




 本文探讨了在使用JMeter进行性能测试时,如何通过优化配置、脚本和执行策略来提升测试效果。从调整JVM设置、精简脚本到合理记录测试结果,提供了实用的建议。
本文探讨了在使用JMeter进行性能测试时,如何通过优化配置、脚本和执行策略来提升测试效果。从调整JVM设置、精简脚本到合理记录测试结果,提供了实用的建议。
在jmeter进行性能测试的实践工作中,不知道大家有没有遇到过,针对同一个接口,不同的人测试出来的结果会有不一样的情况,尤其是在一些大并发量下就更会有这种情况。
那么为什么会有这种情况呢?
我觉得,很大一部分是因为大家在写jmeter脚本的时候,一些细节地方被忽视,而导致结果差异,今天我就总结一下,自己工作中整理的一些会影响jmeter本身性能的细节,供大家参考。
配置部分:
Jmeter涉及的配置文件主要是jmeter.properties和jmeter的执行文件。
大家都知道,jmeter是基于java的,那么势必会用到jvm相关的信息。而jmeter本身默认的是512m的heap大小,大家可以根据自己PC的配置做一个相应的调整,以便支持更多的线程并发。
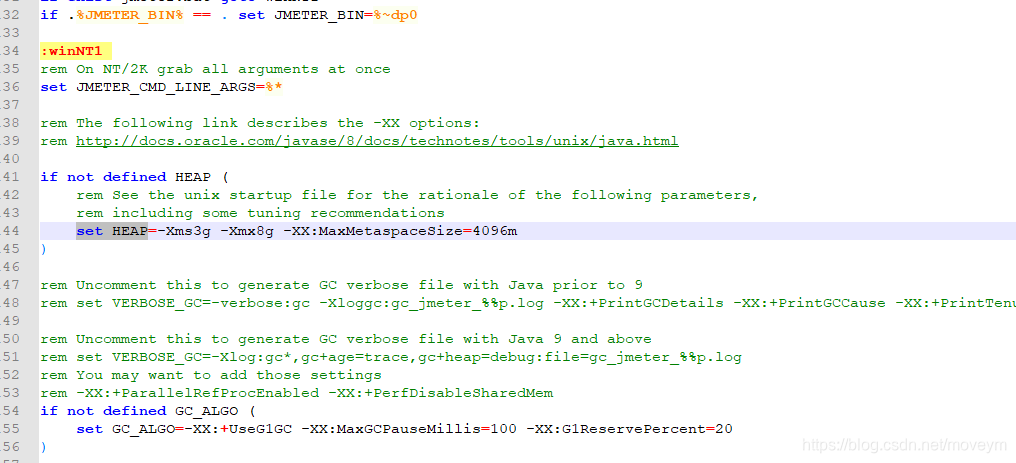
另外,命令行下,如果想查看每个请求返回的结果,需要修改jmeter.properties配置文件,
#---------------------------------------------------------------------------
# Results file configuration
#---------------------------------------------------------------------------
# This section helps determine how result data will be saved.
# The commented out values are the defaults.
# legitimate values: xml, csv, db. Only xml and csv are currently supported.
#jmeter.save.saveservice.output_format=csv
# The below properties are true when field should be saved; false otherwise
#
# assertion_results_failure_message only affects CSV output
#jmeter.save.saveservice.assertion_results_failure_message=true
#
# legitimate values: none, first, all
#jmeter.save.saveservice.assertion_results=none
#
#jmeter.save.saveservice.data_type=true
#jmeter.save.saveservice.label=true
#jmeter.save.saveservice.response_code=true
# response_data is not currently supported for CSV output
#jmeter.save.saveservice.response_data=false
# Save ResponseData for failed samples
#jmeter.save.saveservice.response_data.on_error=false
#jmeter.save.saveservice.response_message=true
#jmeter.save.saveservice.successful=true
#jmeter.save.saveservice.thread_name=true
#jmeter.save.saveservice.time=true
#jmeter.save.saveservice.subresults=true
#jmeter.save.saveservice.assertions=true
#jmeter.save.saveservice.latency=true
