



为什么需要线程同步?
线程同步:即线程按照一定的顺序执行。
在java中,当我们运行多个线程的时候,线程可能会对同一个数据、文件、内存进行读写操作,读操作我们是允许多个线程共同进行的,但是写操作确会让这几个线程产生冲突。此时我们就说这几个线程存在竞争关系,这种竞争关系我们如果不及时处理的话,会产生未知错误。竞争产生究其根本是因为我们对线程是不可控的,但是虽然线程不可控,我们却可以用一些方法让线程按一定的顺序去执行某项操作,所以我们需要进行线程同步。
接下来我们介绍几种实现线程同步的方法:
一、synchronized关键字
synchronized代表加锁,用synchronized修饰的代码,会被加上一个内置锁,用来保护该段代码,该段代码运行时这个锁加上,运行结束后该锁被释放。
synchronized可以修饰方法也可以修饰代码块。
1、修饰方法:很简单,在返回类型前加上synchronized关键字就行。
public class Select implements Runnable{
static int i=0;
public synchronized void test(){
System.out.println("当前线程为:"+i);
i++;
}
public void run(){
test();
}
public static void main(String[] args){
Select se = new Select();
for(int f=0 ; f<10 ; f++){
Thread thread = new Thread(se);
thread.start();
}
}
}
运行结果:

从结果中我们可以看出,test方法已经被顺序执行了,只有当某线程执行完i++,下一个线程才会执行test。
关于synchronized,有个需要注意的点,请看下面代码:
public class Select implements Runnable{
static int i=0;
public synchronized void test(){
System.out.println("当前线程为:"+i);
i++;
}
public void run(){
test();
}
public static void main(String[] args){
for(int f=0 ; f<10 ; f++){
Select se = new Select();
Thread thread = new Thread(se);
thread.start();
}
}
}
返回结果:

可见上述代码并没有实现同步,这是为什么?因为run()虽然被锁上了,但synchronized是不能锁住不同对象的线程的,换言之synchronized锁住的同一对象的多个线程。
总而言之,synchronized锁住的是方法或块中的数据,而不是对象。
2、修饰代码块
synchronized(object){
}
通过上述语句,我们可以将需要加锁的代码放入大括号内,对代码进行加锁,下列语句:
public void method(){
synchronized(this){
}
}
是等价于给方法加锁的。
注意:用synchronized加锁会造成资源和时间的耗费,要加锁尽量不要加在方法上,而是加在关键代码上。
二、wait()和notify()
wait():是暂停线程,让线程处于阻塞状态,同时释放锁。
notify():是唤醒一个处在阻塞状态的线程,让处于阻塞状态的线程变为就绪状态,同时加锁。注意:调用此方法的时候只唤醒一个线程,同时唤醒的不是某一确切进程,唤醒的进程由JVM确定。
notifyAll():唤醒所有处于阻塞状态的线程。注意:并不是给所有的线程加锁,而是让它们处于竞争。
注:wait(),notify()和notifyAll()是object中的方法。
我们用经典的哲学家吃饭问题来了解一下。
哲学家吃饭问题:n个哲学家围成一桌,每个人左右各一支筷子,共n个筷子,哲学家在不吃饭的时候就是思考,设计算法让哲学家们都吃到饭,并模拟这个过程。
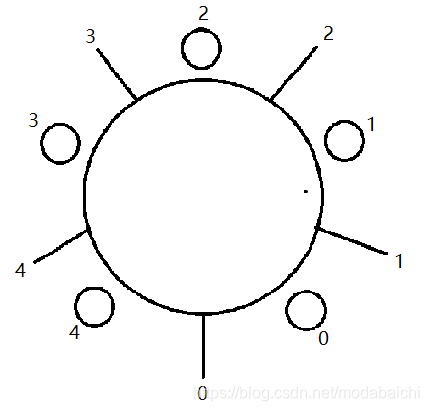
上图圆圈为哲学家,直线为筷子。假设有5个哲学家,我们将哲学家和筷子进行编号,哲学家左边的筷子和哲学家的编号相同。哲学家有吃和思考两种动作,即两种方法eating和thinking。那我们将每个哲学家都看作是一个线程,筷子放在一个数组内,该数组类型为boolean,初始值为false,即没有被使用。当编号为n的哲学家在吃饭的时候,他需要拿起编号为n和(n+1)%5的筷子,即将这两个筷子置为true。
所以我们设计两个类,首先是哲学家类:
public class Philosopher implements Runnable{
Fork f; //筷子
public Philosopher(Fork f){
this.f = f;
}
public void run(){
f.usefork(); //使用筷子
eating(); //吃饭
f.putfork(); //放下筷子
thinking(); //思考
}
public void eating(){
try {
Thread.sleep(1000); //模拟吃饭过程
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void thinking(){
try {
Thread.sleep(1000); //模拟思考过程
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
每个哲学家是一个线程,该线程启动后,哲学家拿起筷子开始吃饭,吃完后放下筷子开始思考。
显然哲学家们竞争的资源是筷子,筷子自身有正在被使用和没有被使用两种状态。筷子就存在拿起筷子和放下筷子两种方法,我们在编号为n的哲学家拿起筷子的时候先要判定,只有当编号为n和(n+1)%5的筷子都为false的时候才能拿起,否则就wait()。当吃完以后,放下筷子后,便noticyAll(),唤醒其他在wait的哲学家,这些哲学家重新检查周围的筷子是否为false。
下面是筷子类:
public class Fork {
//五只筷子
public Boolean[] fork = {false,false,false,false,false};
public static void main(String[] args){
Fork f = new Fork();
Philosopher phi = new Philosopher(f);
//赋予线程号,相当于赋予哲学家编号。
new Thread(phi , "0").start();
new Thread(phi , "1").start();
new Thread(phi , "2").start();
new Thread(phi , "3").start();
new Thread(phi , "4").start();
}
//同时拿起筷子
public synchronized void usefork(){
String name = Thread.currentThread().getName();
int i = Integer.parseInt(name);
while(fork[i]||fork[(i+1)%5]){
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("I'm eating:"+Thread.currentThread().getName());
//拿起筷子
fork[i] = true;
fork[(i+1)%5] = true;
}
//同时放下筷子
public synchronized void putfork(){
String name = Thread.currentThread().getName();
int i = Integer.parseInt(name);
//放下筷子
System.out.println("I'm thinking:"+Thread.currentThread().getName());
fork[i] = false;
fork[(i+1)%5] = false;
notifyAll();
}
}
运行结果:

