






 本文介绍如何使用朴素贝叶斯算法创建一个中文文本分类器,并通过实际案例演示如何将其应用于中文邮件分类任务。
本文介绍如何使用朴素贝叶斯算法创建一个中文文本分类器,并通过实际案例演示如何将其应用于中文邮件分类任务。
本文将用朴素贝叶斯原理做一个中文文本分类器。朴素贝叶斯完全可以胜任多分类任务。为了方便,这里就先做个2分类的。理论部分:https://blog.youkuaiyun.com/montecarlostyle/article/details/79870860
我们事先准备两类中文邮件,一类是有些报刊编辑发的征稿广告,另一类是一些支付信息(正常通信的邮件太少了,不好找)。
我们的目的
有了理论准备之后,我们知道,如果要完成一个新邮件的预测,我就必须要先知道两种(注意不是两个)概率:
P(Y=ci)和P(X(j)=x(j)|Y=ci).
P
(
Y
=
c
i
)
和
P
(
X
(
j
)
=
x
(
j
)
|
Y
=
c
i
)
.
至于这个公式怎么来的,理论部分有推到,这里就不再赘述了。
如果这个邮件是这个样子的:“我是XX编辑,我现在征XXX稿。……”。那么在我们这个例子里,
P(Y=c1)
P
(
Y
=
c
1
)
=P(随便从测试集抽取一个邮件,它的类别 == 征稿广告),
P(Y=c2)
P
(
Y
=
c
2
)
=P(随便从测试集抽取一个邮件,它的类别 == 支付信息);还有在两个类别下,邮件特征出现的概率:
P(X(j)=x(j)|Y=c1)
P
(
X
(
j
)
=
x
(
j
)
|
Y
=
c
1
)
=P(“我是XX编辑,我现在征XXX稿。……” | 这篇邮件是征稿广告),
P(X(j)=x(j)|Y=c2)
P
(
X
(
j
)
=
x
(
j
)
|
Y
=
c
2
)
=P(“我是XX编辑,我现在征XXX稿。……” | 这篇邮件是支付信息)。
有了这两类概率,我们对比P(“我是XX编辑,我现在征XXX稿。……” | 这篇邮件是征稿广告)*P(随便从测试集抽取一个邮件,它的类别 == 征稿广告)与$P(“我是XX编辑,我现在征XXX稿。……” | 这篇邮件是支付信息)*P(随便从测试集抽取一个邮件,它的类别 == 支付信息)的概率,哪个概率大,我们就把这个文本分到哪一类。
把整个文本拆成词组成的列表
问题来了,每个人写的句子风格都不一样,很少有两个句子每个字都相同,直接统计句子的出现频率是不行的。这就需要再把邮件细化,但是中文又不同与英文,中文一个词与另一个词之间没有空格分隔。这个时候,就需要分词了。这里不手动分词,而使用bosonnlp,它可以达到98%的分词正确率。需要去官网注册帐号,注册并不是很麻烦。具体使用方法请看官方文档。分词完成之后,还需要对文本进行清洗,去除其中的符号空格和换行符。我们用zhon库导出中文标点,然后再用正则表达式匹配去除。分词例子:“我是XX编辑,我现在征XX稿”结果是[“我”, “是”, “XX”,“编辑”, “我”, “现在”, “征”, “XXX”, “稿”]。这样我们就有了更精细的“词”作为特征来计算条件概率了。
生成词集,把文本转化成向量
如果给我们一篇中文文本,使用刚才的方法,我们可以得到一个由很多次组成的列表。例如[“我”, “是”, “XX”,“编辑”, “我”, “现在”, “征”, “XXX”, “稿”],我们要计算条件概率P(“我是XX编辑,我现在征XX稿。……” | 这篇邮件是征稿广告)就变成了P(“我”,”是”,”XX”,”编辑”,“我”,”现在”,”征”,”XXX”,”稿”|这篇邮件是征稿广告)。我们看到,”我”词出现了两次。接下来,特征表述有两个思路,一个是只考虑“我”,“是”等词出现与否,出现计1,不出现计0;另一个思路是考虑这些词的出现次数。
1.生成词集,结果:[“我”, “是”, “XX”,“编辑”, “现在”, “征”, “XXX”, “稿”]。
2.我们采用第二种方式,考虑词的出现频率。文本就变成了[2, 1, 1, 1, 1, 1, 1, 1]
实战中,词集需要根据很多很多文本的词生成。所以,某个文本的向量里很大几率有0的存在。这里我们使用拉普拉斯平滑,把每个词出现的频率统一拉高1次。
把文本向量组成矩阵,计算每个词出现的频率
为了方便操作,这里使用numpy库。我们接着把所有某类文本向量一行一行叠加,形成矩阵。再纵向相加,就能得到每个词的出现频次了(结果是一个行向量)。这个频数再除以这一类邮件所有词出现的总次数,就能得到某个特征出现的条件概率(还是个行向量),为了防止多个较小的概率相乘得到接近0的数,我们对概率取log对数,不影响最终结果。剩下的就剩乘法操作啦。
