



一种基于强化学习的新型协作式交通信号系统通过 最大压力控制
摘要
提高交通信号控制效率是缓解信号交叉口交通拥堵的 有效途径。为了实现对路网交通流的有效管理,当前的研究趋 势集中在应用强化学习(RL)技术进行交通路网中的协作式交 通信号控制。然而,现有的基于协作的方法通常忽略了交通流 信息交换过程中传输延迟对系统的影响。大多数研究假设信号 控制器能够无延迟地采集所有实时车辆特征。为填补这一空白, 我们提出了一种考虑交通路网中数据传输延迟问题的基于强化 学习的协同交通信号控制方案。本文中,我们(1)基于先进的 最大压力控制理论,设计了新的强化学习智能体,通过改进奖 励机制和状态表示来协同控制交通信号;(2)提出一种交通状 态预测方法,以减小实时与延迟的交通状况之间的差异,从而 应对数据传输延迟问题;(3)在具有不同范围数据传输延迟的 合成与真实场景中评估了所提出方案的性能。结果表明,我们 的方法优于以往基于最大压力控制的交通信号控制方法,并有 效解决了数据传输延迟问题。
索引词
协作式交通信号控制,强化学习,最大压力控制
I. 引言
交通信号控制(TSC)是交通管理研究中的一个挑战 [1]。由于单个交叉口的交通流不仅取决于自身的交通状 况,还受相邻交叉口交通状况的影响[2], ,因此需要道 路网络中相连交叉口之间的协同信号控制。多个交叉口的 协同交通信号控制有助于更好地调节相连交叉口的交通流, 提高交通管理的效率,甚至预防交通拥堵问题。实现协同 交通信号控制需要获取道路上的车辆及相邻交叉口的超低 延迟交通信息。
强化学习(RL)算法作人工智能的一个分支,已引 起研究关注,并在解决协同交通信号控制问题方面得到越 来越多的应用[3]–[5]。强化学习的自学习特性使其成为构 建交通信号控制问题的强大方法。首先,它
不依赖于监督学习标签,而监督学习标签需要大规模可靠 数据集来训练控制器。此外,在线自适应学习特性已嵌入 模型学习过程[6]中。强化学习的这一内在特性使得信号 控制器能够在动态交通环境中根据新的交通观测数据逐步 更新其模型。
许多现有的基于强化学习的协同交通信号控制方法试 图在理想交通环境中利用实时联合交通信息[3]或联合Q 函数[4]来提高信号控制效率。然而,这些方法存在若干 局限性。首先,联合交通信息和Q函数引入了高维交通状 态和Q值,增加了在大规模交通路网上百学习方法的学 习复杂度。其次,这些方法都依赖于一种理想化假设,即 理想交通环境不考虑车对车(V2V)和车对基础设施( V2I)通信中的数据传输延迟。然而,在真实交通环境中 的车载网络无法在没有数据传输延迟的情况下提供实时交 通信息[7],[8]。这种传输延迟会影响通过车载网络进行的 实时交通信息采集和协同交通信号控制。
为解决上述问题,本文提出了一种基于强化学习的协 同TSC方案,具有以下贡献: 1) 设计了一种基于排队长度的max‐pressure指标[9]– [11]的新型交通状态表示方法,该方法考虑了本地及相邻 交叉口的交通状态。所提出的表示方法使信号控制器能够 获知未来阶段从相邻交叉口即将到达的交通流。
2) 我们通过考虑连接车道的容量以及来自相邻交叉口 的即将到达的车辆,改进了[12]中使用的奖励模型。改 进后的奖励模型避免了车辆进入已满载车道而导致交通拥 堵的情况,并通过考虑即将到来的车辆需求而非局部交通 状况,降低了切换交通信号的频率。
3) 提出了一种新方法,以解决驶来车辆到交叉口的数 据传输延迟问题,从而增强对实时交通状况的状态测量。
由于车载网络中的数据传输延迟,我们在不同的数据传输 延迟范围内进行了全面的实验,以验证该方法在交通环境 中的有效性。
本文其余部分组织如下。第二节介绍了孤立和多个交叉 口交通信号控制的相关工作。第三节定义了本研究的问题。
二、相关工作
在本节中,我们首先讨论基于强化学习的交通信号控 制(TSC)的前期工作。根据控制范围的不同,现有的基 于强化学习的TSC方法大致可分为两类:孤立交叉口的交 通信号控制和多个交叉口的协同交通信号控制。
A. 孤立交叉口的交通信号控制
单点交叉口的交通信号控制旨在根据局部交通状况提 高单个交叉口的交通控制效率,不考虑相邻交叉口甚至整 个交通路网中所有交叉口的交通状况。在采用强化学习技 术构建交通信号控制问题时,交叉口的局部交通状态通过 若干特征进行描述,例如连接车道的排队长度[13],[14], 、 车道上的车辆位置[15],等。基于表格的强化学习方法被 应用于早期的交通信号控制研究中,这些方法使用向量或 表格描述交通特征,并将状态‐动作对的Q值存储在Q表 [16],[17]中。然而,当交通环境规模增大时,这些方法在 存储高维交通状态方面存在局限性。
近年来,深度强化学习(DRL)被用于解决高维交通 状态问题。DRL是一种基于近似的强化学习技术,能够将 交通状态泛化到高维空间,并学习基于神经网络的模型以 求得收敛的Q值[18]。基于图像的交通状态表示被提出用 于描述交通特征,特别是连接车道上的车辆位置[19],[20]。
然而,互联交叉口之间的交通状况相互影响对交通路网中 的交通信号控制具有显著影响。孤立的交通信号控制无法 保证在交通路网内实现最优的全局控制。
B. 多交叉口协同交通信号控制
协同交通信号控制方法使所有控制器代理能够协同控
制交通信号,以实现全局优化。E. Van Der Pol et al.
