







 本文详细介绍了在Linux环境下安装Zookeeper-3.4.10的步骤,包括解压、配置、创建zkData和myid文件,以及集群设置。此外,还讲解了Zookeeper的基础命令,如启动、查看状态、创建和删除节点等。文章最后探讨了Zookeeper的选举原理,强调了过半机制和选择奇数节点的重要性,以确保集群的稳定性和避免脑裂问题。
本文详细介绍了在Linux环境下安装Zookeeper-3.4.10的步骤,包括解压、配置、创建zkData和myid文件,以及集群设置。此外,还讲解了Zookeeper的基础命令,如启动、查看状态、创建和删除节点等。文章最后探讨了Zookeeper的选举原理,强调了过半机制和选择奇数节点的重要性,以确保集群的稳定性和避免脑裂问题。
linux下 zookeeper-3.4.10安装,命令行基础命令,过半机制,奇数原则
zookeeper安装
1.将ZK文件上传到服务器上
2.执行tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/ 将文件解压到opt下的module目录下(根据自己上传的版本更改命令)

3.移动到model目录下,进入ZK文件夹中
cd /opt/module/zookeeper-3.4.10/

4.创建zkData文件夹,然后进入conf文件夹
mkdir zkData
cd conf/

5.将zoo_sample.cfg文件重命名为zoo.cfg

6.打开zoo.cfg文件,将dataDir的值改为刚刚创建的zkData的路径


然后在最后增加代码(主机名改为自己linux系统对应的主机名,需要注意与hosts文件中的主机名一致)
#######################cluster##########################
server.1=bigdata2:2888:3888
server.2=bigdata1:2888:3888
server.3=bigdata3:2888:3888
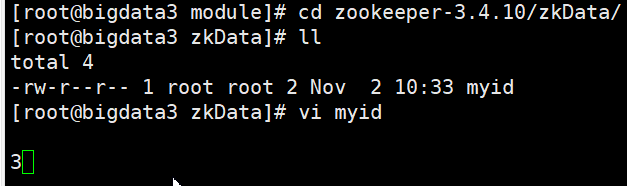
7.进入到zkData文件夹中,创建并打开myid文件



在里面输入数值,数值与之前在zoo.cfg文件中设定的一致
server.1=bigdata2:2888:3888
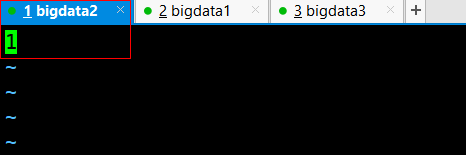
8.回退到model目录中
 9.将zookeeper复制到其他linux系统上
9.将zookeeper复制到其他linux系统上

scp -r zookeeper-3.4.10/ bigdata1:`pwd`
pwd代表相对路径,但是我使用之后并没有往bigdata1中拷贝
于是使用下面的绝对路径
scp -r zookeeper-3.4.10/ bigdata1:'/opt/module/'

