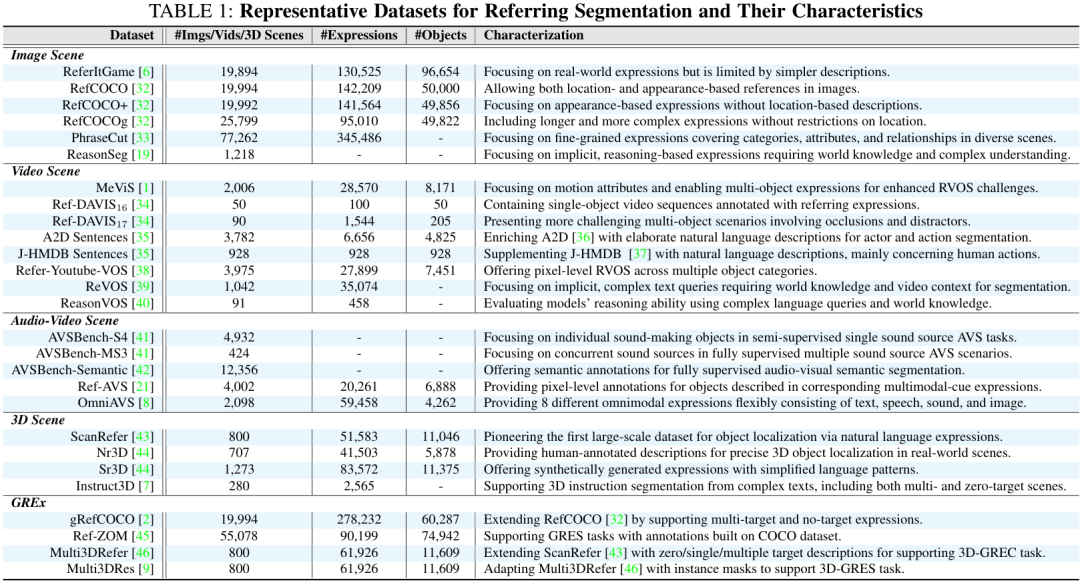
2. 数据集
论文详细梳理了该领域常用的17个基准数据集,涵盖图像、视频和3D场景。下表总结了这些数据集的关键特性,下图则展示了部分数据的实例。

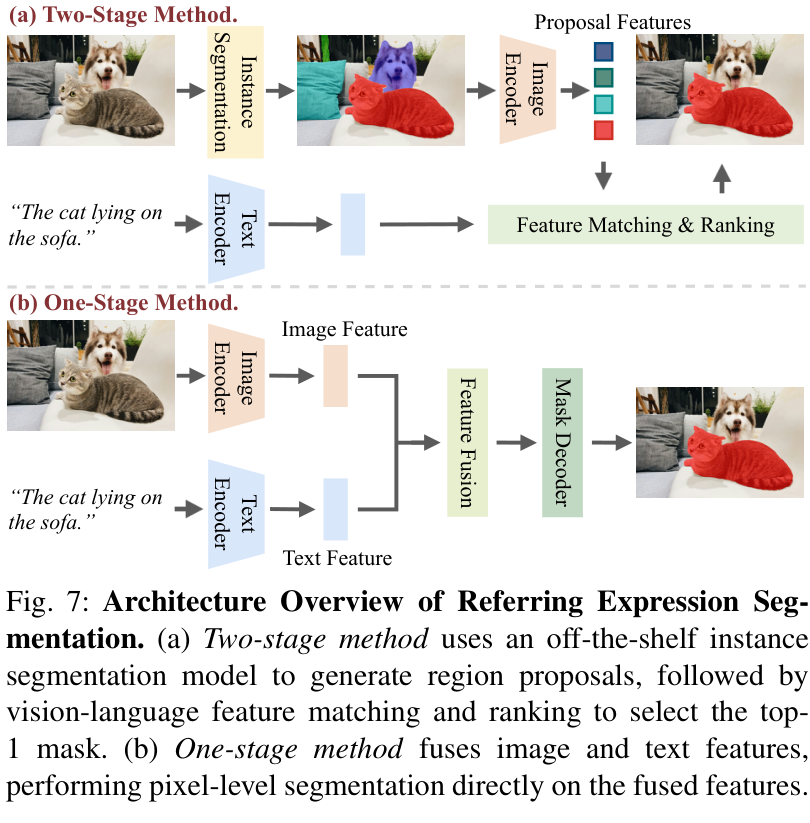
3. 统一元架构
论文将指代分割模型的主流范式归纳为两阶段(Two-stage)和单阶段(One-stage)两种。
两阶段方法:首先使用一个现成的实例分割模型生成候选区域,然后将这些区域与指代表达进行匹配和排序,选出最佳结果。这种方法模块化清晰,但容易出现错误传播且计算成本高。
单阶段方法:直接将视觉特征和语言/音频特征进行融合,通过一次前向传播直接预测出分割结果。这种端到端的方式效率更高,也是当前的主流。
