



波士顿动力Auto-Connect-复杂环境下机器人连接解决方案
移动机器人必须在各种各样的环境中运行。例如,Spot 机器人需要在高辐射灾害现场收集数据,在制造工厂识别空气泄漏,并在波士顿的冬季积雪中跋涉。这些应用场景要求硬件和软件方面取得进步,才能使移动机器人在如此复杂的环境中灵活操控。
除了应对严苛的物理环境外,Spot 还需要可靠地接收和发送数据给操作员,以便执行最新指令并返回有价值的数据。Orbit 是 Boston Dynamics 开发的一款基于 Web 的软件,它将操作员与其 Spot 机器人车队连接起来,使他们能够随时随地收集和查看有关其设施的数据。
在如此多变的环境中与这些操作员建立连接,本身就面临着一系列独特的挑战,这也促使波士顿动力开发了 Auto-Connect——我们全新的机器人与操作员连接系统。
机器人是服务器吗?
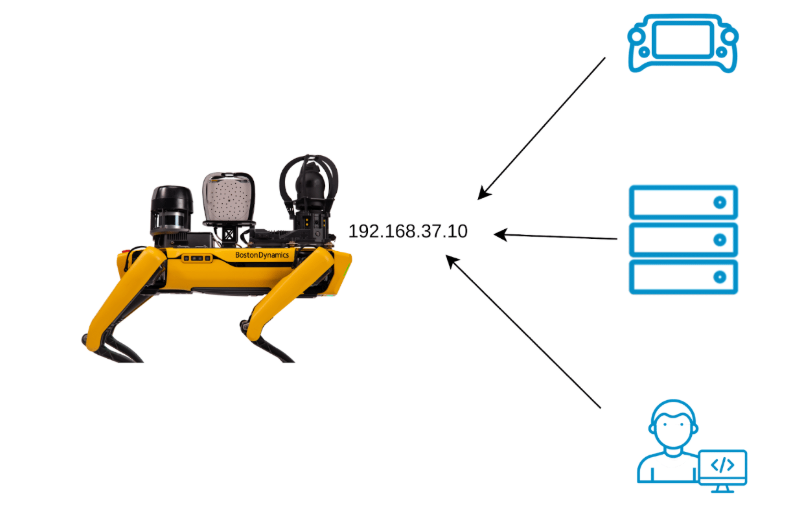
图 1:以机器人为服务器的传统机器人网络拓扑结构
当像 Spot 这样的移动机器人需要向可能远在数百英里之外的办公室(或海滨度假村)的操作员发送数据时,它该如何操作呢?一种方法是将机器人视为互联网“服务器”,就像您正在阅读此内容的网站一样,并让操作员使用的软件通过固定 IP 地址(类似于数字邮政地址)连接到机器人。
很简单,对吧?这种方法工程师都很熟悉,而且现有技术也支持得很好。事实上,我们大多数客户目前都是通过这种方式连接到 Spot 的(而且这种方式仍然可行)。但是,机器人与互联网服务器在一些重要方面存在差异,而这些差异可能会导致在您最需要它的时候,机器人连接不稳定。
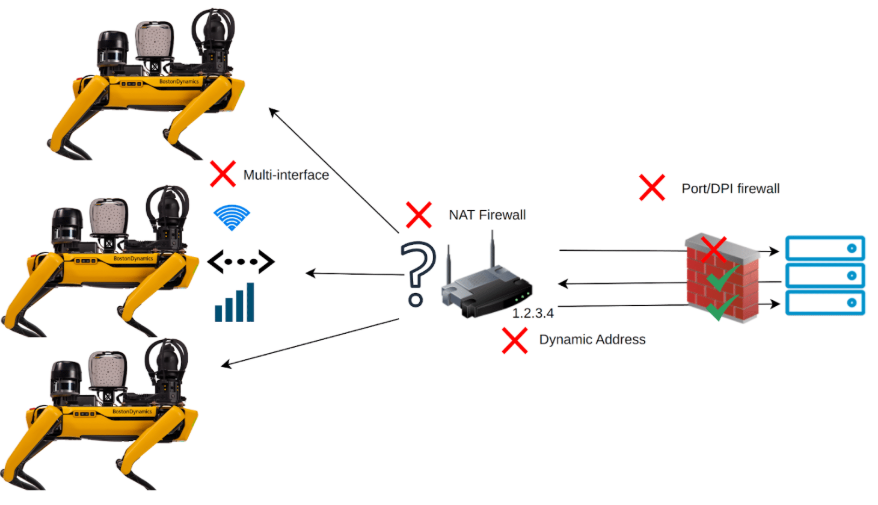
图 2:机器人作为服务器网络拓扑的常见问题
一个显而易见的区别是,机器人四处移动!Spot 的一天通常从它停靠在充电底座上开始,充电并通过固定网线(就像台式电脑一样)连接到互联网。时间到了,Spot 从充电底座上站起来,走上楼梯,对一台仪表进行预定的检查,此时仪表已连接到大楼内的 Wi-Fi 网络。之后,Spot 离开大楼去检查室外设备,此时 Wi-Fi 连接断开,它会连接到附近的 5G 基站。
