







Autograd机制
[官方中文文档]https://pytorch.ac.cn/docs/2.6/notes/autograd.html
[哔站讲解视频]https://www.bilibili.com/video/BV1e34y1m73D?spm_id_from=333.788.videopod.episodes&vd_source=3fa24499c8737a243c0012a2cf75cb9a&p=15
[英文]https://www.bilibili.com/video/BV1by4y1B7LD?spm_id_from=333.788.videopod.sections&vd_source=3fa24499c8737a243c0012a2cf75cb9a
Autoagrad如何工作
Autograd 是一个反向自动微分系统。autograd 会记录一个图,记录所有创建张量的操作,得到一个有向无环图,其叶节点是输入张量,根节点是输出张量。在计算前向传播时,autograd 会在计算的同时请求构建一个图,该图表示计算梯度的函数(每个 torch.Tensor 的 .grad_fn 属性是此图的入口点)。在反向传播时,通过从根节点到叶节点追踪此图,自动使用链式法则计算梯度。
Autograd的回溯机制与动态计算图
1.可微分性相关属性
在PyTorch中张量不仅仅是一个纯计算的载体,张量本身由于其自身属性也可支持微分运算。这种可微分性不仅体现在可以使用grad函数对其进行求导,更重要的是这种可微分性会体现在可微分张量参与的所有运算中。
- requires_grad属性:可微分性(此标志默认为false,除非包装在nn.Parameter中)
# 构建可微分张量
x = torch.tensor(1.,requires_grad=True)
x
x的输出为:tensor(1., requires_grad=True)
# 构建函数关系
y = x ** 2
- grad_fn属性:存储张量微分函数(fn实际上就是function)
y
y的输出为:tensor(1., grad_fn=(PowBackward0))
其中,Pow代表的是幂运算,同理也有AddBackward0等微分函数关系,至于为什么最后要加一个0,可能是约定成俗了。同时由于x本身是可微的,所以由x生成的y自然也是可微的,即自动有requires_grad=True的属性。
y.grad_fn
y.grad_fn的输出为:(PowBackward0 at 0x200a2047208)
但是x最为初始张量,并没有grad_fn属性。
2.因此,在Pytorch的张量计算过程中,每一个新张量都是可微的,同时保存了前一步的函数关系,这就是所谓的回溯机制。根据这个回溯机制,就可以得到张量计算图,一个有向无环图。
张量计算图
1.通过回溯机制,将张量的复杂计算过程抽象为一张图。
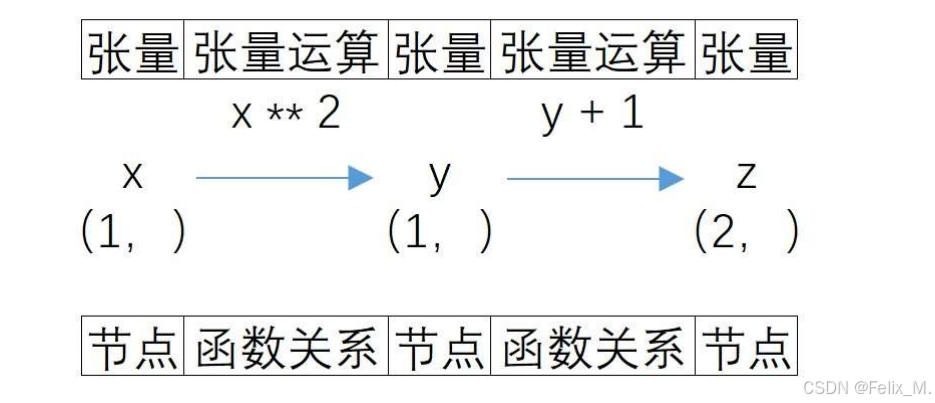
图中,节点表示张量,边表示函数计算关系,方向表示运算方向。其中,初始输入的可微分张量是叶节点,中间的是中间节点,最后得到的张量是输出节点。
2.PyTorch的图是动态计算图,图在每次迭代时都会从头开始重新创建,可以伴随着新张量或运算的加入不断更新。
反向传播与梯度计算
- grad属性(存储可微分张量的梯度值)
x = torch.tensor(1.,requires_grad=True)
y = x ** 2
z = y + 1
z.backward() # 只有执行反向传播后各个张量的grad属性才有梯度值
x.grad
输出的梯度值为:tensor(2.)
阻止计算图追踪(局部禁用梯度计算)
在部分情况下,我们不希望在创建计算图的过程中,所有的函数关系都被追踪记录,或者所有的新张量都具有可微属性。
- with torch.no_grad(): (常用于编写优化器时)
x = torch.tensor(1.,requires_grad = True)
y = x ** 2
with torch.no_grad(): # 其内部过程屏蔽了计算图的自动追踪记录
z = y + 1
其中,x与y 的关系被记录,而y与z的运算关系则不会被记录。
z.requires_grad # 输出为 False,即不具备可微属性
z # 输出为 tensor(1.),但仍然是张量
- .detach方法:创建一个不可导的相同张量,使其参与后续运算,从而阻断计算图的追踪。
x = torch.tensor(1.,requires_grad=True)
y = x ** 2
y1 = y.detach()
z = y1 + 1
y # 输出为 tensor(1., grad_fn=(PowBackward0))
y1 # 输出为 tensor(1.)
z # 输出为 tensor(1.)
- 评估模式:nn.Module.eval()
在官方文档中,认为局部禁用梯度计算有三种模式
1 默认模式(Grad)
2 No-grad模式
3 推理模式
对于module.eval()(或等效的module.train(False))虽然并不是一种标准的禁用梯度计算的机制,但是由于其可以实现所需功能,同时被人们广泛使用,因此也包含在此处。故在训练模型时使用model.train(),在验证或测试模型时使用model.eval()。
ps:variable是对tensor的封装,包含了三部分:
- .data:tensor本身
- .grad:对应tensor的梯度
- .grad_fn:该variable是通过什么方式获得的
pytorch0.4版本后将tensor和variable合并在了一起。

















 9859
9859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