[21] 和 S. Yang etal. [22] 应用最大‐加算法来寻找交叉 口之间的最优联合动作。最大‐加算法允许智能体在协调 图中基于相连代理的收益值选择最优操作。一个智能体的 收益值会反复发送给其邻居,直到经过有限次迭代后收益 值收敛于某一点。一些研究通过并行学习局部交通环境以 及相邻甚至全局交叉口的环境来实现协同交通信号控制, 以寻找最优动作 [3],[24]。它们通过将局部交通状态与邻 居状态拼接来表示交通状态。另一种协同交通信号控制方 法是学习局部和相邻交叉口的联合Q函数[4],[25],[26]。
该方法使得智能体能够共享
相邻交叉口之间的Q值,并协同学习全局最优Q函数。基 于联合Q函数理论,T. Tanet al.提出了一种用于大规模 交通路网的去中心化到集中式架构[27]。该架构首先为每 个子区域分别学习交通信号控制模型,然后将所有Q函数 聚合为一个全局Q函数,以实现全系统联合动作的优化。
多相位(MP)控制是一种最先进的交通信号控制方法, 它考虑了进口道和出口道上车辆的排队长度[9]或行程时 间[11]。Weiet al.将MP控制方法应用于强化学习方法 的奖励模型设计,以在干线道路网络中实现协同交通信号 控制[12]。他们证明,基于MP的奖励和交通状态设计能 够达到与联合交通状态设计相似的性能。然而,他们忽略 了当信号控制器持续向高占用率的出口道放行车辆时,车 道容量对交通流和拥堵问题的影响。此外,在调整绿灯信 号以应对即将到来的压力时,他们忽略了来自相邻交叉口 的压力,这可能导致切换交通信号相位的频率增加。更高 的切换次数会延长交通路网中黄灯相位的持续时间,降低 交叉口交通流调节的效率。此外,以往的研究人员往往忽 略了车对车(V2V)和车对基础设施(V2I)通信中的数 据传输延迟。然而,在真实交通环境中,此类通信通常会 产生不可忽略的传输延迟。这种延迟直接影响交通环境的 测量和交通信号控制。
本文旨在基于最大压力算法,在更真实的交通环境中 提高多个交叉口协同交通信号控制的效率。我们设计了一 种交通状态表示和奖励模型,通过考虑相邻交叉口的压力 来提升协同交通信号控制性能。此外,我们提出了一种方 案以应对交通环境中车对车(V2V)和车对基础设施( V2I)通信的数据传输延迟,并进行了综合实验,验证了 所提出的方法在不同范围的延迟下的有效性。
III. 问题陈述
如前所述,在城市道路网络中,一个交叉口的交通状 况不仅取决于该交叉口的信号控制,还受到其相邻交叉口 的信号控制和交通流的影响。因此,为了实现全系统/全 局最优信号控制,必须采用一种考虑这些相互关联交叉口 交通状况的协同交通信号控制方法。本研究聚焦于包含多 个信号交叉口的交通路网中的协同交通信号控制问题。
在本研究中,我们假设相邻的信号控制交叉口能够利 用车载网络共享其本地交通信息(相互之间),如图1所 示。在每个交叉口,均设有交通信号控制器
IV. 提出的基于最大压力的协同交通信号控制方法
本节介绍了我们新设计的基于强化学习的最大压力控 制协同交通信号控制(MP‐CTSC)方法,旨在提高车载 网络中多个交叉口的交通控制效率。我们首先提出 MP‐CTSC的框架,然后进行描述
A. 框架
基于[6],中介绍的RL架构,所提出的MP‐CTSC框架 主要由交通环境和智能体组成。该交通环境是一个包含多 个相连交叉口的交通道路网络。根据第三节中描述的环境, 这些交叉口可以通过车载网络共享其交通信息,并接收来 自道路上车辆的控制消息。智能体学习收集到的交通信息, 并训练一个函数逼近模型,以针对给定的交通状态找到最 优信号控制动作。由于车载网络中存在数据传输延迟问题, 智能体配备了交通状态测量模块,用于基于延迟的交通信 息来预测实时交通状况。
图4展示了在时间步长 t时交通环境与智能体之间的 交互。智能体监听来自交通环境的持续传入的控制消息
MV,并将这些消息转换为交通状态。由于控制消息 MV
转发存在延迟,交通状态测量模块会预测在时间步长 t