下图清晰地展示了这两种架构的区别。
在此基础上,论文进一步将核心技术模块分解为:
特征提取:如何从视觉、文本、音频等不同模态中提取有效特征。
多模态交互:如何实现跨模态特征的有效融合与对齐,这是任务的关键。
时序处理(视频任务):如何处理视频中的时间信息,理解运动和变化。
分割头:如何从融合后的特征生成最终的像素级分割掩码。
4. 各子领域方法回顾
论文分章节详细回顾了在图像、视频、音频-视频、3D等不同场景下的代表性方法,并对它们的架构、性能进行了分析和比较。
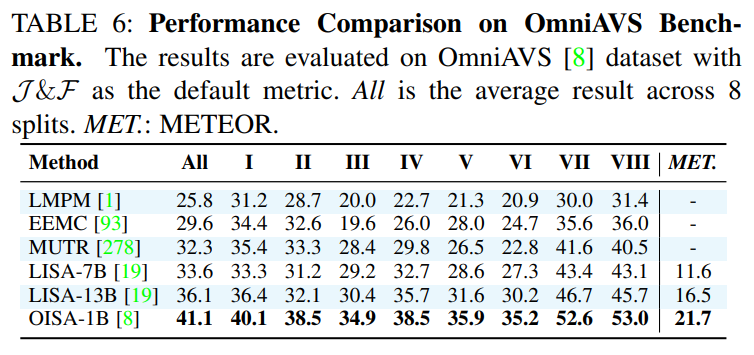