结果:
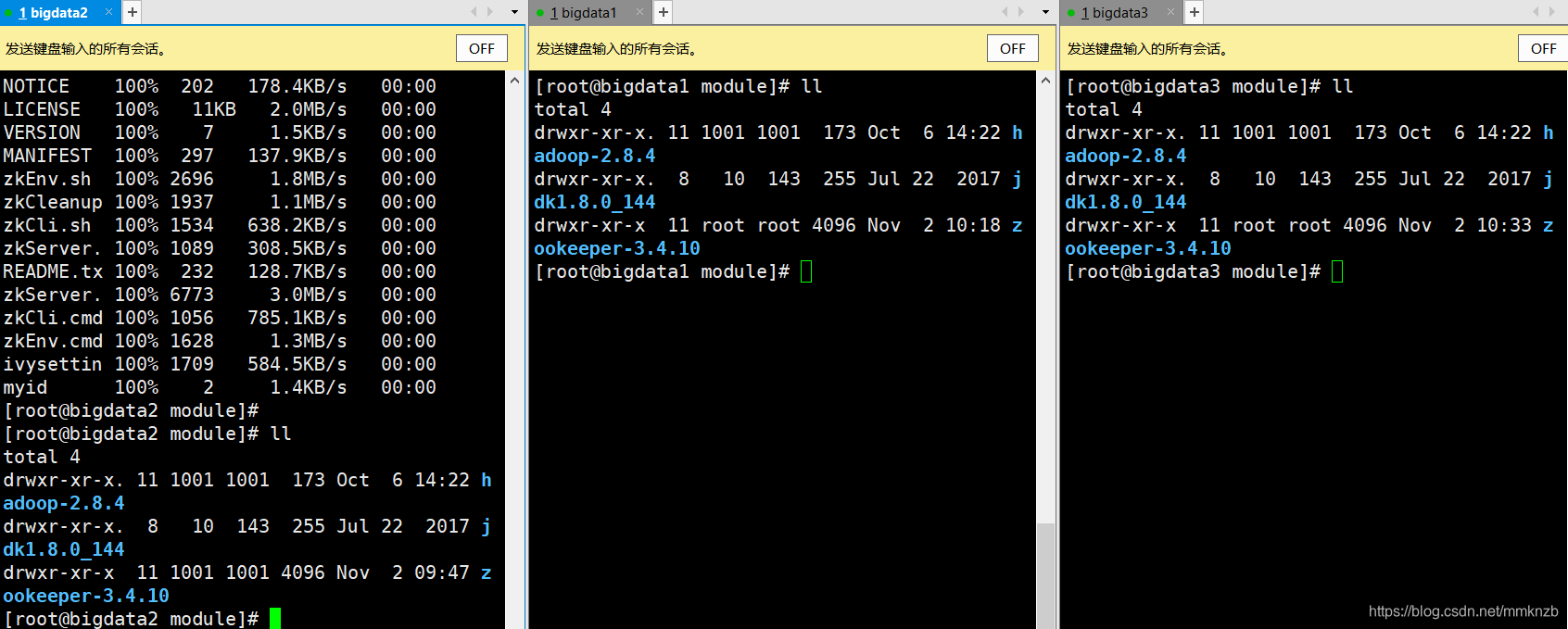
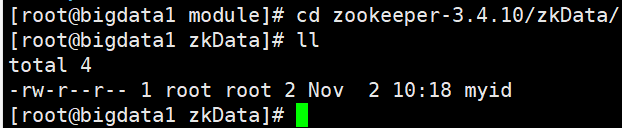
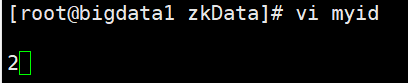
10.将bigdata1和bigdata3的myid进行修改
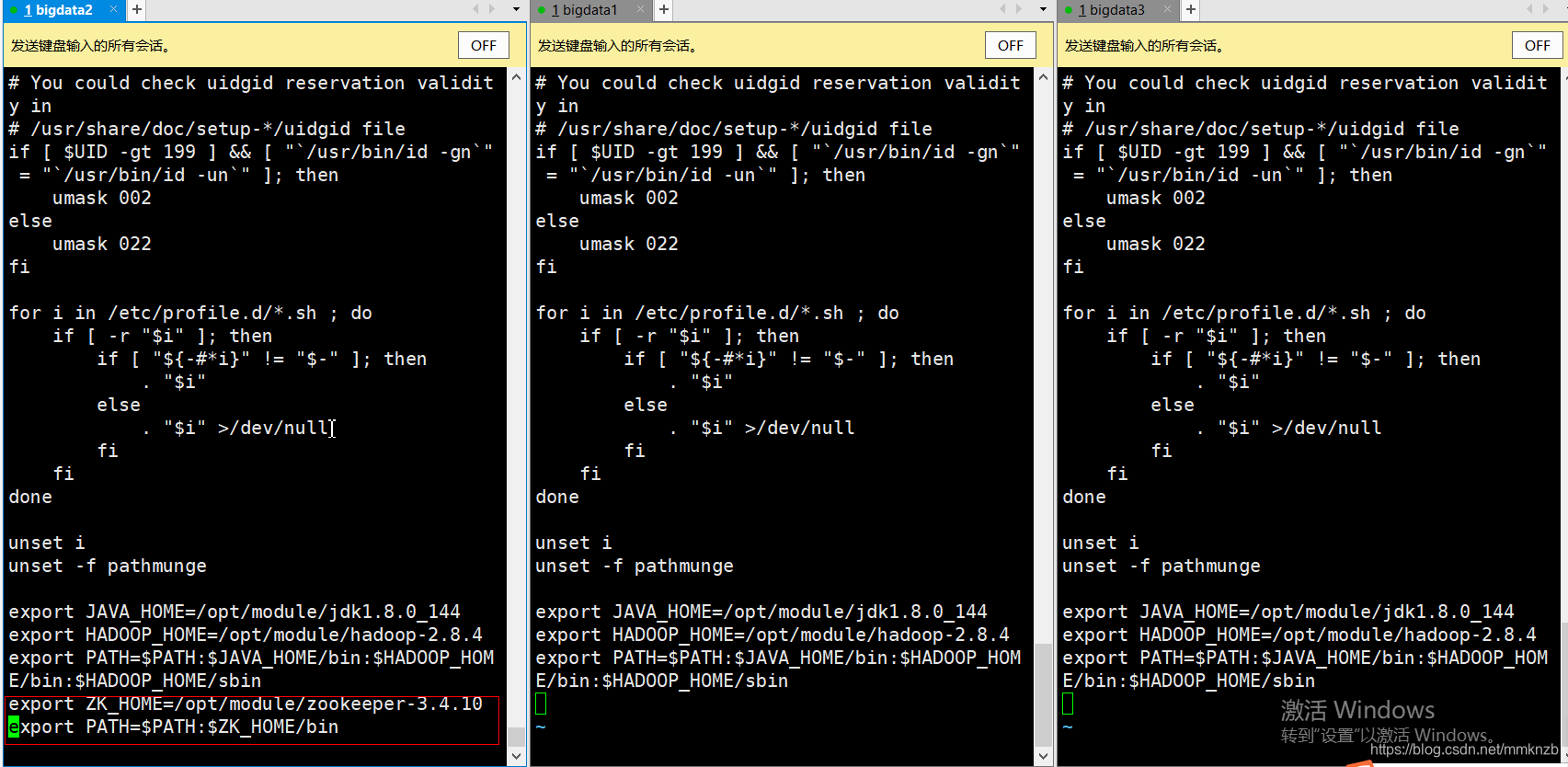
11.配置环境变量
export ZK_HOME=/opt/module/zookeeper-3.4.10
export PATH=$PATH:$ZK_HOME/bin