的交通状态 st,以减小实时交通状况与延迟的交通状况之 间的差异。根据预测的交通状态,函数逼近模块生成用于 控制信号灯的最优操作(at)。在时间步长 t+1,执行 的操作(at)所对应的奖励(rt)以及下一个交通状态 (st+1)将返回给智能体,并与 st和 at一起存储到记忆 中。智能体的经验被存储在记忆中,通过经验回放过程来 改进函数逼近模型。
以下各节描述了智能体设计、函数逼近模块和交通状态测 量模块。
B. 智能体设计
1) 交通状态表示:
在本文中,我们使用四个交通特征来描 述任意交叉口的交通状态。这四个特征是本地当前交通信号
相位、车辆数量、平均速度和平均加速度。当前交通信号 相位是当前相位的索引。车辆数量、平均速度和平均加速 度分别由三个矩阵 M1、 M2、 M3表示。每个矩阵的维度 为 |L| × 4,其中 L表示交叉口的连接车道, |L| 是车道 的数量。在这些矩阵中,行向量表示在对应车道上行驶车 辆的特征状态。如图5所示,每条车道被均匀划分为三个段, 以降低状态表示的维度。行中的单元格1、2和3描述连接车 道上对应路段的特征,单元格4表示来自相邻交叉口的驶来 车辆的状态。例如,在图5中, M1、 M2和 M3中的单元 格1、2和3分别表示车道在路段1、2和3中的车辆数量、平 均车辆速度以及平均加速度。 M1、 M2和 M3中的单元 格4描述来自右侧相邻交叉口的驶来车辆的三个特征。
2) 操作:
动作空间定义了智能体可以采取的、用于影响 环境[6]的操作。我们的动作空间被定义为A={a1, a2}, 分别表示两种允许左转的信号配时方案。如果信号相位设计 方案采用的是保护左转的信号配时方案,则动作空间A也可 定义为{a1, a2, a3, a4} 。我们设定信号配时方案的最小持续 时间∆t,以避免由于交通状态动态变化导致的闪烁的信号配 时方案。当前信号配时方案的已用时间未超过 ∆t之前,不 得切换至其他信号配时方案。在两个不同的信号配时方案之 间切换时,会插入一个五秒黄灯信号阶段。当新选择的信号 配时方案与当前信号配时方案不同时,智能体将在更新当前 相位为目标信号配时方案前,先进入五秒黄灯信号阶段。
3) 奖励:
奖励用于框定应用的目标,并评估已执行的 操作,以提升智能体在未来步骤中的性能[6]。在此,我 们设计了一种基于多相位的奖励模型,该模型根据交叉口 进出口排队长度测量来衡量车辆移动的压力。
我们作为假设一个交通环境包含一个 互‐
C. 函数逼近
本文中,我们采用Q网络作为函数逼近器,用于估计 给定交通状态下操作的Q值。如图7所示,给定交通状态 的四个特征(一个标量,三个矩阵)被展平并拼接成一个 数组,然后输入神经网络。该神经网络由多个全连接层和 一个输出层组成。在实际应用中,可根据不同交叉口的实 际状况调整网络的隐藏层数量。输出层神经元的输出值表 示对应操作的Q值。智能体选择Q值较高的操作来控制交 通信号。操作选择采用 ε‐greedy算法。智能体会以较小 概率随机选择某一操作
表I:控制消息内容的字段定义。
| 领域 | 描述 |
| — | — |
| tsent | 车辆发送的消息的时间戳 |
| id | 车辆的全局唯一ID |
| psent | 时间戳 tsent 时的车辆位置 |
| ssent | 时间戳 tsent 处的车辆速度 |
| asent | 时间戳 tsent 处的车辆加速度 |
概率, ε,通常选择具有最高Q值的操作,因为Q值量化 了智能体在未来步骤中的奖励。
为了训练交通信号控制模型,我们采用经验回放技术 [18],[31]来更新模型的参数 θ。在记忆中维护一个经 验缓存,用于存储遇到的交通状态、执行的动作以及来自 交通环境的奖励。该缓存采用具有最大容量的序列队列结 构,并自动移除最近最少插入的经验。为了稳定学习过程, 我们的交通信号模型中应用了目标Q网络[18]。尽管目标 Q网络的结构与学习Q网络相似,但其参数 θ−基于 θ以 较低频率进行更新。
D. 交通状态测量