每次网络切换时,Spot 都会与所有运营商断开连接,需要重新连接。这种方法虽然可行,但每次切换都需要时间并更改 IP 地址,可能会导致下游连接出现问题。Spot 可以选择始终使用“最低标准”网络,例如 5G 信号,但这样一来,当 Spot 停靠在码头时,就无法使用更可靠、更快速,在某些情况下也更经济的有线连接。
更复杂的是,每个网络都可能设有自己的安全过滤器或“防火墙”,阻止 Spot 的部分或全部数据传输到运营商。对于许多 Spot 客户而言,网络安全至关重要,甚至受到特定法规的约束。在极端情况下,互联网流量仅允许访问特定网站列表,且必须使用最新的加密标准。我们的现场部署和支持团队会与客户的 IT 部门合作配置防火墙,以允许 Spot 的数据通过,但鉴于 Spot 使用的数据类型繁多,且每种数据类型都可能被防火墙过滤(例如摄像头视频、API 命令等),这项工作可能既耗时又复杂。
传统互联网服务器与 Spot 等移动机器人之间最后一个显著区别在于我们之前讨论过的唯一 IP 地址。除了每个网络(Dock、Wi-Fi、5G)都有不同的地址外,Spot 在单个网络上的地址也可能并非唯一或稳定。
如今,大多数联网设备都会由其连接的路由器自动分配 IP 地址,而且该地址可能每隔几天就会更改。在许多情况下,设备都位于“NAT”(网络地址转换)之后,连接到同一路由器的多个设备共享一个“公网”IP 地址。当路由器收到指向该地址的连接请求时(例如操作员从远程位置连接到 Spot),路由器无法确定应将请求转发到哪个特定设备。当然,这些问题可以在客户网络配置中解决,但这既耗时,又会在原本就复杂的移动机器人与人工操作员和外部服务连接环境中引入另一个故障点。
Auto-Connect:让我们(自动)连接
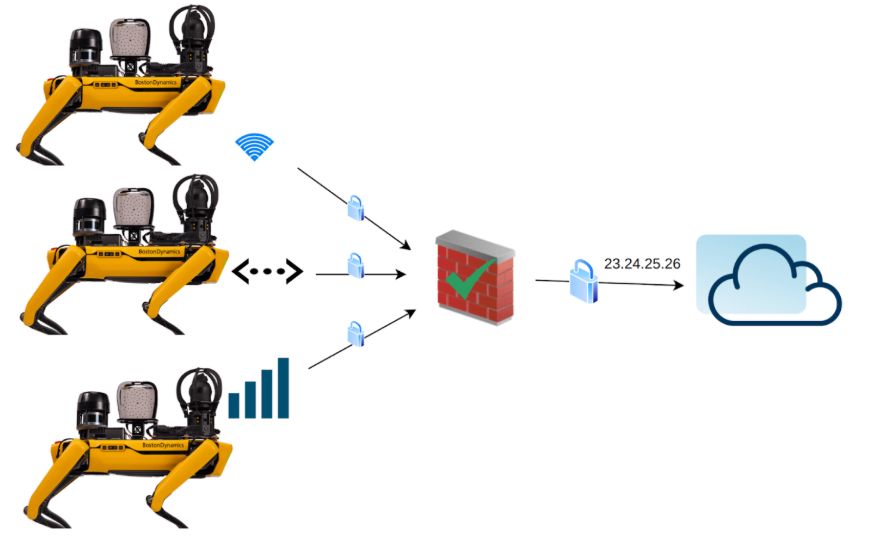
图 3:自动连接网络拓扑结构可处理复杂环境
波士顿动力公司已为全球客户部署了超过 1000 台 Spot 机器人,并发现机器人连接方面的复杂问题是客户成功应用和推广的主要障碍。为此,我们开发了 Auto-Connect 系统,旨在解决移动机器人连接的独特复杂性,同时缩短 Spot 在您特定环境中的设置时间。
自动连接的工作原理是在机器人和与其连接的外部应用程序(例如 Orbit)之间创建一个点对点的安全网络覆盖层。这种点对点覆盖层会在 Spot 现有的互联网连接之上创建一个虚拟网络。这样做的好处在于增加了一层安全保障,确保机器人仅连接到受信任的端点,并且所有通信都使用行业领先的协议进行加密,即使底层网络遭到入侵,连接仍然安全。
