



深度学习核心模型原理与应用:ViT、Transformer、RNN/LSTM/GRU、CLIP详解
一、Vision Transformer (ViT)
1. 核心原理
ViT将图像分割为固定大小的图像块(Patches),并将其视为序列输入Transformer编码器。具体流程如下:
-
图像分块:输入图像 x 被分割为 N个p×p 的块,展平后得到 xp。
-
线性映射:通过可学习矩阵 E将块映射为嵌入向量。
-
位置编码:添加1D正弦位置编码(公式与Transformer相同)
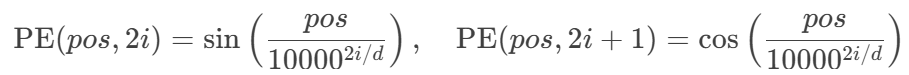
-
类别Token:在序列首添加可学习的
[class]token,用于最终分类输出。
2. 模型结构
Transformer Encoder由L层相同模块堆叠而成,每层包含:
-
多头自注意力(MSA):

-
层归一化(LayerNorm)与残差连接
-
MLP Block:两层全连接层加GELU激活函数:
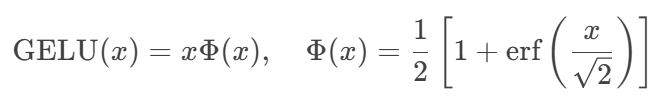
3. 实验性能
| 模型 | ImageNet Top-1 (%) | 计算量 (TPUv3-core-days) |
|---|---|---|
| ViT-H/14 | 88.55 | 2.5k |
| BiT-L (CNN) | 87.54 | 9.9k |
优势:
-
在大规模数据(如JFT-300M)预训练下超越CNN模型
-
并行计算效率高,适合分布式训练
缺陷:
-
依赖大量预训练数据,小数据集表现较差
-
位置编码对二维空间信息建模能力有限
二、Transformer 模型
1. 整体架构
模型分为编码器和解码器两部分:
编码器
-
输入处理:词嵌入 + 位置编码
-
N个编码层(每层含以下子层):
-
多头自注意力机制
-
Add & Norm:残差连接 + 层归一化
-
前馈网络(FFN):两层全连接(ReLU激活)
-
解码器
-
输入处理:输出嵌入 + 位置编码
-
N个解码层(每层含三个子层):
-
掩码多头自注意力(防止信息泄露)
-
编码器-解码器注意力(Key/Value来自编码器输出)
-
Add & Norm + FFN
-
2. 关键机制
-
位置编码:使用正弦函数生成位置信息
-
多头注意力:并行多组注意力头增强特征提取能力
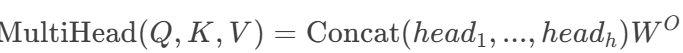
-
掩码机制:解码时屏蔽未来位置信息
3. 优势与局限
优势:
-
长距离依赖建模能力优于RNN/LSTM
-
高度并行化,训练速度显著提升
局限:
-
计算复杂度随序列长度呈平方增长
-
位置编码对长序列的泛化能力不足
三、循环神经网络(RNN/LSTM/GRU)
1. RNN基本结构
隐状态更新公式:
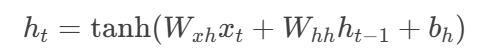
输出计算:
![]()
2. LSTM
引入门控机制解决梯度消失问题:
-
遗忘门:控制历史信息保留
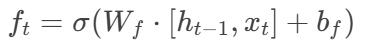
-
输入门:控制新信息写入

-
细胞状态更新:
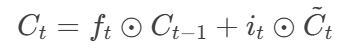
-
输出门:
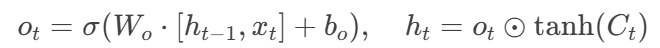
3. GRU
简化门控结构:
-
更新门:
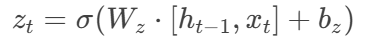
-
重置门:

-
候选状态:
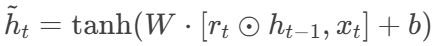
-
隐状态更新:

4. 对比分析
| 模型 | 参数量 | 训练速度 | 长序列表现 |
|---|---|---|---|
| RNN | 低 | 慢 | 差(梯度消失) |
| LSTM | 高(RNN的4倍) | 中等 | 优 |
| GRU | 中等 | 快 | 良 |
四、CLIP模型
1. 核心思想
通过对比学习对齐图像与文本特征,实现零样本(Zero-Shot)分类:
-
双塔结构:图像编码器(ViT/ResNet) + 文本编码器(Transformer)
-
对比损失:最大化配对图像-文本的相似度,最小化非配对相似度
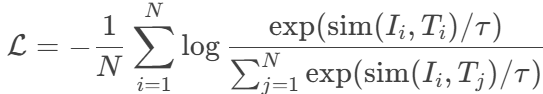
其中 simsim 为余弦相似度,ττ 为温度系数。
2. 零样本推理流程
-
生成类别描述文本(如"A photo of a [class]")
-
提取文本特征 {Tk}k=1
-
计算图像特征 II 与所有文本特征的相似度
-
选择相似度最高的类别作为预测结果:
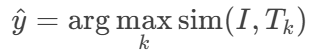
3. 性能优势
-
零样本迁移能力:在27个数据集上平均超越ResNet50监督基线(ImageNet +1.9%)
-
少样本学习:16样本/类时准确率比基准高20个百分点
-
鲁棒性:在ImageNet变体(如对抗样本)上表现更稳定
4. 应用场景
-
图文检索
-
零样本图像分类
-
多模态预训练基座(如BLIP、GLIP)
总结
本次课程系统学习了ViT、Transformer、RNN系列及CLIP的核心原理:
-
ViT将Transformer引入视觉领域,打破CNN垄断但依赖大数据预训练
-
Transformer凭借自注意力和并行计算成为NLP主流架构
-
RNN/LSTM/GRU处理序列数据的经典方法,LSTM/GRU有效缓解梯度消失
-
CLIP开创多模态对比学习新范式,实现强大的零样本迁移能力
各模型在结构设计和应用场景上形成互补,为深度学习解决复杂任务提供多样化工具。

















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









