



Spark 第四章 Spark RDD 实验手册
实验4.1:RDD 的创建
创建一个文档:324.txt
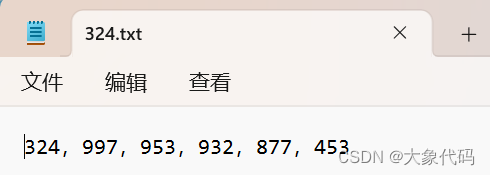
虚拟机创文件:
上传文件到虚拟机里:把文件拖到finalshell
启动pyspark:pyspark(小写)
使用文件创建RDD

实验4.2:常见RDD算子练习

注意:用英文空格(文档和操作中中英文符号要一致)
>>> rdd=sc.textFile("/home/node1/324.txt")
>>> rdd1=rdd.flatMap(lambda x:x.split(','))#赋值且不用collect--输出的是列表,不是rdd
>>> rdd1.map(lambda x : int(x)+1000).collect()
[1324, 1997, 1953, 1932, 1877, 1453]
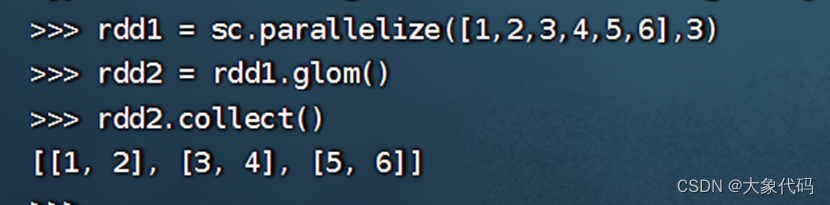

每个分区
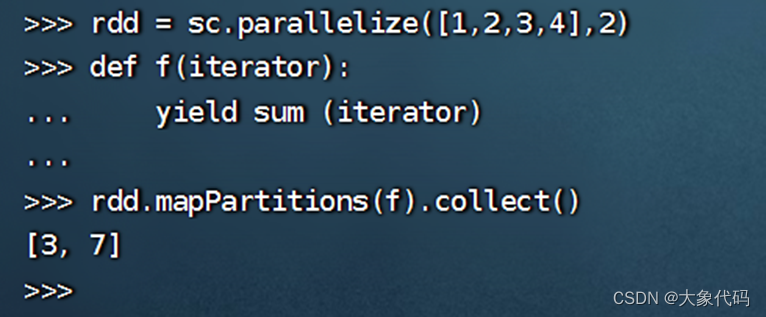
方法一:
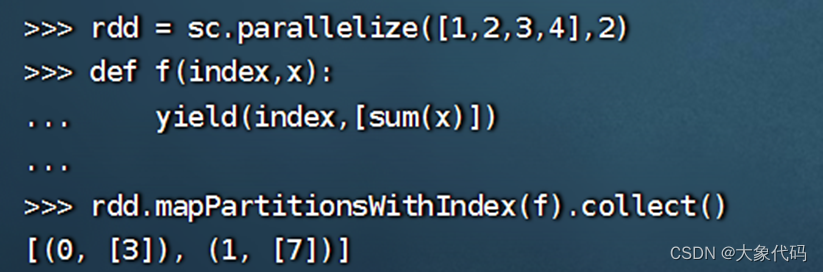
方法二:
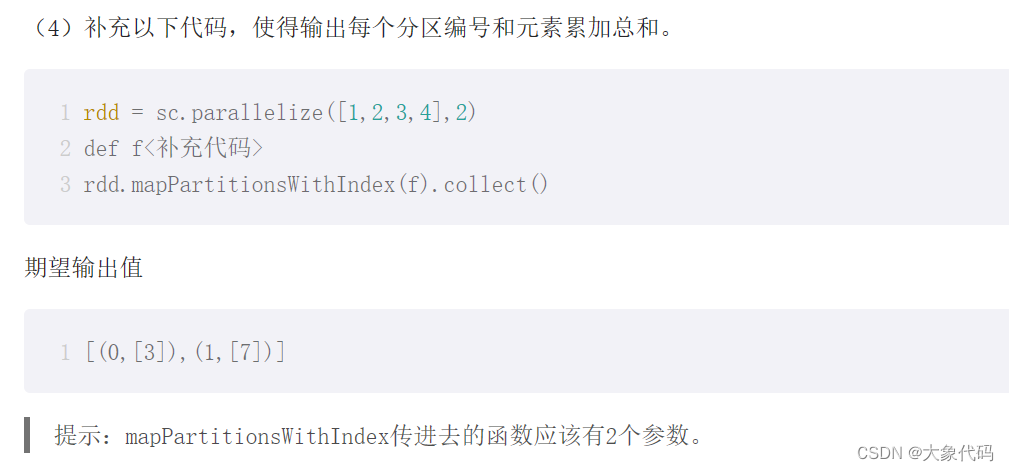
>>> rdd = sc.parallelize([1,2,3,4],2)
>>> def f(index,x):
... lst=[]
... lst.append(sum(x))
... yield index,lst
...
>>> rdd.mapPartitionsWithIndex(f).collect()
[(0, [3]), (1, [7])]
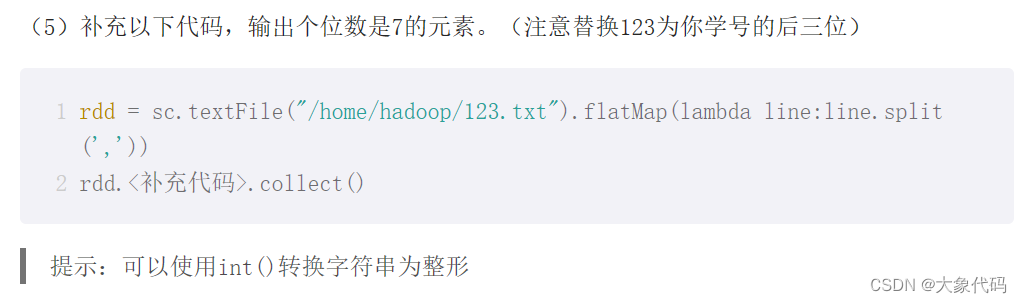
rdd = sc.textFile("/home/node1/324.txt").flatMap(lambda line:line.split(','))
rdd.filter(lambda x: x[-1] == '7').collect()
结果:
['997', '877'] 这是一个 lambda 表达式,用于判断一个字符串的最后一位是否为数字 7。具体来说,lambda x 代表输入参数,x[-1] 代表输入参数的最后一位,'7' 代表数字 7。该 lambda 表达式返回 True 或 False,取决于输入参数的最后一位是否为数字 7。