在无线通信中,数据传输延迟不可避免,尤其是在动 态交通环境中,车载网络更是如此。车辆发送至交叉口的 消息延迟可能由多种因素引起,例如车辆速度、车辆到交 叉口或前车的距离等。因此,控制器智能体在每个时间步 长收集的交通状态无法准确反映实时交通状况。为此,我 们设计了一种交通状态测量方法,以应对车载网络中的延 迟问题。
1) 控制消息的内容:
在我们的交通状态测量中,控 制消息的内容必须包含后续状态预测所需的必要信息。因 此,在本研究中,我们设计了一种新的控制消息,该消息 由五个字段组成,用于表示从车辆传输到交叉口智能体的 瞬时车辆数据(见表I)。第一个字段是车辆创建并发送 该消息的时间戳 tsent。智能体使用时间戳字段来估计消息 传输的延迟。第二个字段是前方车辆的全局唯一ID。第三 个字段是车辆在时间戳 tsent时的位置(psent)。我们假设 车辆可通过GPS设备获取位置数据。为简化方法描述,我 们将车辆位置定义为车辆与前方交叉口之间的距离。第四 个和第五个字段是车辆的速度轮廓信息,包括在时间戳 tsent时的车辆速度(ssent)和加速度(asent)。
2) 状态预测:
为了减少数据传输延迟对交通信号控制 系统控制效率的不利影响,我们提出了一种方法,基于从 相邻交叉口接收到的即将到达车辆的消息来预测实时交通 状态。
E. 复杂度分析
本节分析了提出的MP‐CTSC方法的空间复杂度和时间复杂度。
1) 空间复杂度:
MP‐CTSC 的空间复杂度主要由两部分组成:交通状态和控制消息。根据第四节IV‐B1中的交通状态定义,单个交叉口状态的维度为 D= 4× |L|×3+1,其中 4×|L| 表示矩阵的维度,最后一个维度1表示交通信号相位索引。假设在一个交通路网中有 N 个交叉口,则交通状态的空间复杂度为 O(D×N) ≈ O(|L|×N)。在我们的控制消息定义中,一条消息包含五个特征。因此,一条消息的空间复杂度是常数时间。我们假设车辆数量为 |V |,则在一个时间步长内控制消息的总空间为 |V | × 5,意味着控制消息的空间复杂度为 O(|V |)。因此,MP‐CTSC的空间复杂度为 O(|L| × N+ |V |)。
2) 时间复杂度:
MP‐CTSC的时间复杂度包含两个主要部分:用于预测Q值的Q网络和交通状态测量。Q网络的时间复杂度取决于其输入、隐藏层和输出的维度。由于这些维度在交通信号控制过程中不会持续变化,我们假设在一个交叉口处Q网络的时间复杂度为一个常数。此外,我们假设交通路网中的所有智能体可以同时预测Q值;因此,Q网络的时间复杂度可表示为 O(1)。交通状态测量的时间复杂度取决于交通路网中车辆的数量。如果我们假设所有智能体可以同时测量交通状态,则交通状态测量的时间复杂度为O(|V |/N)。因此,MP‐CTSC的时间复杂度大致等于 O(|V |/N+1) ≈ O(|V |/N) ≈ O(|V |)。
V. 性能评估
我们进行了实验,以评估基于最大压力的协同交通信号控制(MP‐CTSC)在城市交通模拟(SUMO)[33]中的性能。SUMO 是一个免费开源的微观交通仿真系统,集成了多个用于路径规划和需求生成的库。我们使用 JTRROUTER 工具根据车辆到达率生成交通流,并利用 TraCI 库控制交通信号并收集瞬时车辆信息。
我们用于评估方法性能的指标分为两类:基于交叉口的和基于车辆的。基于交叉口的指标包括交叉口的排队时间和排队长度。基于车辆的指标包括车辆等待时间、平均车辆速度、停车次数以及车辆燃油消耗。车辆燃油消耗通过《道路运输排放因子手册》(HBEFA)[34],进行估算,该方法在SUMO中被扩展,用于根据车辆速度和加速度估算瞬时车辆燃油消耗。HBEFA提供了多种因子以估算燃油消耗和排放值。根据不同的影响因素,如车辆质量和行驶阻力,这些因子被划分为从欧0到欧6的七种排放标准。本文采用SUMO中的默认设置欧4作为汽油乘用车的排放标准,用于估算车辆燃油消耗。
A. 交通环境
为了更准确地评估我们的MP‐CTSC方法的性能,我们通过考虑两种不同的交通场景来测试我们的工作。
1) 交通场景1:
