




在此前介绍的深度分层强化学习算法中,Option-Critic是同轨策略(On-Policy)算法,它将当前策略与环境交互收集的样本立即用于更新策略,即用即弃,更新准确但数据利用率低;h-DQN和FeUdal Networks是离轨策略(Off-Policy)算法,它们存储整个学习过程中产生的经验,并随时利用其中的小批量来更新策略,数据利用率高,但是会用旧策略的数据更新新策略,带来行为策略和目标策略不匹配的问题。然而h-DQN和FeUdal Networks并没有采用重要度采样方法来纠正这一偏差,因为高层策略的重要度采样极其困难:
- 高层目标的回报同时受制于高层策略和低层策略的影响;
- 低层策略的同时学习对于高层策略而言破坏了旧数据和新数据之间的相关性,这不符合重要度采样的基本假设;
- 高层策略的一次决策会覆盖多个时间步,这使得重要度采样中累乘的计算会带来巨大的方差,一个微小的概率差异可能会产生数值爆炸或消失。
HIRO
HIRO(Hierarchical Reinforcement learning with Off-policy correction,带离策略校正的分层强化学习)专注于解决低层策略持续更新为高层策略训练带来的偏差问题,其核心在于利用离策略校正机制,让高层策略能够更有效地复用低层策略的经验,为重要度采样提供了一种实用的替代方案。
策略架构与低层策略训练
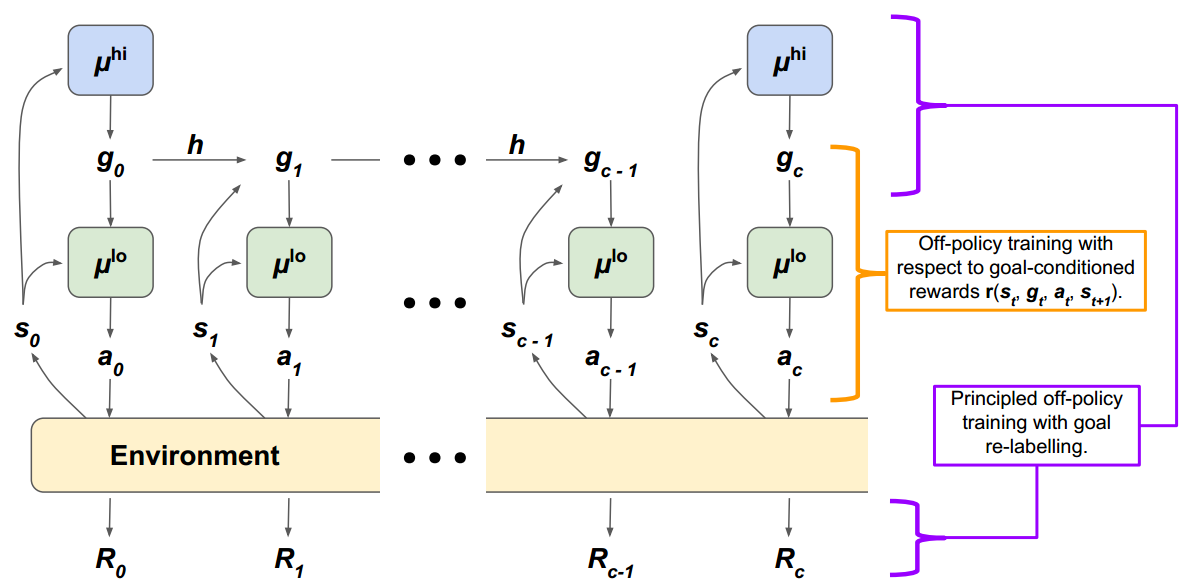
HIRO采用双层策略架构,由低层策略μlo\mu^{lo}μlo和高层策略μhi\mu^{hi}μhi组成。在每个时间步ttt:
- 高层策略μhi\mu^{hi}μhi观测环境状态sts_tst,并且每ccc个时间步采样目标gt∼μhig_t\sim\mu^{hi}gt∼μhi,其他时间步的目标则来自一个目标转换函数gt=h(st−1,gt−1,st)g_t=h(s_{t-1},g_{t-1},s_t)gt=h(st−1,gt−1,st);
- 低层策略μlo\mu^{lo}μlo观测状态sts_tst和目标gtg_tgt,并采样动作at∼μlo(st,gt)a_t\sim\mu^{lo}(s_t,g_t)at∼μlo(st,gt);
- 环境从奖励函数R(st,at)R(s_t,a_t)R(st,at)中采样奖励RtR_tRt,并转移到从状态转移函数f(st,at)f(s_t,a_t)f(st,at)采样的新状态st+1s_{t+1}st+1。
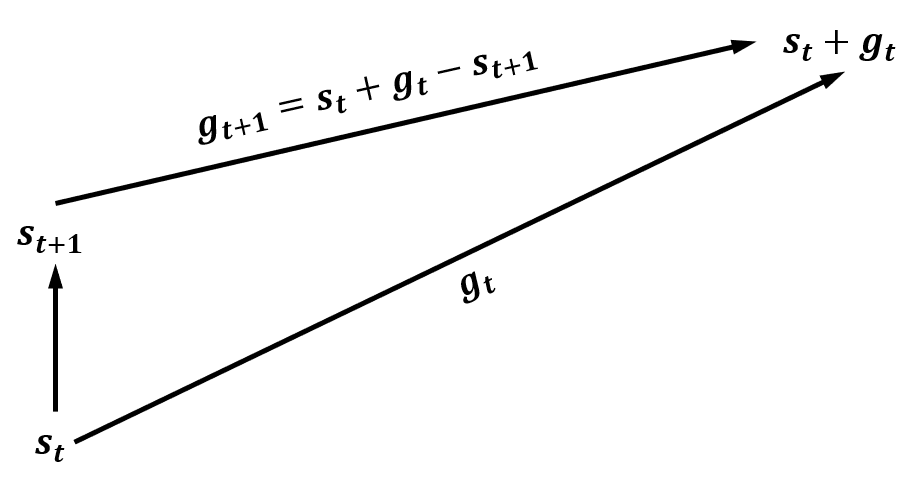
与FuN类似,HIRO的目标gtg_tgt被定义为期望的状态变化量。即在高层策略决策点,对于当前状态sts_tst和高层策略产生的目标gtg_tgt,高层控制器希望低层控制器采取动作,使ccc步之后的状态st+cs_{t+c}st+c尽可能接近st+gts_t+g_tst+gt。而在此期间,为了保证目标指向的状态固定,目标转换函数的定义为
gt+1=h(st,gt,st+1)=st+gt−st+1 g_{t+1}=h(s_t,g_t,s_{t+1})=s_t+g_t-s_{t+1} gt+1=h(st,gt,st+1)=st+gt−st+1
相应地,低层策略的内部奖励被设置为负的当前状态与目标状态之间的距离
r(st,gt,at,st+1)=−∥st+gt−st+1∥2 r(s_t,g_t,a_t,s_{t+1})=-\|s_t+g_t-s_{t+1}\|_2 r(st,gt,at,st+1)=−∥st+gt−st+1∥2
HIRO仅使用内部奖励,采用与DDPG或TD3相同的确定性策略训练范式训练低层策略。低层策略的Critic网络使用如下TD误差作为梯度更新参数(以DDPG为例,Qθlo′Q_\theta^{lo}{'}Qθlo′为目标网络)
