







 本文详细介绍了如何在Linux环境下安装Spark,包括设置伪分布式和完全分布式。首先,通过解压缩文件并配置`spark-env.sh`来搭建伪分布式,将localhost替换为主机名,并成功启动Master和Worker。接着,停止伪分布式服务,关闭防火墙,启用SSH免密登录,修改slaves文件,最后在主节点上启动全分布式集群。
本文详细介绍了如何在Linux环境下安装Spark,包括设置伪分布式和完全分布式。首先,通过解压缩文件并配置`spark-env.sh`来搭建伪分布式,将localhost替换为主机名,并成功启动Master和Worker。接着,停止伪分布式服务,关闭防火墙,启用SSH免密登录,修改slaves文件,最后在主节点上启动全分布式集群。
搭建伪分布式
解压缩文件
tar -zxvf /opt/software/spark-2.1.0-bin-hadoop2.7.tgz -C /opt/module/

因为spark和hadoop的目录结构相似,都有bin和sbin目录,为了防止冲突,就不配合环境变量了

进入conf目录,对配置文件重命名
mv spark-env.sh.template spark-env.sh

进入配置文件
vi spark-env.sh
shift+G跳到最后一行
增加配置
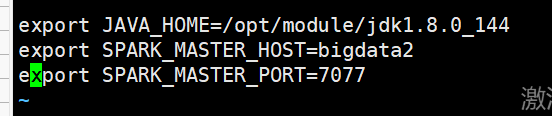
export JAVA_HOME=/opt/module/jdk1.8.0_144
export SPARK_MASTER_HOST=bigdata2
export SPARK_MASTER_PORT=7077
对slaves.template文件重命名