我们使用SUMO模拟了一个包含一个与四个相邻交叉口相连的交叉口的交通环境(见图8)。每条道路采用具有两条车道的双向连接来连接两个相邻交叉口。最右侧车道允许直行和右转车辆移动,最左侧车道允许直行和左转车辆移动。表II总结了车辆和车道的基本参数。0号交叉口的交通信号由MP‐CTSC控制,其余交叉口由预设定时交通信号相位控制。定时TSPs遵循图3中的许可性左转设计。我们为每个绿灯相位设置30秒,黄灯相位设置5秒。
图9显示了车辆在一小时内进入交通环境的到达率。采用不平衡且动态的车辆需求来模拟实际交通状况。我们模拟了交叉口1号和3号的车辆需求低于交叉口2号和4号的需求,并且交叉口2号和4号的需求增长速度也快于其他交叉口。在前半小时内,我们温和地增加车辆需求,然后在后半小时大幅提升交叉口2号和4号的需求,以评估各方法在增长的车辆需求下的性能。车辆路线由SUMO提供的 JTRROUTER工具生成,转向比例设置为右转移动35%,直行移动40%,左转移动25%。
在此场景中,为了展示所提出的方案在解决数据传输延迟问题上的有效性,我们将车辆 Vi到交叉口的平均消息传输延迟估计为 ∆Di= k × δ,其中 k表示消息成功传输到交叉口的预期跳数, δ表示单跳平均延迟[35]。由于我们的研究集中在城市交通道路网络环境,因此在稀疏交通状况下忽略了数据传输延迟。在测试环境中,我们将 V2V和V2I通信的传输范围设为50米,并将延迟因子 δ={0s, 0.5s, 1s, 2s}用于评估不同延迟范围下的性能。
2) 交通场景2:
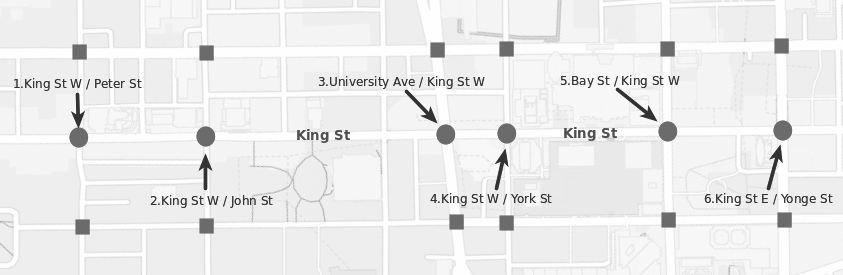
我们使用SUMO基于真实世界交通数据集模拟了另一个交通环境,该环境包含车辆到交叉口的消息传输延迟。交通路网包含六个交叉口,由一条名为国王街的主干道和多伦多的其他六条次要街道构成(见图10)。从西到东的交叉口名称依次为:1) 国王街西/彼得街 (I‐KP);2) 国王街西/约翰街 (I‐KJ);3) 大学大道/国王街西 (I‐UK);4) 国王街西/约克街 (I‐KWY);5) 湾街/国王街西 (I‐BK);6) 国王街东/央街 (I‐KEY)。
六个交叉口的车辆到达率是通过多伦多基于视频的计数系统收集的车辆需求生成的,该系统统计了四个进口道(北、南、东、西)上的铰接式卡车、自行车、信号灯、行人和单车辆卡车的数量。2018年2月12日轻型车辆的车辆需求被提取,用于生成六个交叉口的车辆到达率。
以下方程组:
$$
\begin{aligned}
VN(NB) &= VE(WB) \times Rr(E) + VS(NB) \times Rt(S) + VW(EB) \times Rl(W) \
VS(SB) &= VN(SB) \times Rt(N) + VE(WB) \times Rl(E) + VW(EB) \times Rr(W) \
VE(EB) &= VN(SB) \times Rl(N) + VS(NB) \times Rr(S) + VW(EB) \times Rt(W) \
VW(WB) &= VN(SB) \times Rr(N) + VS(NB) \times Rl(S) + VE(WB) \times Rt(E)
\end{aligned}
$$
约束条件为 $ Rr(N) + Rl(N) + Rt(N) = 1 $, $ Rr(S) + Rl(S) + Rt(S) = 1 $, $ Rr(W) + Rl(W) + Rt(W) = 1 $, $ Rr(E) + Rl(E) + Rt(E) = 1 $,其中 $ Rr(N), Rl(N), Rt(N), Rr(S), Rl(S), Rt(S), Rr(W), Rl(W), Rt(W), Rr(E), Rl(E), Rt(E) $ 表示进口道转向比例,$ VN(SB), VS(NB), VE(WB), VW(EB) $ 表示各进口道车辆到达需求, $ VN(NB), VS(SB), VE(EB), VW(WB) $ 表示四个进口道的现有车辆数量。
B. 参数设置