r(st,gt,at,st+1)+γQθlo′(st+1,gt+1,μϕlo(st+1,gt+1))−Qθlo(st,gt,at) r(s_t,g_t,a_t,s_{t+1})+\gamma Q_\theta^{lo}{'}(s_{t+1},g_{t+1},\mu_\phi^{lo}(s_{t+1},g_{t+1}))-Q_\theta^{lo}(s_t,g_t,a_t) r(st,gt,at,st+1)+γQθlo′(st+1,gt+1,μϕlo(st+1,gt+1))−Qθlo(st,gt,at)
Actor网络使用确定性策略梯度
∇θJ(μϕlo)=Es∼ρlo[∇θμϕlo(s,g)∇aQlo(s,g,a)∣a=μϕlo(s,g)] \nabla_\theta J(\mu_\phi^{lo})=\mathbb E_{s\sim\rho^{lo}}[\nabla_\theta\mu_\phi^{lo}(s,g)\nabla_aQ^{lo}(s,g,a)|_{a=\mu_\phi^{lo}(s,g)}] ∇θJ(μϕlo)=Es∼ρlo[∇θμϕlo(s,g)∇aQlo(s,g,a)∣a=μϕlo(s,g)]
离策略校正与高层策略训练
HIRO同样使用基于DDPG或TD3的方法训练高层策略,其Critic网络的TD误差为(以DDPG为例)
Rt:t+c−1+γmaxgQϕhi′(st+c,g)−Qϕhi(st,gt) R_{t:t+c-1}+\gamma\underset g{\max{}}Q^{hi}_\phi{'}(s_{t+c},g)-Q^{hi}_\phi(s_t,g_t) Rt:t+c−1+γgmaxQϕhi′(st+c,g)−Qϕhi(st,gt)
但是为了解决重要度采样的问题,HIRO进一步对其所使用的经验样本进行了处理。在HIRO中,用于训练高层策略的原始经验是一个五元组(st:t+c−1,gt:t+c−1,at:t+c−1,Rt:t+c−1,st+c)(s_{t:t+c-1},g_{t:t+c-1},a_{t:t+c-1},R_{t:t+c-1},s_{t+c})(st:t+c−1,gt:t+c−1,at:t+c−1,Rt:t+c−1,st+c),其中xt:t+c−1x_{t:t+c-1}xt:t+c−1表示从ttt到t+c−1t+c-1t+c−1的序列xt,⋯ ,xt+c−1x_t,\cdots,x_{t+c-1}xt,⋯,xt+c−1。
HIRO进行异策略校正的核心思路是,为了在新低层策略的基础上训练高层策略,我们需要修正旧经验中的目标gtg_tgt为g~t\tilde g_tg~t,使得新低层策略根据修正目标g~t\tilde g_tg~t,能够复刻旧低层策略根据原始目标gtg_tgt产生的动作序列at:t+c−1a_{t:t+c-1}at:t+c−1。换言之,我们要将经验中的gtg_tgt替换为g~t\tilde g_tg~t,以最大化概率μlo(at:t+c−1∣st:t+c−1,g~t:t+c−1)\mu^{lo}(a_{t:t+c-1}|s_{t:t+c-1},\tilde g_{t:t+c-1})μlo(at:t+c−1∣st:t+c−1,g~t:t+c−1),这一操作即为离策略校正。后续时间步的目标采用目标转换函数g~t+1=h(st,g~t,st+1)\tilde g_{t+1}=h(s_t,\tilde g_t,s_{t+1})g~t+1=h(st,g~t,st+1)递推得出。修正后的经验变为(st,g~t,Rt:t+c−1,st+c)(s_t,\tilde g_t,R_{t:t+c-1},s_{t+c})(st,g~t,Rt:t+c−1,st+c),无需存储原始动作序列、中间状态和中间目标。