对于移动机器人而言,自动连接叠加层至关重要,它意味着即使底层网络和地址发生变化,Orbit 等应用程序也能始终通过唯一的虚拟地址连接到 Spot。例如,Spot 在 Wi-Fi 网络上的 IP 地址可能突然从 192.168.1.37 变为 192.168.1.38,但 Orbit 连接的虚拟叠加层地址始终为 100.0.0.37。用户不再需要配置网络来为 Spot 分配稳定的地址。事实上,他们甚至无需知道 Spot 的 IP 地址。即使 Spot 需要连接到路由器后面的设备(该路由器为多个设备共享一个地址),叠加层也能建立并维护这个唯一的虚拟地址。
将 Spot 连接到点对点覆盖网络也简化了防火墙配置要求。对于网络防火墙而言,自动连接流量看起来就像是连接到同一个网站(Orbit)的单个加密连接,而实际上,该连接包含多个数据流,用于在 Spot 和 Orbit 之间传输所有数据。现在,Spot 只需一条简单的防火墙规则即可连接(在许多情况下,该规则默认允许)。
除了提供网络地址的抽象层之外,自动连接功能还能在不同网络之间无缝切换,而不会中断与数据采集服务或操作员的连接。这是通过监控机器人状态和可用网络,并将流量无缝切换到最佳可用网络来实现的。从 Orbit 软件或操作员的角度来看,虚拟网络层保持不变。数据继续传输,命令或任务计划继续执行。但在后台,Spot 会感知到何时停靠在对接台上,可以使用更可靠的有线连接;或者检测到 Wi-Fi 网络信号变弱,并切换到 5G 蜂窝网络以保持连接。这种机制能够应对短暂的网络故障,从而适应数据偶尔丢失的典型环境。用户可以配置优先级列表,以便在有多个可用网络时选择要使用的网络。
正如我们所见,自动连接功能使 Spot 在全球复杂环境中运行时更具价值和可靠性。自动连接功能使 Spot 能够在以前无法实现的情况下可靠地发送数据。无需再进行复杂的防火墙例外设置、静态 IP 地址或始终可用的单一网络连接,自动连接功能让机器人操作员和设施管理员能够专注于最重要的事情——操作机器人并查看其生成的数据洞察

















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