根据图7所示的Q网络架构,我们通过将隐藏层数量从4层调整到2层,并调整隐藏单元的数量为 [16, 32, 64, 128]的值,手动调节了Q网络的超参数。我们发现这些超参数在我们的交通场景中对实验结果影响较小。为了简化Q网络模型并降低学习成本,我们构建了一个双隐藏层的Q网络作为函数逼近器。输入交通状态首先被送入展平并连接的层,然后进入两个全连接层。第一全连接层包含128个Leaky ReLU单元,第二全连接层包含32个 Leaky ReLU单元。输出层是一个具有两个动作对应的两个输出的全连接层,每个输出代表相应的交通信号相位。
表III列出了参考[20],[37]中参数的Q网络训练过程的参数。 ε在每个交通信号控制周期按0.996的系数从0.5衰减至0.1。我们基于每个控制周期的采样经验训练Q网络,并每300个控制周期更新一次目标Q网络的参数。我们设置了最小交通信号相位间隔 ∆t= 5秒,以避免出现闪烁的TSPs。交通信号控制周期设置为5秒,与TSP间隔 ∆t相同,这意味着智能体根据前5秒内的延迟车辆数据预测实时交通状态。
表III:Q网络学习过程的参数。
| 参数 | 值 |
| — | — |
| 经验记忆池 D大小 | 1000[37] |
| 起始 ε | 0.5 |
| 结束 ε | 0.1 |
| 折扣因子 γ | 0.8[37] |
| 学习率 α | 0.001[20] |
| 最小交通信号相位间隔 ∆t | 5秒[37] |
| Leaky ReLU β | 0.01[20] |
C. 对比方法
我们与以下方法进行了性能比较。
1) 固定周期交通信号控制:定时交通信号控制是一种通过人工设计的交通信号相位来控制交通信号的自然方式。在此,我们为每个绿灯TSP设置30秒,黄灯警示相位设置5秒。
2) 最大压力交通信号控制:最大压力TSC [9]是一种感应式控制方法,根据车辆行驶的实时压力贪婪地选择一个TSP。车辆行驶压力通过进出队列长度来衡量,且不考虑车道容量。
3) 基于旅行时间的最大压力交通信号控制:TTMax‐pressure TSC [11]是一种感应式控制方法,根据进口道和出口道的旅行时间贪婪地选择一个TSP。
4) Presslight交通信号控制:Presslight [12]是一种基于强化学习的交通信号控制方法,该方法在学习过程中使用缩放的最大压力算法[38]来设计其奖励模型。车辆移动的压力通过进口道和出口道占有率之差来衡量。
D. 基于合成数据的仿真结果
1) 基于交叉口的指标性能:
图11展示了在合成交通场景下,使用0号交叉口的平均排队时间(AQT)(单位:秒)和平均排队长度(AQL)(单位:米)等基于交叉口的测量指标所得到的性能。根据图9所示的车辆到达率,我们比较了在低变化到达率和提高到达率情况下的性能表现。
图11a和图11b分别为AQT和AQL指标的结果,未考虑数据传输延迟,即智能体可以立即接收到瞬时车辆数据。可以看出,在低到达率时段,所有对比方法在AQT和AQL指标上的性能相似。与定时交通信号控制相比,感应式控制和基于强化学习的交通信号控制方法仅表现出略微更好的结果。
当到达率增加时,各方法的性能表现出显著差异。随着后半小时车辆需求的增加,MP在AQT指标上的表现最差。这是因为MP的目标是最大化交叉口的通行能力,它将绿灯信号分配给压力较高的车道,导致在不同车道排队车辆数量变化的情况下,信号配时方案切换频率较高。
TT‐MP由于采用了基于旅行时间的压力测量,在AQT指标上表现优于MP。Presslight通过使用强化学习技术实现对长期交通状况的自适应交通信号控制,从而提升了 MP在AQT指标上的性能,并且相比感应式交通信号控制方法降低了切换信号配时方案的频率。与其它方法相比, MP‐CTSC在AQT和平均队列长度指标上均表现出最佳性能。在采用与Presslight方法相同的强化学习技术基础上, MP‐CTSC考虑了相邻交叉口的交通压力
表IV:交通场景1中0号交叉口基于车辆的测量在等待时间(WT)、平均停车次数(平均停车)、平均速度(平均速度)和 燃油消耗(FC)方面的性能。