但是HIRO采用了确定性策略作为低层策略,为此HIRO采用以μlo(s,g)\mu^{lo}(s,g)μlo(s,g)为中心的高斯分布随机性策略来近似μlo(s,g)\mu^{lo}(s,g)μlo(s,g),则关于对数概率logμlo(at:t+c−1∣st:t+c−1,g~t:t+c−1)\log\mu^{lo}(a_{t:t+c-1}|s_{t:t+c-1},\tilde g_{t:t+c-1})logμlo(at:t+c−1∣st:t+c−1,g~t:t+c−1)有
logμlo(at:t+c−1∣st:t+c−1,g~t:t+c−1)∝−12∑i=tt+c−1∥ai−μlo(si,g~i)∥22+const \log\mu^{lo}(a_{t:t+c-1}|s_{t:t+c-1},\tilde g_{t:t+c-1})\propto-\frac12\sum^{t+c-1}_{i=t}\|a_i-\mu^{lo}(s_i,\tilde g_i)\|^2_2+\mathrm{const} logμlo(at:t+c−1∣st:t+c−1,g~t:t+c−1)∝−21i=t∑t+c−1∥ai−μlo(si,g~i)∥22+const
即最大化对数概率logμlo(at:t+c−1∣st:t+c−1,g~t:t+c−1)\log\mu^{lo}(a_{t:t+c-1}|s_{t:t+c-1},\tilde g_{t:t+c-1})logμlo(at:t+c−1∣st:t+c−1,g~t:t+c−1)等价于最小化∑i=tt+c−1∥ai−μlo(si,g~i)∥22\sum^{t+c-1}_{i=t}\|a_i-\mu^{lo}(s_i,\tilde g_i)\|^2_2∑i=tt+c−1∥ai−μlo(si,g~i)∥22。我们可以理解为,针对确定性策略,HIRO将动作概率最大化问题转化为了动作输出的均方误差最小化问题。
不过要精确求解这一最小化问题也很复杂,HIRO选择通过近似采样将其工程化。HIRO从10个候选目标中搜索最小化均方误差的局部解,其中有两个确定性候选目标gtg_tgt和st+c−sts_{t+c}-s_tst+c−st,剩余的8个随机候选目标将从以st+c−sts_{t+c}-s_tst+c−st为均值的高斯分布中采样。HIRO基于对问题的认知,将已有的gtg_tgt和st+c−sts_{t+c}-s_tst+c−st作为先验知识,并假设最可能的修正目标大概率位于实际发生的状态变化附近。
通过重要度采样我们可以进一步认识动作重标记的理论基础。在原始的重要度采样方法下,对于产生经验的对应低层行为策略μβlo(ai∣si,gi)\mu_\beta^{lo}(a_i|s_i,g_i)μβlo(ai∣si,gi)和从经验中学习的对应低层目标策略μlo(ai∣si,gi)\mu^{lo}(a_i|s_i,g_i)μlo(ai∣si,gi),我们需要将以行为策略分布的经验通过重要度采样比wtw_twt转换为以目标策略分布
L(θ)=E[(Qθhi(st,gt)−yt)2]yt=∏i=tt+c−1(μlo(ai∣si,gi)p(si+1∣si,ai))[Rt:t+c−1+γmaxgQhi(st+c,g)]yt=∏i=tt+c−1(μβlo(ai∣si,gi)p(si+1∣si,ai))[wt⋅(Rt:t+c−1+γmaxgQhi(st+c,g))]wt=∏i=tt+c−1μlo(ai∣si,gi)μβlo(ai∣si,gi) \begin{split} L(\theta)&=\mathbb E[(Q_\theta^{hi}(s_t,g_t)-y_t)^2]\\ y_t&=\prod^{t+c-1}_{i=t}\Big(\mu^{lo}(a_i|s_i,g_i)p(s_{i+1}|s_i,a_i)\Big)\left[R_{t:t+c-1}+\gamma\underset g{\max{}}Q^{hi}(s_{t+c},g)\right]\\ y_t&=\prod^{t+c-1}_{i=t}\Big(\mu^{lo}_\beta(a_i|s_i,g_i)p(s_{i+1}|s_i,a_i)\Big)\left[w_t\cdot\left(R_{t:t+c-1}+\gamma\underset g{\max{}}Q^{hi}(s_{t+c},g)\right)\right]\\ w_t&=\prod^{t+c-1}_{i=t}\frac{\mu^{lo}(a_i|s_i,g_i)}{\mu^{lo}_\beta(a_i|s_i,g_i)} \end{split} L(θ)ytytwt=E[(Qθhi(st,gt)−yt)2]=i=t∏t+c−1(μlo(ai∣si,gi)p(si+1∣si,ai))[Rt:t+c−1+γgmaxQhi(st+c,g)]=i=t∏t+c−1(μβlo(ai∣si,gi)p(si+1∣si,ai))[wt⋅(Rt:t+c−1+γgmaxQhi(st+c,g))]=i=t∏t+c−1μβlo(ai∣si,gi)μlo(ai∣si,gi)
而行为重标记相当于修正目标策略分布中的gig_igi为g~i\tilde g_ig~i,使得重要度采样比近似为111
wt=∏i=tt+c−1μlo(ai∣si,g~i)μβlo(ai∣si,gi)≈1 w_t=\prod^{t+c-1}_{i=t}\frac{\mu^{lo}(a_i|s_i,\tilde g_i)}{\mu^{lo}_\beta(a_i|s_i,g_i)}\approx1 wt=i=t∏t+c−1μβlo(ai∣si,gi)μlo(ai∣si,g~i)≈1
相当于找到g~i\tilde g_ig~i以最小化wtw_twt与111的误差
g~t=argmingt(1−∏i=tt+c−1μlo(ai∣si,gi)μβlo(ai∣si,gi)) \tilde g_t=\arg\underset{g_t}{\min{}}\left(1-\prod^{t+c-1}_{i=t}\frac{\mu^{lo}(a_i|s_i,g_i)}{\mu^{lo}_\beta(a_i|s_i,g_i)}\right) g~t=arggtmin(1−i=t∏t+c−1μβlo(ai∣si,gi)μlo(ai∣si,gi))
对右侧取对数
g~t=argmingt(∑i=tt+c−1(logμlo(ai∣si,gi)−logμβlo(ai∣si,gi))) \tilde g_t=\arg\underset{g_t}{\min{}}\left(\sum^{t+c-1}_{i=t}\Big(\log\mu^{lo}(a_i|s_i,g_i)-\log\mu^{lo}_\beta(a_i|s_i,g_i)\Big)\right) g~t=arggtmin(i=t∑t+c−1(logμlo(ai∣si,gi)−logμβlo(ai∣si,gi)))
该优化目标与行为重标记相符。由于不能保证存在g~t\tilde g_tg~t使得损失函数为零,因此该估计是有偏的,但在工程中可以接受,且换来了训练所需的稳定性和低方差。
算法流程
现在我们可以得出HIRO的算法伪代码如下:
(原论文没有给出伪代码,博主自行给出,仅供参考。DDPG和TD3相关细节省略)
- 初始化:
- 高层策略μϕhi\mu^{hi}_\phiμϕhi及其Critic网络QθhiQ^{hi}_\thetaQθhi;
- 低层策略μϕlo\mu^{lo}_\phiμϕlo及其Critic网络QθloQ^{lo}_\thetaQθlo;