12.检验安装配置成功
输入zkS然后按tab键,如果可以自动将其补全为zkServer.就代表配置成功


基础命令
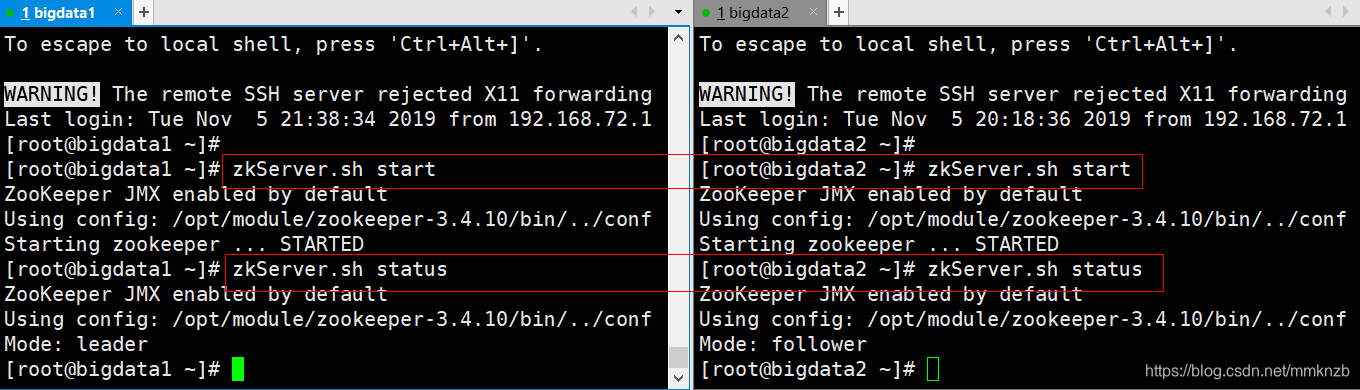
启动zookeeper(集群,最少两个)
zkServer.sh start
查看当前节点的zk状态
zkServer.sh status
启动zk客户端
进入到ZK目录下
cd /opt/module/zookeeper-3.4.10/
执行zkCli命令
bin/zkCli.sh