我们看一下程序的运行结果
from naiveBayes import *
p1Vec, p2Vec, wordSet, pAbusive = bayesTrain(‘email/T/’, ‘email/F/’)
bayesClass(p1Vec, p2Vec, wordSet, pAbusive, ‘email/test1.txt’)
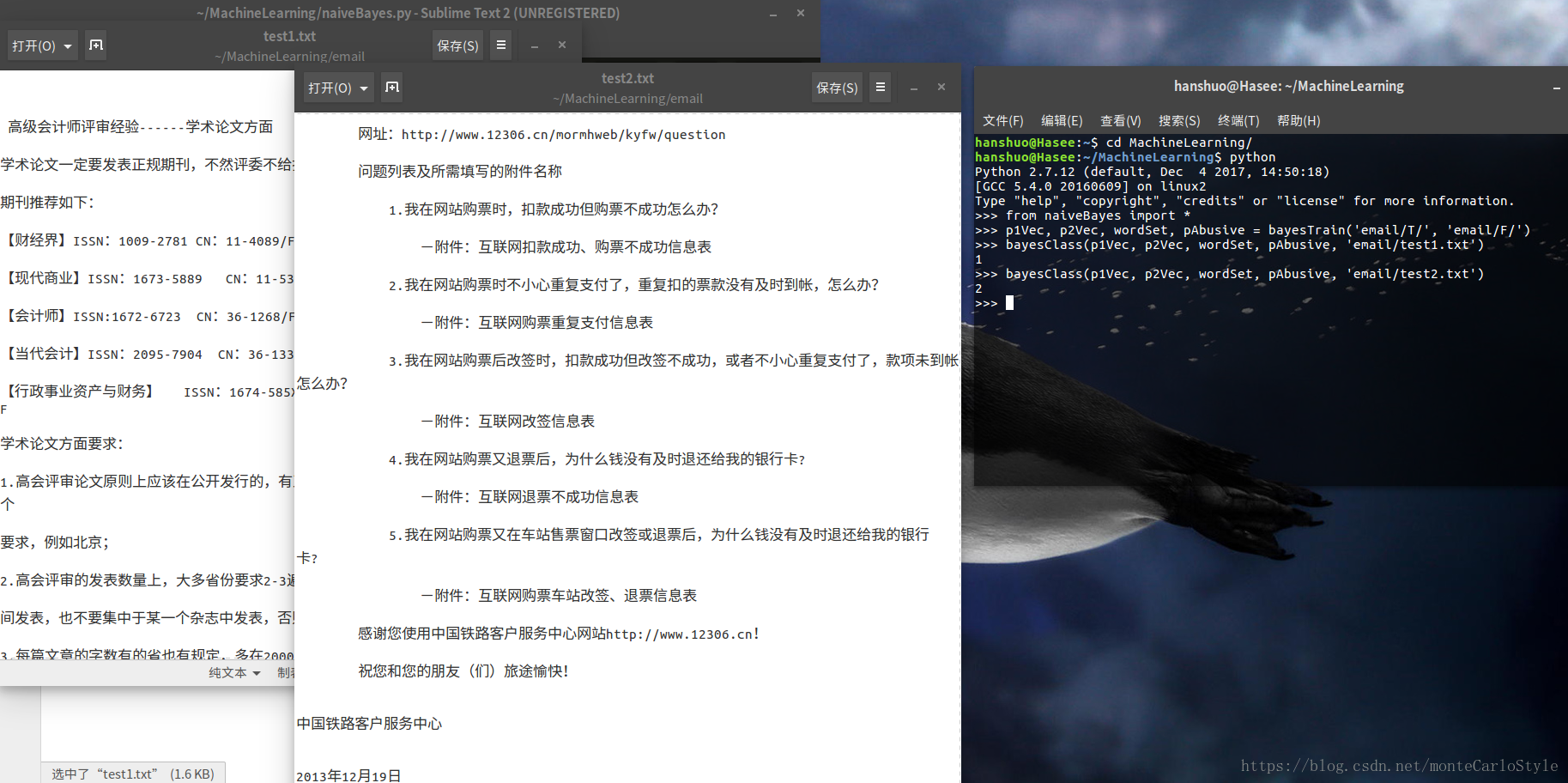
没统计错误率,两类训练邮件加起来才10封。看起来效果还不错…
#-----------------------------------------------------
# function:Naive Bayes chinese text classifier
# author:hanshuo
# date:2018-4-11
# tools:Python 2.7.6 numpy bosonnlp zhon
# system:linux or Windows
# extra:Text separation service from Bosonnlp
#-----------------------------------------------------
#-*- encoding: utf-8 -*-
from __future__ import print_function, unicode_literals
from bosonnlp import BosonNLP
import re
from zhon.hanzi import punctuation
import numpy as np
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def textGet(fileName):
f = open(fileName)
text = f.read()
return text.strip().strip('\n')
def bossonDivide(text):
#也可以不使用boson,需要替换为其他分词函数
nlp = BosonNLP('replace with your boson key')
#这儿需要把'replace with your boson key'换成你帐号的boson key
result = nlp.tag(text, space_mode = 0, oov_level = 3, t2s = 1, special_char_conv = 1)
wordList = []
for d in result:
wordList.append(d['word'])
listOfWords = []
for eachList in wordList:
listOfTokens = []
for eachWord in eachList:
listOfTokens.append(re.sub(ur"[%s]+" %punctuation, "", eachWord))
listOfWords.append([eachWord for eachWord in listOfTokens if eachWord != ''])
return listOfWords
def textTrain(class_1Texts, class_2Texts):
#输入两类文本,类型为嵌套列表。输出两个文本矩阵,一个词集
pass
wordSet = []
listOfTrain1 = []
listOfTrain2 = []
for eachText in class_1Texts:
textVec = [0] * len(wordSet)
for word in eachText:
if word in wordSet:
textVec[wordSet.index(word)] += 1
else:
wordSet.append(word)
textVec.append(1)
listOfTrain1.append(textVec)
for eachText in class_2Texts:
textVec = [0] * len(wordSet)
for word in eachText:
if word in wordSet:
textVec[wordSet.index(word)] += 1
else:
wordSet.append(word)
textVec.append(1)