| 指标 | 预设定时 | MP | TT‐MP | Presslight | MP‐CTSC |
| — | — | — | — | — | — |
| 延迟 δ | - | δ= 0 δ= 1 | δ= 0 δ= 1 | δ= 0 δ= 1 | δ= 0 δ= 0.5 δ= 1 δ= 2 |
| 等待时间(秒)
Av g.Speed(m/s)
Av g.Stops
Fu el Consu mption(ml/km) | 27.7
5.6
1.44
45.5 | 14.6 15.4
6.2 5.6
1.01 1.20
29.1 29.9 | 15.7 16.9
5.8 5.7
1.08 1.05
30.2 31.6 | 13.1 13.7
6.2 6.3
0.96 0.99
26.9 27.6 | 12.1 11.9 11.6 12.9
6.5 6.6 6.5 6.4
0.94 0.84 0.89 0.92
26.6 25.8 25.7 27.0 |
交叉口。这种考虑方式会将更长的绿灯时间分配给具有较高压力的车道,包括本地压力以及来自相邻交叉口的流入压力,从而允许智能体对本地压力较低但流入压力较高的车道保持绿灯信号。而在Presslight中,由于未考虑相邻交叉口的压力,智能体会将绿灯信号切换到本地压力较高的车道,这可能与当前信号配时方案不同,随后需等待来自相邻交叉口的流入压力转化为本地压力后再切换回原状态。更多的信号配时方案切换次数会导致更长的黄灯持续时间,从而降低交通信号控制效率。
图11c 和 图11d 分别是考虑数据传输延迟情况下的 AQT 和 平均队列长度 指标结果。我们设置 δ= 1以确保智能体只能接收到瞬时车辆一跳范围内的数据,意味着智能体无法接收延迟超过一秒的车辆数据。如图11a和图11b所示,定时交通信号控制在两种情况下表现出相同的性能,因为它未检测交通状况。在存在数据传输延迟的交通环境中,MP、TT‐MP和 Presslight相较于 δ= 0性能更差。这是由于数据传输延迟导致智能体无法检测到距离交叉口较远的车辆,从而使 得包含未被检测车辆的车道压力较低。这种延迟的压力测量误导了智能体对交通信号的控制,导致性能劣于无数据传输延迟的情况。可以看出,MP‐CTSC由于采用了带预测的交通状态测量,在两种交通条件下保持了相同的性能。
2) 基于车辆的测量性能:
表IV总结了对比方法在交通场景1中基于车辆的测量指标上的性能,包括等待时间(WT)(秒)、停车次数、平均速度(米/秒)和燃油消耗(毫升/公里)。可以看出,定时控制方法导致了最高的燃油消耗,因为频繁的启停行驶会增加燃油消耗[39]。MP、TT‐MP和Presslight在存在数据传输延迟的交通环境中表现略差于无延迟环境。这些结果是由于延迟的车辆数据导致交通状态测量信息丢失所致。MP‐CTSC在两种交通状况下的各项指标上均优于其他对比方法 δ= 0和 δ ≠ 0。我们评估了MP‐CTSC在不同延迟范围内的表现,以验证我们状态预测方法的有效性。MP‐CTSC在所有延迟条件下均表现出稳定的性能,意味着采用交通状态预测的MP‐CTSC能够有效解决延迟交通状态问题。
E. 基于真实世界数据的仿真结果
我们进一步在具有延迟因子 δ= 1的真实世界交通场景中比较了各方法。图12展示了交通场景2中基于交叉口的测量性能,未包含定时控制方法的性能,因其表现劣于其他方法。图中显示了六个交叉口每15分钟的平均AQL和 AQT。可以看出,各方法性能接近,但MP‐CTSC在动态交通流中表现更为稳定。由于存在延迟的车辆数据, MP、TT‐MP和Presslight的性能波动大于MP‐CTSC。
表V: 性能基于车辆的测量在交通场景2。
| 指标 | 预设定时 MP TT‐MP Presslight MP‐CTSC |
| — | — |
| 延迟 δ | -δ= 1 δ= 1 δ= 1 δ= 0 δ= 0.5 δ= 1 δ= 2 |
| 等待时间(秒)
Av g.Speed(m/s)
Av g.Stops