将文件最后一行的localhost改为自己的主机名

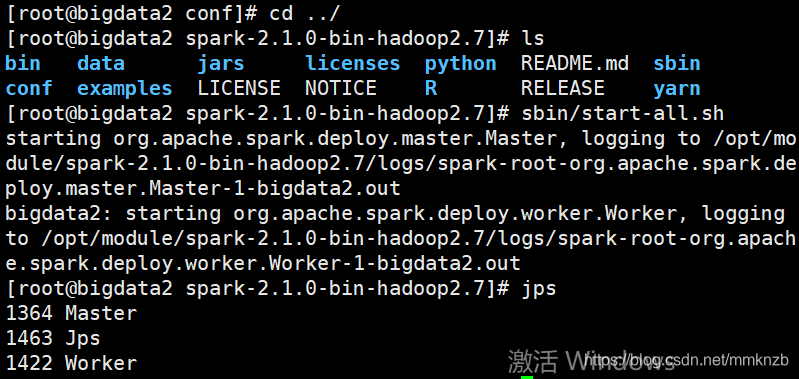
保存完毕之后,启动spark
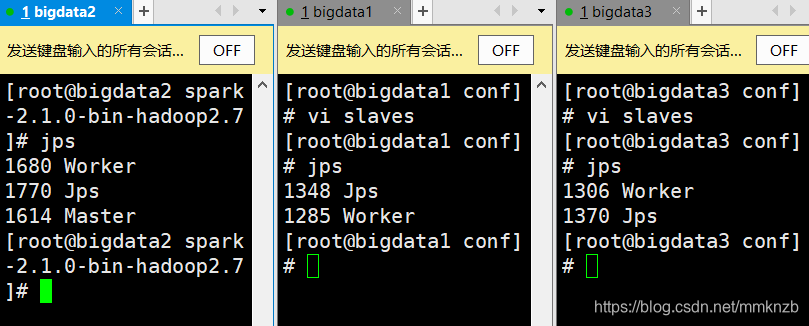
jps查看进程有Master和Worker进程
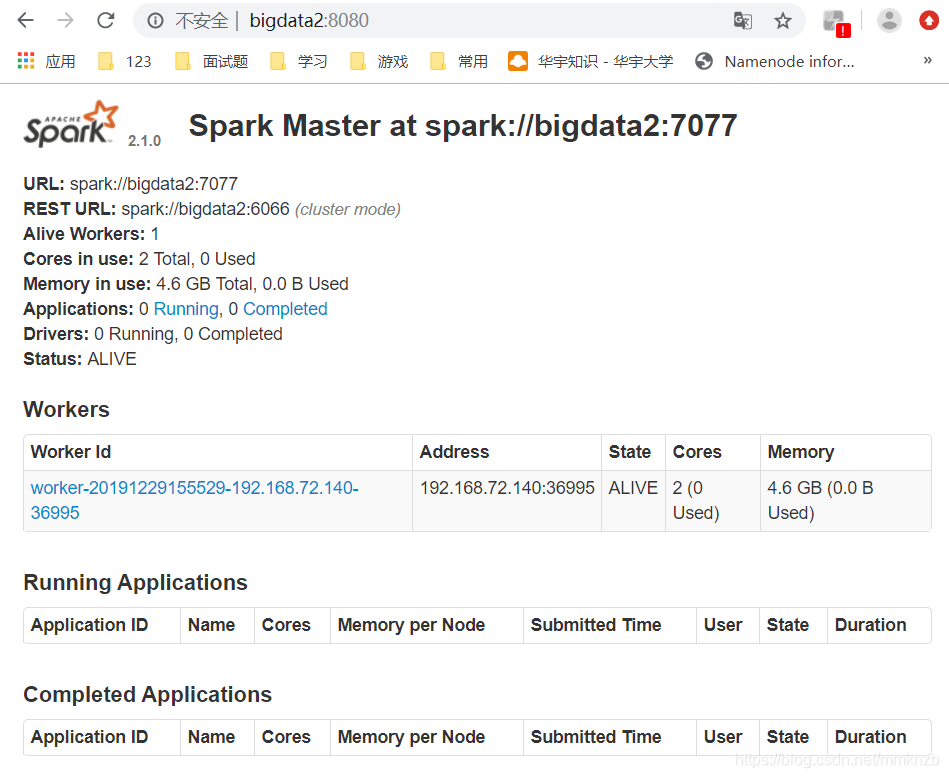
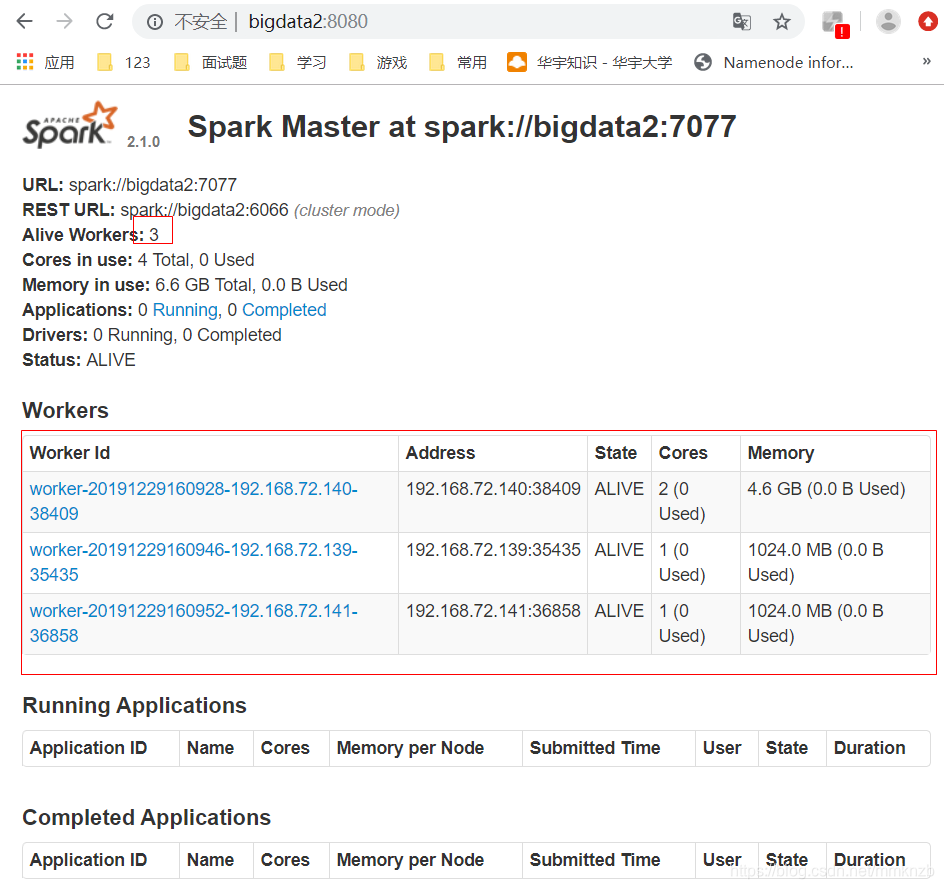
然后就可以通过浏览器访问8080页面
搭建完全分布式
搭建完全分布式之前,需要把伪分布式的服务先停掉