listOfTrain2.append(textVec)
numOfWords = len(wordSet)
for everyRow in listOfTrain1:
everyRow.extend([0] * (numOfWords - len(everyRow)))
for everyRow in listOfTrain2:
everyRow.extend([0] * (numOfWords - len(everyRow)))
arrayOfTrain1 = np.array(listOfTrain1)
arrayOfTrain2 = np.array(listOfTrain2)
return arrayOfTrain1, arrayOfTrain2, wordSet
def bayesTrain(filePath_1, filePath_2):
#输入两个文件夹集合,每个文件夹存放一类文本,无视文件名称。输出:两个条件概率向量,一个词集,一个正例文本比例
from os import listdir
file_1Names = listdir(filePath_1)
file_2Names = listdir(filePath_2)
text_1Raw = []
text_2Raw = []
for eachFile in file_1Names:
text_1Raw.append(textGet(filePath_1 + eachFile))
for eachFile in file_2Names:
text_2Raw.append(textGet(filePath_2 + eachFile))
text_1 = bossonDivide(text_1Raw)
text_2 = bossonDivide(text_2Raw)
#return texts_1, texts_2
array_1Train, array_2Train, wordSet = textTrain(text_1, text_2)
p1Num = np.ones(len(wordSet))
p2Num = np.ones(len(wordSet))
p1Denom = 2.0
p2Denom = 2.0
p1Num = array_1Train.sum(axis = 0) + p1Num
p2Num = array_2Train.sum(axis = 0) + p2Num
p1Denom += p1Num.sum()
p2Denom += p2Num.sum()
p1Vec = np.log(p1Num/p1Denom)
p2Vec = np.log(p2Num/p2Denom)
pAbusive = len(file_1Names) / float(len(file_1Names)+len(file_2Names))
return p1Vec, p2Vec, wordSet, pAbusive
def classifyNB(vec2Classify,p1Vec,p2Vec,pClass1):
#输入待测文本向量,两个条件概率向量,一个正例比例。输出文本的测试类别
p1=sum(vec2Classify*p1Vec)+np.log(pClass1)
p2=sum(vec2Classify*p2Vec)+np.log(1.0-pClass1)
if p1>p2:
return 1
else:
return 2
def bayesClass(p1Vec, p2Vec, wordSet, pAbusive, testTextName):
#输入两个条件概率向量,一个词集,正例比例,待测文本文件名。函数会打印出这个文本的测试类别
testTextVec = [0] * len(wordSet)
testText = textGet(testTextName)
testWordList = bossonDivide(testText)[0]
for word in testWordList:
if word in wordSet:
testTextVec[wordSet.index(word)] += 1
arrayTest = np.array(testTextVec)
c = classifyNB(arrayTest, p1Vec, p2Vec, pAbusive)
print(c)

















 3515
3515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









