




 本文提出了一种深度残差学习框架,解决了深层网络优化难题。该框架通过学习残差映射而非原始映射,使网络更易优化并提高精度。实验表明,152层的残差网络在ImageNet上取得优异结果,且复杂度低于VGG网络。
本文提出了一种深度残差学习框架,解决了深层网络优化难题。该框架通过学习残差映射而非原始映射,使网络更易优化并提高精度。实验表明,152层的残差网络在ImageNet上取得优异结果,且复杂度低于VGG网络。
理解论文 Deep Residual Learning for Image Recognition
Abstract
1.提出了一个残差学习框架,以简化比以前使用的网络更深入的网络训练。
2.显式地将层重新表示为参考层输入的学习残差函数,而不是学习未引用的函数。
3.这些残差网络更容易优化,并且获得更高的精度。
4.使用152层的残差网络在ImageNet 数据及上评估网络,比VGG深8倍,但是仍然含有较低的复杂度。
5.对于许多视觉识别任务来说,depth of representations是至关重要的。 仅仅由于我们非常深入的representations,我们在COCO目标检测数据集上获得了28%的相对提升。
一、Introduction
1.网络的深度发挥了重要的作用。
2.stacking更多的layers产生一个问题:梯度消失或者是梯度爆炸,这导致从开始就阻碍收敛。然而,这个问题很大程度上通过normalized initialization和中间normalization层被解决。使得几十层的网络能够开始收敛。
3.当更深层的网络开始收敛的时候,一个degradation问题开始暴露:随着网络深度的增加,精度达到饱和,然后急速下降。这种退化并不是由过拟合引起的,给一个适当的网络增加更多的层导致更高的训练错误,如图1所示,
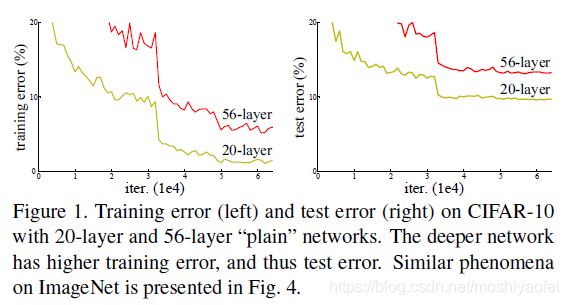
4.degradation表明并不是所有的网络都是一样容易去优化。考虑一个浅层的网络结构,然后在这个浅层网络上添加更多的层,使它变得更深。存在一个解决方案:添加的层是标识映射,而其他层是从学习到的更浅的模型复制而来的。
5.本文中提出了deep residual learning framework,来解决degradation问题。我们不希望每几个堆叠层直接拟合所需的底层映射,而是显式地让这些层拟合残差映射。
6.一个残差模块如图2所示,
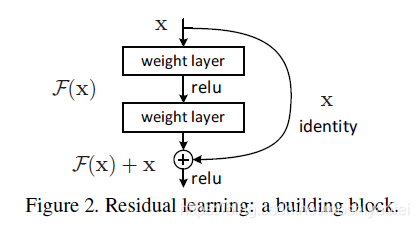
7.在ImageNet上的实验结果表明,(1)提出的更胜的残差网络时容易去优化的,但是与其对应的普通网络(简单堆积层)显示了更高的训练错误率当深度增加时。(2)残差网络随着深度的增加能都很容易获得精度 的提升。
8.在ImageNet classification dataset上,残差网络得到了特别好的结果,152层的残差网络时最深的网络,同时 比VGG网络有更小的复杂度。后续的其他数据集上的良好表现表明residual learning principle是通用的。
二、Related Work
三、Deep Residual Learning

















 2234
2234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