三、volatile关键字
我们知道synchronized是重量锁,因为它将整个代码块堵塞了,易造成资源的浪费。而volatile是轻量锁,它用来修饰变量。来看下面这段代码:
boolean value=false;
--------------线程2-------------
public void change(){
value=true;
}
--------------线程1--------------
public void output(){
if(value==true)
System.out,println("输出成功");
}
上述代码,value是两个线程共有的变量,假设先执行线程2再执行线程1,是否一定会输出成功呢?这还真不一定。我们都知道在单线程中如果,按照顺序执行这两个方法,最后一定会输出成功。但多线程不是这样的。
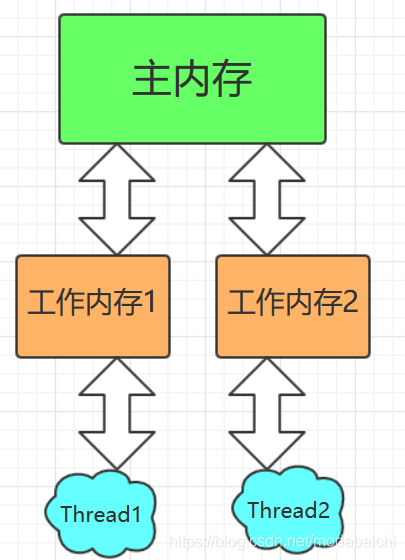
上图表明,线程执行时,数据都是从主内存(main memory)中读出,但它们自身还存在一个工作内存。线程数据读出和写入流程是:线程从主内存中读取数据,然后传到自身的工作内存中,工作内存在传递到线程中使用。线程更改数据后,再按原路经过工作内存将数据写入主内存。在这个过程中就存在一个问题,线程1从主存中读入数据以后,将数据更改传输到工作内存中,工作内存还没有来的及将数据返还给主内存,线程2就开始读取该数据,此时我们可以说两个线程对该数据不具有可见性。
可见性:指线程对于数据的更改对于其他线程来说是可以看到这个修改的数据的。
volatile就可以用来处理线程间数据不可见的问题。被volatile修饰的变量对于线程来说是可见的。简单说一下为什么数据可见了:
1、被volatile修饰的变量在被线程改变以后,会跳过工作内存直接写入到主内存中去。
2、被volatile修饰的变量在线程2被修改时,线程1中关于该变量所在的缓存行被认为是无效的。
3、线程1关于该变量的缓存行被人物无效,没有办法只有返回主内存重新读取该变量。
但不要以为有了volatile就能完全放心了,请看下面代码。
public class Test implements Runnable{
volatile int value=0;
volatile int count=0;
void increase(){
value++;
}
public void run(){
for(int f=0 ; f<100000 ; f++)
increase();
count++;
}
public static void main(String[] args){
Test test = new Test();
for(int i=0 ; i<5 ; i++){
Thread thread = new Thread(test);
thread.start();
}
while(test.count!=5);
System.out.println(test.value);
}
}
上述代码我们总共开了5个线程,每个线程对value值循环加1,按理说会输出500000,但看运行结果。
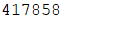
原因在于volatile并不能满足原子性。
原子性:指一个操作或多个操作要么在执行的时候不被打断,要么就不执行。只有最简单的操作才满足原子性,即赋值和读取。
听起来简单,但理解起来其实不易,举个例子。
int a=1;
int b=a;
a++;
上面这三个语句只有第一句满足原子性。
a=1:只有一个操作,将a赋值为1。
b=a:两个操作,读取a的值,将b进行赋值。这两个操作都是原子性操作,但加在一起就不满足。
a++:等价于a=a+1,分三步操作,读取原始a的值,进行加1操作,赋值操作。不满足原子性
注意:long和double型的变量是64位的,它们的赋值不满足原子性。
了解了原子性我们想想为什么之前代码的结果不是500000。因为value的递增不是原子操作,volatile是无法保证原子性的。我们可以假设有这种情况,当value为100时线程1执行value自增的时候,比如说进行到了加1操作后被阻塞了,线程2接着进行value自增,线程2在主存中读取value值时会发现value还是100,那么线程1和线程2执行的结果都是101,相当于两次自增后value确只增加1,这就造成了实际值比500000小。
事实上,volatile还有一个作用,就是禁止JVM进行重排序。
四、Lock
使用synchronized的时候,我们只知道有加锁和释放锁,但却不知在哪里做了这些事情,因为没有一个清晰的表述,JDK5之后就提供了一个新的加锁办法Lock,另外Lock中也提供了有没有成功的获得锁,Lock拥有比synchronized更加多的加锁功能。
使用Lock时注意两点:
1)synchronized是Java的关键字,因此是Java的内置特性,是基于JVM层面实现的。而Lock是一个Java接口,是基于JDK层面实现的,通过这个接口可以实现同步访问;
2)采用synchronized方式不需要用户去手动释放锁,当synchronized方法或者synchronized代码块执行完之后,系统会自动让线程释放对锁的占用;而 Lock则必须要用户去手动释放锁,如果没有主动释放锁,就有可能导致死锁现象。
看下面的代码:
public class Test implements Runnable{
Lock lock = new ReentrantLock();
public void run(){
lock.lock();
try{
String name=Thread.currentThread().getName();
for(int i=0 ; i<5 ;i++){
System.out.println("线程"+name+":"+i);
}
}catch(Exception e){
}
finally{
lock.unlock();
}
}
public static void main(String[] args){
Test test = new Test();
Thread thread1 = new Thread(test,"1");
thread1.start();
Thread thread2 = new Thread(test,"2");
thread2.start();
}
}
运行结果:

