




pytorch
已经成为最炙手可热的深度学习框架之一,非常有必要学习
入门
常见形式
scalar: 常量
from torch import tensor
x = tensor(32,)
print tensor(32,)
vector: 向量(特征)
x = tensor([32,32,1,2,3]) 类似一个特征向量
matrix: 表示矩阵,通常是多维的
tensor([[1, 2, 3, 4], [2 ,3, 34,4]])

高维的
与numpy 的高维一样
线性回归案例
import numpy as np
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1, 1)
y_values = [2 * i + 1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
import torch.nn as nn
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, out_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, out_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = 1; out_dim = 1
model = LinearRegressionModel(input_dim, out_dim)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
epochs = 1000
rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=rate)
criterion = nn.MSELoss()
for epoch in range(epochs):
epoch += 1
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
# 清零梯度
optimizer.zero_grad()
# 前传播
ouput = model(inputs)
# 损失
loss = criterion(ouput, labels)
# 反向
loss.backward()
# 权重参数
optimizer.step()
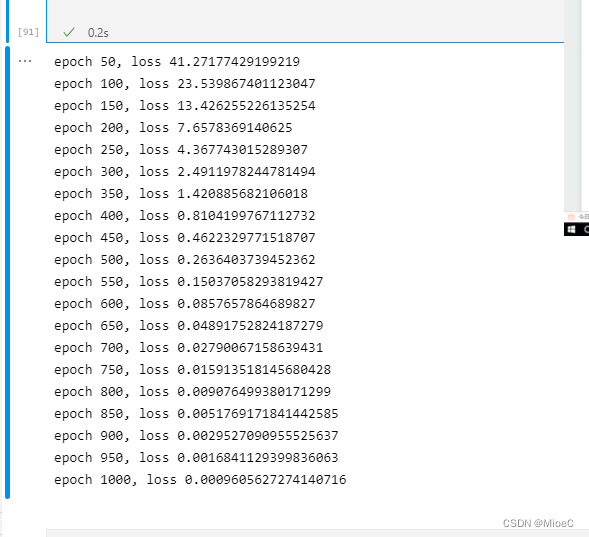
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
模型的保存
torch.save(model.state_dict(), "model.pkl")
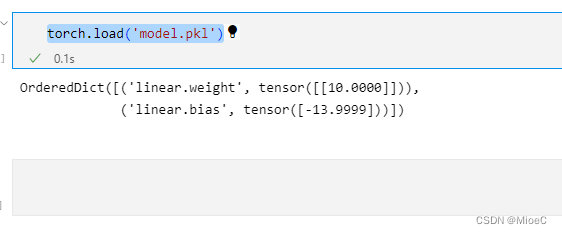
读取
torch.load('model.pkl')
觉得有收获的可以加个微信交流技术
chendongming888888




















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