sbin/stop-all.sh
还需要关闭防火墙与SSH免密登录
将slaves的最后一行改为想要的子节点名(ip)即可,别的都跟主节点之前的配置一样
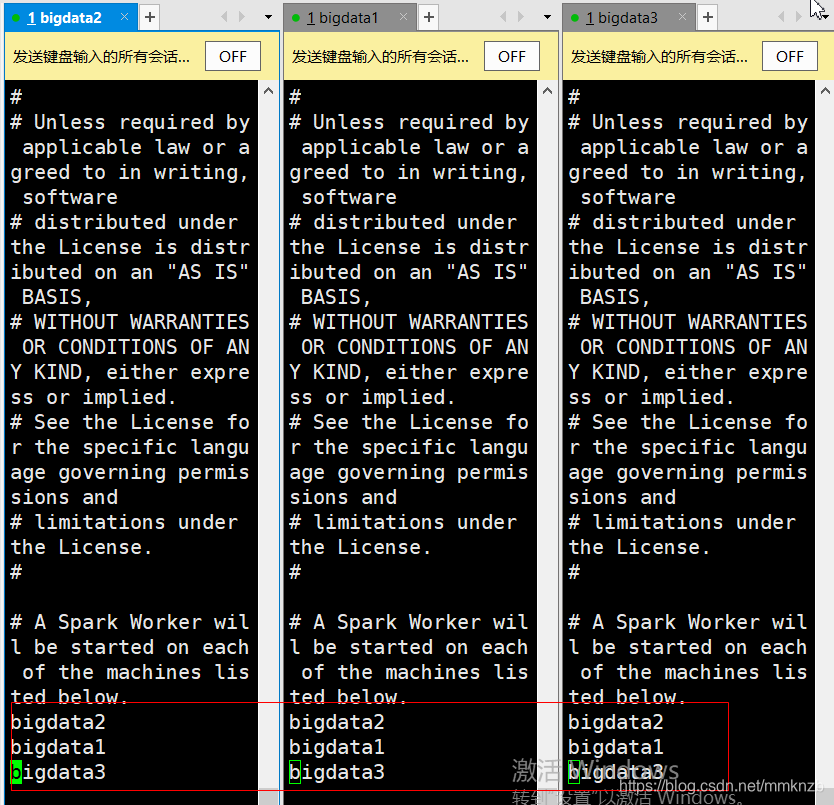
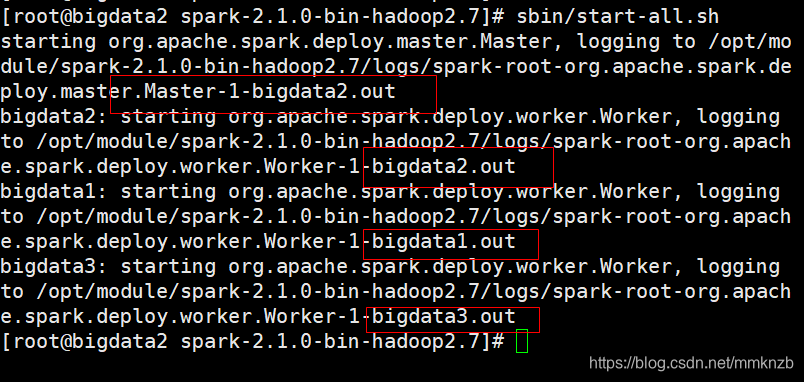
主节点启动集群
sbin/start-all.sh

















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