# Only available with HttpClient4
#jmeter.save.saveservice.connect_time=true
#jmeter.save.saveservice.samplerData=false
#jmeter.save.saveservice.responseHeaders=false
#jmeter.save.saveservice.requestHeaders=false
#jmeter.save.saveservice.encoding=false
#jmeter.save.saveservice.bytes=true
# Only available with HttpClient4
#jmeter.save.saveservice.sent_bytes=true
#jmeter.save.saveservice.url=false
#jmeter.save.saveservice.filename=false
#jmeter.save.saveservice.hostname=false
#jmeter.save.saveservice.thread_counts=true
#jmeter.save.saveservice.sample_count=false
#jmeter.save.saveservice.idle_time=true
将上面的注释打开,并且值修改成true,就会打开该条记录,jmeter就会将该条信息输出到我们指定的jtl文件中,这个需要慎重,因为压测过程中,会产生大量的这样的记录,真正压测时,最好不要开太多的日志记录。另外,#jmeter.save.saveservice.output_format=csv
如果更改为xml,保存的数据量会很大,也是会影响io,从而影响测试的结果值。这些都是需要注意一下的。
另外,日志级别也需要去留意一下,新版本jmter记录的位置貌似不太一样。
脚本部分:
大家在写jmeter脚本的时候,首先如果是在调试,那么无所谓,可以增加很多监控类的组件,例如查看结果树,聚合报告,吞吐量图形等。而如果是真正放在服务端去开始压测了,那么就最好保持脚本的干净,即只保留最需要的部分,把查看结果树、聚合报告之类的统计组件给禁用或删除,因为这些会影响到客户端jmeter的性能。
另外,如果你的脚步比较复杂,涉及到beanshell,那么也需要注意写法了。
jmeter脚本在运行过程中应该避免循环执行大量计算的工作:比如测试脚本中每个虚拟用户循环使用了BeanShell对数据进行处理,如果真的有此需求的话,建议使用扩展function。
BeanShell是JMeter内置的功能,但是由于它是脚本语言,动态加载执行的,因此效率不是很高,不太适合于在经常执行的场景下,比如将BeanShell放在循环内部,不断地被执行。比较适合的应用场景是放在执行一次、或者少数几次的地方,比如在循环外部读取配置文件内容等。
而Java扩展JMeter的实现方式的效率比较高,适合于放在经常执行的测试步骤中,但是由于它不是JMeter内置的功能,扩展起来需要有些工作量,而且部署的时候也比较麻烦(分布式运行的时候需要将自定义的JAR拷贝至所有的机器上)。读者根据自己的使用场景来选择适合自己的自定义脚本的方式。
所以大家在写jmeter脚步到时候,也要注意这些细节,而不是调试通了就好了,这个做功能测试ok的,但是做性能测试那就需要多考虑一下。
最后,有些同学,可能比较喜欢使用jp@gc - PerfMon Metrics Collector做监控收集,我个人是不建议这么做,因为这个也会额外消耗jmeter本身多性能,应该让jmeter只负责施压,做更加单一的任务,其他的任务可以做解耦,或用其他工具替代,譬如监控的话,你完全可以用nmon、zabbix、或自定义脚本等等其他很多的方式。
执行部分:
大家在做稳定性测试或者分布式压测的时候,如果执行命令中带有-l参数,把结果保存到jtl文件中,如果你的tps很大,那么这个文件的读写io就会占用很多资源,大家也要留意留意,如果不需要记录这个jtl结果,完全可以不记录,另外,如果是记录了jtl,这个jtl很有可能是会好几个G的大小,那么,估计你需要自己写个脚本去解析结果了,网上的那个jar包解析,速度也是不快的。
原则就是:尽可能让客户端不出现瓶颈先于服务端,目的是为保证测试的结果尽可能的准确些。

















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