一个新兴且有趣的方向是全模态指代音视频分割(Omnimodal Referring Audio-Visual Segmentation, OmniAVS)。该任务允许用户灵活地组合文本、语音、参考图像、甚至声音事件作为指令,如下图所示,这极大地丰富了交互的维度和能力。

5. 相关任务与应用
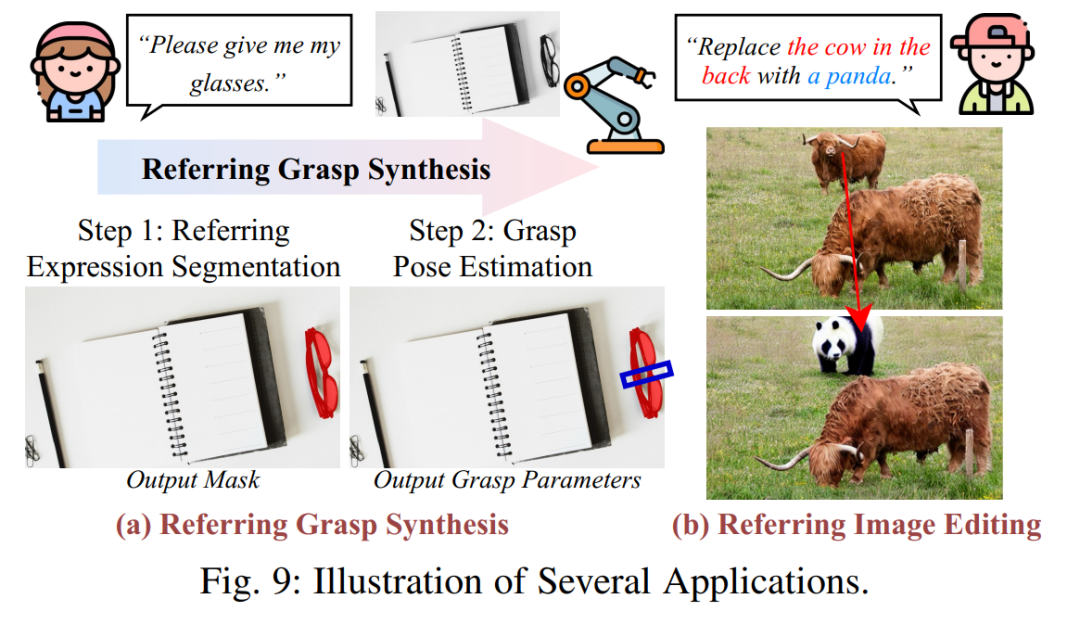
除了核心的分割任务,论文还介绍了相关的任务,如指代表达理解(REC,预测边界框)、指代表达生成(REG)等。同时,论文展示了该技术在机器人抓取、图像编辑等领域的实际应用,凸显了其巨大的应用价值。
实验与性能对比
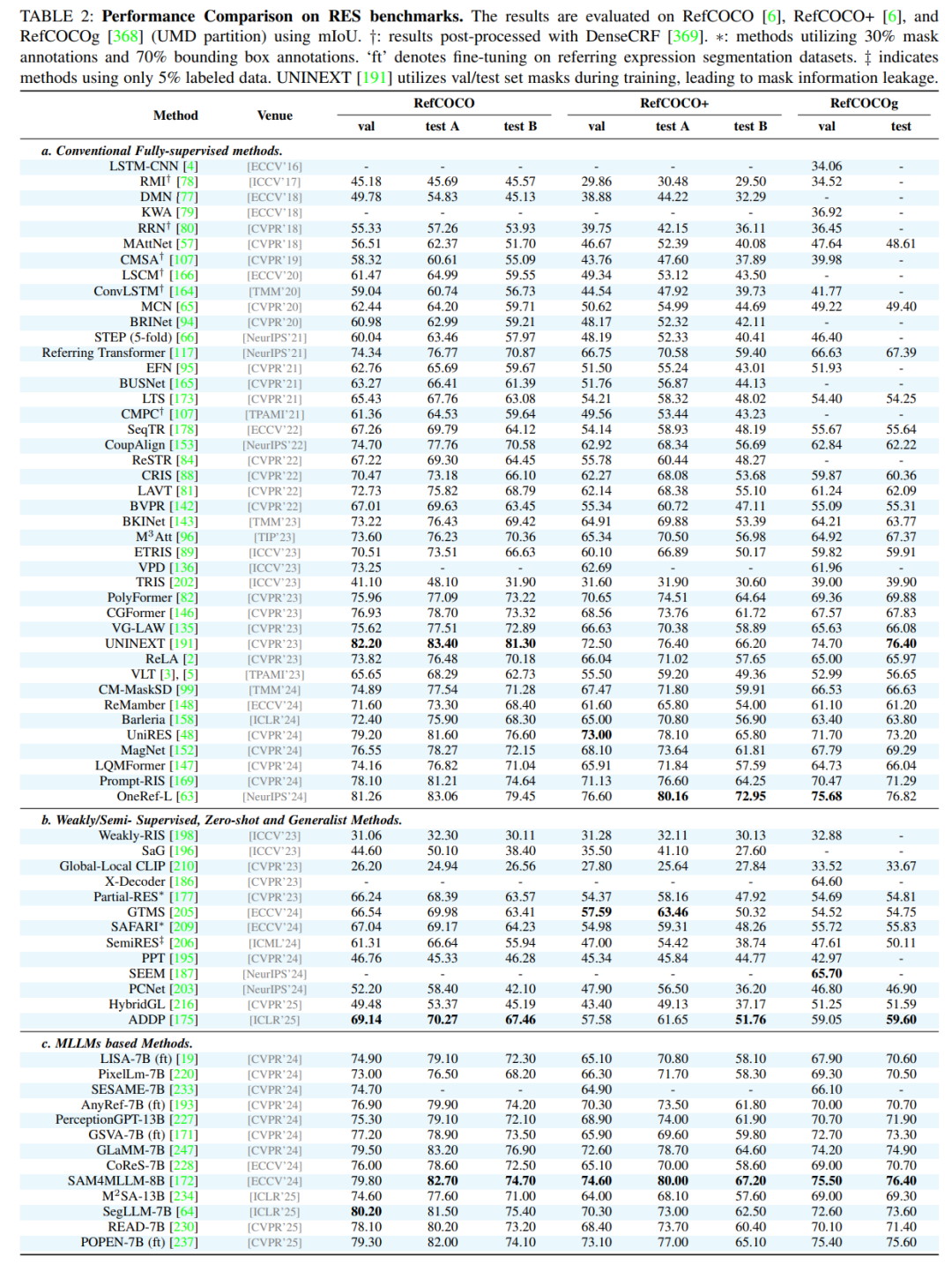
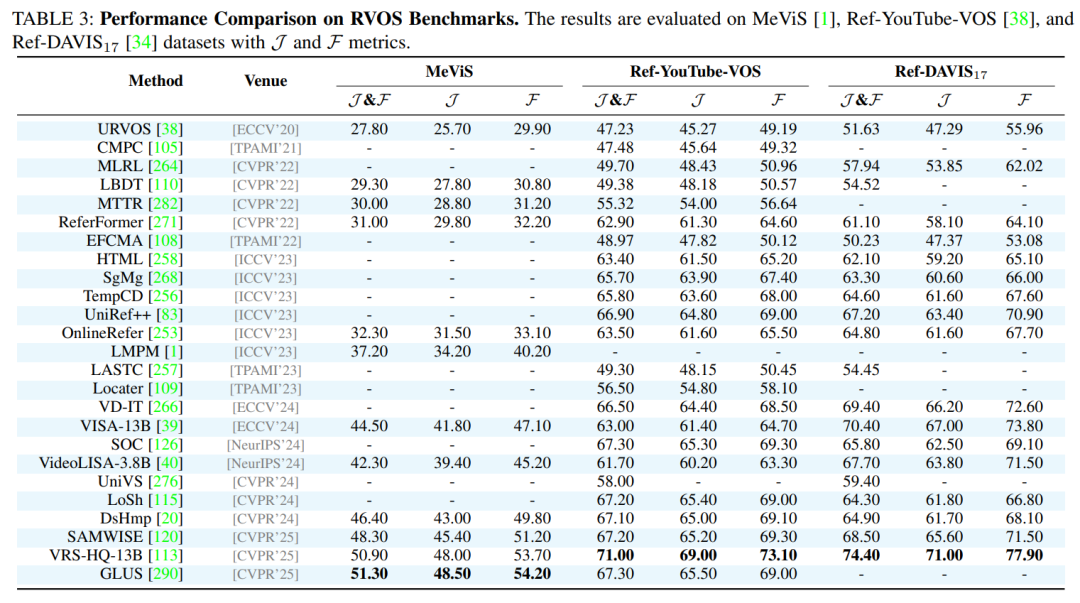