显示所有操作命令:help

普通创建(永久节点):create


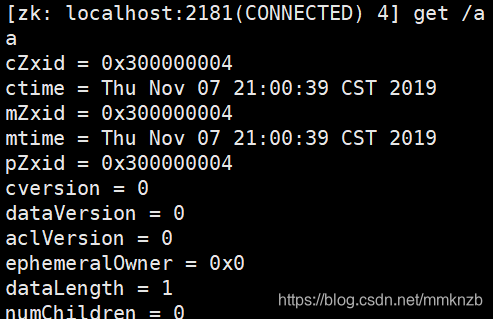
获得节点的值:get path [watch]

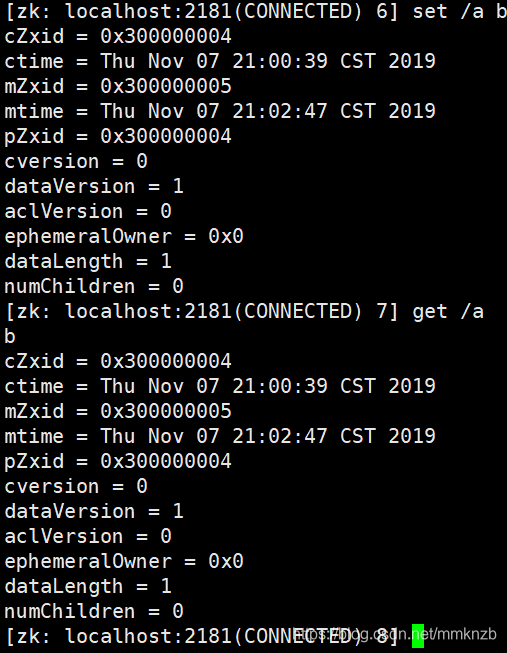
设置节点的具体值:set

使用 ls 命令来查看当前znode中所包含的内容



删除节点:delete和 递归删除节点:rmr


ZK的选举原理(过半机制,奇数原则)
过半机制:
当ZK集群中的超过一般的节点都可以正常工作,就代表这个集群已经启动了。
当集群启动后,会进行全员投票,当某一节点获得半数及以上的票时,那个节点就会变为leader节点,其他的节点仍然是follower节点,如果没有节点获得半数及以上的票的时候,会进行循环,直到有节点获得半数及以上的票。这个时候,ZK集群也就真正的启动起来了
奇数原则:
在学习ZK的时候,就学习到ZK集群的节点数最好是一个以上的奇数。那么为什么是奇数呢?
原因1:在进行选举的时候,如果是偶数,那么就有可能出现两个leader,就会出现脑裂的错误。
原因2:leaderd的选举算法采用了paxos协议
paxos核心思想:当多数server写成功,则任务数据写成功。如果有3个server则2个写成功即可,当有4个或5个server,则3个写成功即可。
如果有3个server,最多允许有一个server挂掉,如果有4个server,则同样最多允许一个server挂掉,因此,可以看出,3台服务器和4台服务器的容灾能力是一样的,为了节省服务器资源,我们通常采用奇数数量,作为服务器部署数量。

















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