Fu el Consu mption(ml/km) | 14.5 10.2 12.5 9.2 7.4 7.5 7.4 7.9
6.6 6.9 6.8 7.6 7.9 7.6 7.8 7.1
0.69 0.67 0.67 0.52 0.47 0.51 0.46 0.51
34.8 29.2 31.6 28.4 26.6 26.9 26.5 28.0 |
表VI:交通场景2中六个交叉口的平均绿灯持续时间( GSD)和黄灯持续时间(YSD)。
| 方法 | GSD(秒) YSD(秒) YSD百分比 |
| — | — |
| MP
TT-MP
Presslight
MP-CTSC | 36195 14509 0.29
36324 14377 0.28
37504.6 13321.4 0.26
39110 11598 0.23 |
智能体重用延迟的车辆数据来预测当前时间戳下的交通状态,缩小了存在和不存在数据传输延迟情况下的交通状态之间的车距Gap。在真实世界交通场景中,采用MP‐CTSC的车辆具有最低等待时间、最少停车次数、最低燃油消耗以及最高速度,表明其交通信号控制性能相比其他方法最为高效。产生该结果的原因在于采用了带预测的交通状态测量。当延迟因子为 δ= 1时,智能体只能接收到前一秒内的车辆数据,而延迟超过一秒的数据则会丢失。这种缺失的车辆数据导致智能体在每个时间步长所感知的交通状况出现延迟,从而可能在高负荷车道上错误地分配红灯信号,做出不良决策。
MP‐CTSC通过带预测的交通状态测量解决了数据传输延迟问题。它收集了每秒交通车辆数据,并基于前5秒交通状态预测当前交通状态。状态预测减少了实时交通状态与延迟交通状态之间的车距Gap。
另一方面,在考虑相邻交叉口压力的情况下,我们的方法降低了切换信号配时方案的频率和黄灯相位的持续时间,表明MP‐CTSC提高了交通控制的效率。表VI显示,与其他方法相比,MP‐CTSC的黄灯持续时间最短,这意味着MP‐CTSC在测试期间的切换次数更少。由于黄灯相位仅在智能体尝试将当前交通信号相位切换到另一相位时发生,因此更高频的交通信号相位切换会增加黄灯时间持续时间,并降低交叉口交通信号控制的效率,因为在黄灯相位期间所有车辆必须停止。
我们还评估了MP‐CTSC在不同延迟因子 δ={0, 0.5, 1, 2}范围下的性能,以展示所提交通状态预测方法在真实世界交通场景中的有效性。从表V可以看出,在真实世界交通场景中,数据传输延迟的增加并未严重恶化MP‐CTSC的性能表现。延迟因子为 δ ≤ 1的交通状况下的性能与延迟因子δ= 0的情况最为接近,而我们发现 δ= 2的性能相较于较低延迟因子的性能更差。这表明,在我们的交通场景中,该交通状态预测方法能够充分应对每跳不超过一秒的数据传输延迟。更长的延迟可能会降低预测准确性,并降低交通信号控制效率。
VI. 结论
本文中,我们提出了一种基于强化学习的协同交通信号控制方案,以提高多个交叉口协同交通信号控制的效率。我们的方法考虑了本地交叉口和相邻交叉口的交通状况。我们提出了一种基于最大压力控制的交通状态表示方法和奖励模型,以构建能够评估本地压力以及来自相邻交叉口压力的智能体,从而避免不必要的切换交通信号相位的控制。此外,我们提出了一种交通状态预测方法,以解决车载网络环境中的数据传输延迟问题。我们通过设置不同范围的延迟来评估所提出的交通状态预测方法。结果表明,在增长的车辆需求下,与先前的最大压力控制方法相比,我们的方法在基于车辆和基于交叉口的指标上均实现了良好性能。同时,我们的状态预测方法能显著缩小实时交通状态与延迟交通状态之间的车距Gap。本方法展示了其解决车载网络中数据传输延迟问题的能力。
在未来工作中,我们将采用最先进的技术来优化和微调函数逼近模型的超参数,以提高所提出方法的性能。此外,我们还将进一步评估所提出的方法在具有过饱和车辆需求和更真实交通环境的大规模交通道路网络中的表现。

















 28
28

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