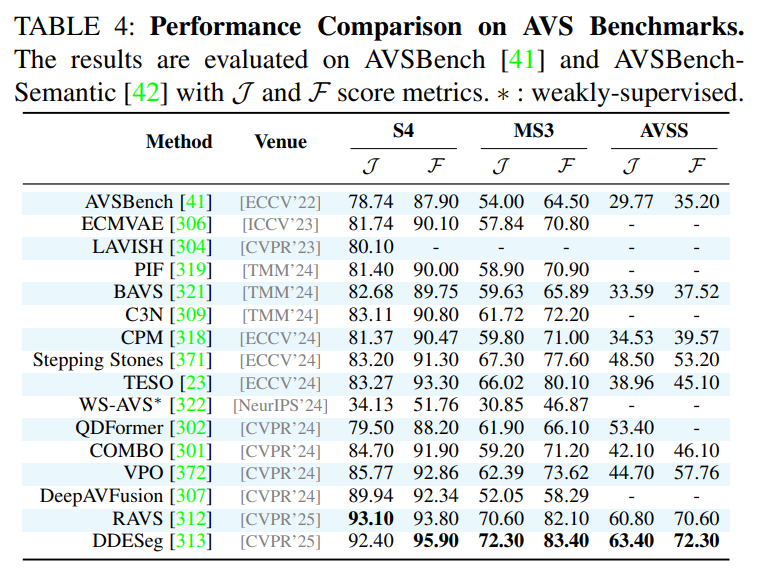
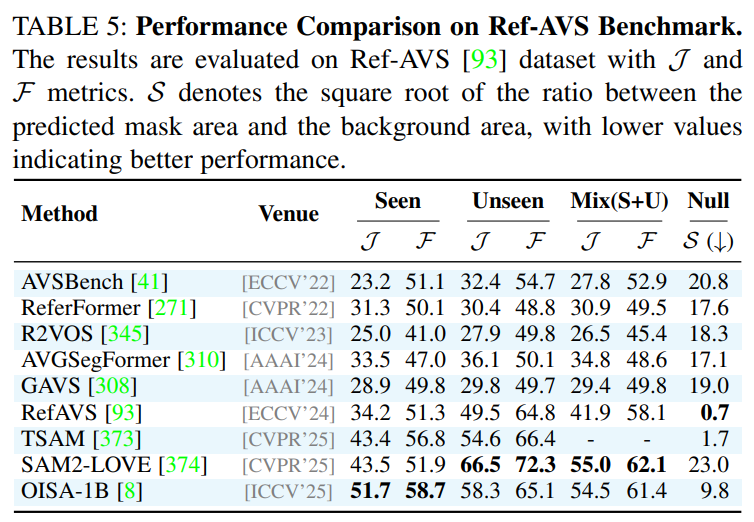
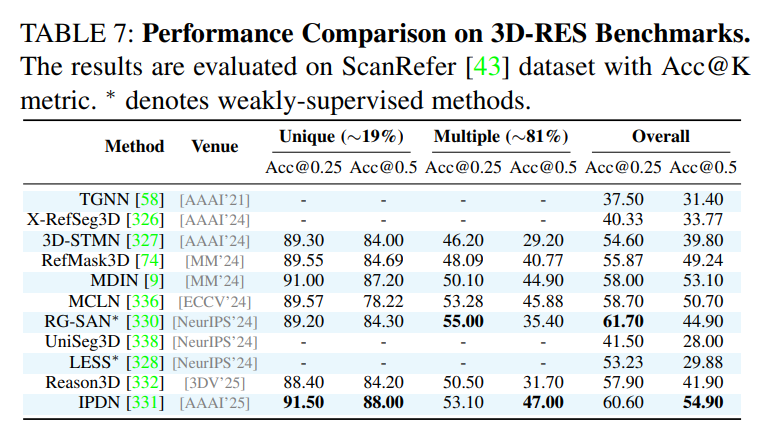
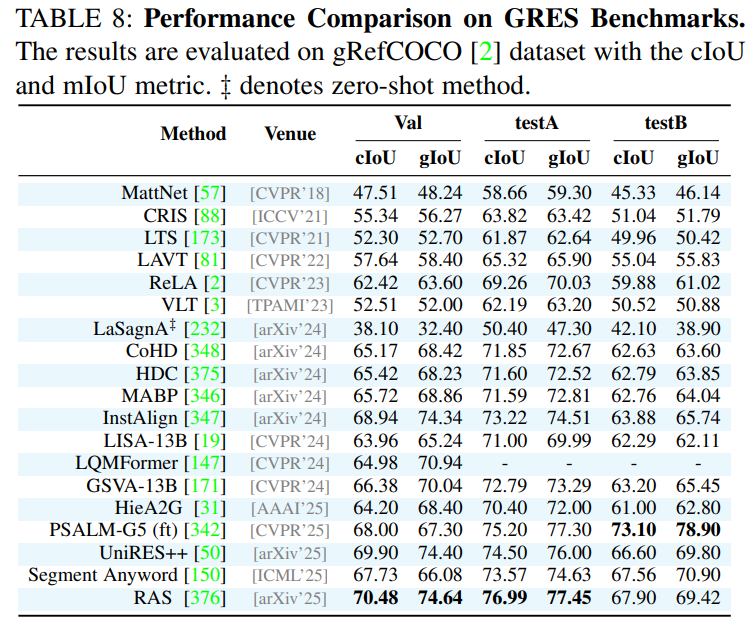
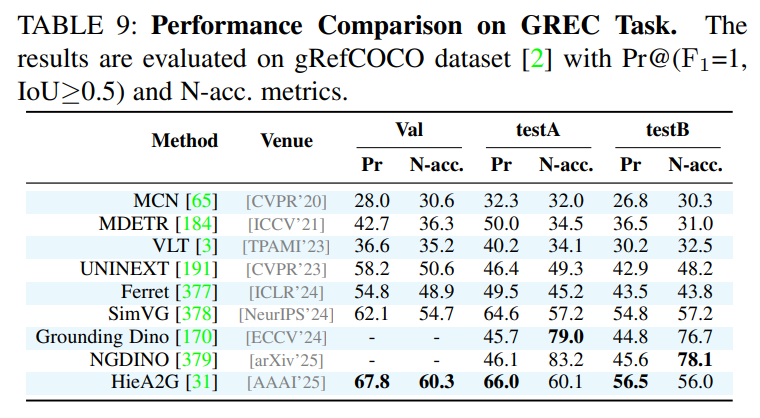
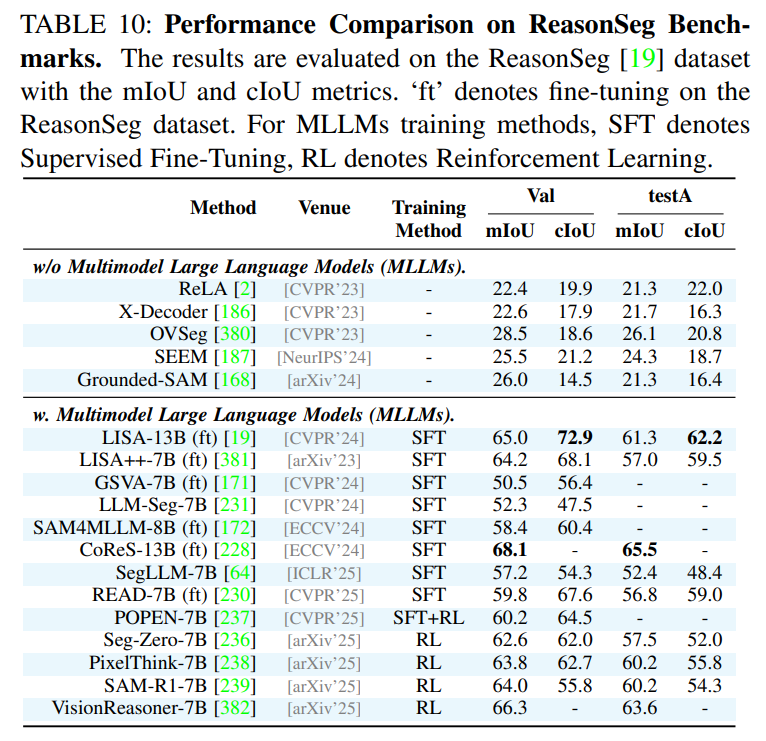
作为一篇综述,论文在附录中提供了详尽的性能对比表格,涵盖了所有主要任务和数据集上的SOTA(State-of-the-Art)方法。这些表格为研究者快速了解不同方法的优劣提供了宝贵的参考。