- 目标网络μϕhi′←μϕhi\mu^{hi}_\phi{}'\leftarrow\mu^{hi}_\phiμϕhi′←μϕhi,Qθhi′←QθhiQ^{hi}_\theta{}'\leftarrow Q^{hi}_\thetaQθhi′←Qθhi,μϕlo′←μϕlo\mu^{lo}_\phi{}'\leftarrow\mu^{lo}_\phiμϕlo′←μϕlo,Qθlo′←QθloQ^{lo}_\theta{}'\leftarrow Q^{lo}_\thetaQθlo′←Qθlo;
- 超参数:高层决策间隔ccc,经验回放缓冲区Dhi,Dlo\mathcal D_{hi},\mathcal D_{lo}Dhi,Dlo,软更新速率τ\tauτ。
- 对每一幕循环:
- 初始化状态s0s_0s0;
- 高层策略采样初始目标g0∼μϕhi(s0)g_0\sim\mu^{hi}_\phi(s_0)g0∼μϕhi(s0);
- 对每个时间步ttt循环:
- 低层策略执行动作at∼μϕlo(st,gt)+N(0,σlo)a_t\sim\mu^{lo}_\phi(s_t,g_t)+\mathcal N(0,\sigma_{lo})at∼μϕlo(st,gt)+N(0,σlo)(高斯噪声探索);
- 观测到奖励RtR_tRt和后继状态st+1s_{t+1}st+1;
- 计算内在奖励rtr_trt;
- 计算后继目标gt+1g_{t+1}gt+1;
- 将低层经验(st,gt,at,rt,st+1,gt+1)(s_t,g_t,a_t,r_t,s_{t+1},g_{t+1})(st,gt,at,rt,st+1,gt+1)存入缓存区Dlo\mathcal D_{lo}Dlo;
- 从Dlo\mathcal D_{lo}Dlo采样一个批次经验,根据DDPG或TD3的更新规则更新μϕlo\mu^{lo}_\phiμϕlo和QθloQ^{lo}_\thetaQθlo;
- 软更新目标网络μϕlo′\mu^{lo}_\phi{}'μϕlo′和Qθlo′Q^{lo}_\theta{}'Qθlo′;
- 如果t+1%c=0t+1\%c=0t+1%c=0:
- 计算当前段总奖励Rt−c+1:tR_{t-c+1:t}Rt−c+1:t;
- 将高层经验(st−c+1,gt−c+1,at−c+1:t,Rt−c+1:t,st)(s_{t-c+1},g_{t-c+1},a_{t-c+1:t},R_{t-c+1:t},s_{t})(st−c+1,gt−c+1,at−c+1:t,Rt−c+1:t,st)存入缓存区Dhi\mathcal D_{hi}Dhi;
- 高层策略采样目标gt+1∼μϕhi(st+1)g_{t+1}\sim\mu^{hi}_\phi(s_{t+1})gt+1∼μϕhi(st+1)。
- 从Dhi\mathcal D_{hi}Dhi采样一个批次经验,修正为(st−c+1,g~t−c+1,Rt−c:t,st)(s_{t-c+1},\tilde g_{t-c+1},R_{t-c:t},s_{t})(st−c+1,g~t−c+1,Rt−c:t,st)(原始经验保留,修正经验更新后丢弃);
- 使用修正后的经验批次,根据DDPG或TD3的更新规则更新μϕhi\mu^{hi}_\phiμϕhi和QθhiQ^{hi}_\thetaQθhi;
- 软更新目标网络μϕhi′\mu^{hi}_\phi{}'μϕhi′和Qθhi′Q^{hi}_\theta{}'Qθhi′。

















 2312
2312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