可以看出线程按顺序执行了。我们一般将锁住的方法放入try…catch…语句中,然后在finally中释放锁。同时需要注意的是,和synchronized一样,声明的Lock对象必须对于两个线程来说是同一个,不然,相当于各自加了各自的锁,而不是同一把锁。
五、ThreadLocal类
该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。ThreadLocal 实例通常是类中的 private static 字段,它们希望将状态与某一个线程相关联。 相当于对于ThreadLocal变量,每个线程在执行的时候会将该变量copy一份作为局部变量自己用。用这种方式实现线程同步。
public class Test implements Runnable{
private static ThreadLocal<Integer> value = new ThreadLocal<Integer>(){
protected Integer initialValue() {
return 0;
}
};
public void run(){
for(int i=0 ; i<5 ;i++)
value.set(value.get()+1);
String name = Thread.currentThread().getName();
System.out.println("线程"+name+":"+value.get());
}
public static void main(String[] args){
Test test = new Test();
Thread thread1 = new Thread(test,"1");
thread1.start();
Thread thread2 = new Thread(test,"2");
thread2.start();
}
}
代码中主要要到ThreadLocal的两个方法,initialValue()用来初始化变量,set()用来设置局部变量当前线程副本的值。
看看运行结果:

显然,ThreadLocal不满足可见性,每个线程相当于改变了自己的局部变量,所以其他线程看不到。ThreadLocal相当于是以“空间换时间”,而同步机制是以“时间换空间”的方式。

















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