例如,论文指出在经典的RES任务上,基于Transformer和MLLM的方法(如OneRef, SAM4MLLM)已成为性能的领先者;在更具挑战性的RVOS任务上,VRS-HQ-13B等模型展现了卓越的性能。
论文贡献与未来方向
贡献:
首次全面综述:系统性地梳理了多模态指代分割的各个方面,建立了一个统一的分类法和元架构。
详尽的资源整理:汇总了该领域的关键数据集、代表性方法和性能基准,并提供了一个持续更新的GitHub项目。
指明未来趋势:总结了该领域的前沿方向,为后续研究提供了深刻洞见。
未来方向:
全模态理解(Omnimodal Understanding):发展能够灵活处理文本、语音、声音、图像等多种混合指令的通用模型。
面向真实场景的泛化:推动GRES等技术的发展,使其能更好地处理现实世界中的复杂性和模糊性。
以动作为中心的视频理解:加强对视频中复杂时序和动态关系的理解。
融合基础模型与推理能力:利用大语言模型(LLMs)和视觉基础模型(VFMs)的强大能力,解决需要常识和复杂推理的分割任务。
总而言之,这篇综述为多模态指代分割领域提供了一份宝贵的“地图”和“百科全书”,无论是初学者还是资深研究者,都能从中获益匪浅。
了解最新 AI 进展,欢迎关注公众号
投稿寻求报道请发邮件:amos@52cv.net

















 4615
4615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