sc.parallelize([1,1,1,2,3,2,3]).distinct().collect()
结果:
[1, 2, 3] 
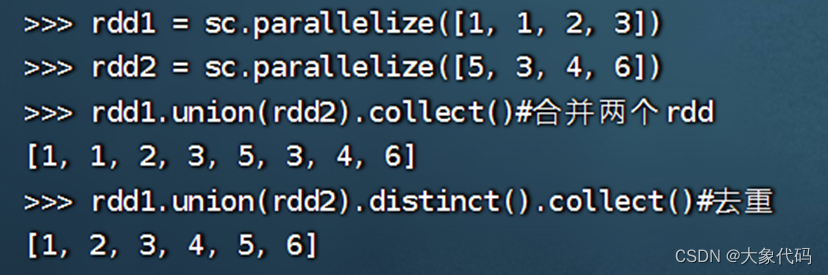

>>> rdd1 = sc.parallelize([1,4,2,3])
>>> rdd2 = sc.parallelize([5,3,4,6])
>>> rdd1.intersection(rdd2).collect()
[3, 4]
>>> rdd = sc.textFile("/home/node1/324.txt").flatMap(lambda line:line.split(','))
>>> rdd.sortBy(lambda x:int(x),False).collect()
['997', '953', '932', '877', '453', '324'] 
>>> rdd = sc.parallelize([(101,'Mike'),(134,'John'),(123,'Mary')])
>>> rdd.sortBy(lambda x:x[0],False).collect()
[(134, 'John'), (123, 'Mary'), (101, 'Mike')]
#sortBy:默认正序;False:倒序
>>> rdd = sc.parallelize([(101,'Mike',23),(134,'John',45),(123,'Mary',18)])
>>> rdd.sortBy(lambda x:x[2],False).collect()
[(134, 'John', 45), (101, 'Mike', 23), (123, 'Mary', 18)]
方法一:
>>> rdd1 = sc.parallelize([1,1,2,3,5,8])
>>> rdd1.groupBy(lambda x:x%2).map(lambda x :(x[0],list(x[1]))).collect()
[(0, [2, 8]), (1, [1, 1, 3, 5])]
方法二:
>>> rdd1 = sc.parallelize([1,1,2,3,5,8])
>>> rdd1.groupBy(lambda x:x%2).mapValues(lambda x :list(x)).collect()
[(0, [2, 8]), (1, [1, 1, 3, 5])]

>>> sc.parallelize([(1, 2), (2, 3), (3,4),(4,5),(5,6),(6,7)],3).partitionBy(2).glom().collect()
[[(2, 3), (4, 5), (6, 7)], [(1, 2), (3, 4), (5, 6)]]
>>> sc.parallelize([(1, 2), (2, 3), (3,4),(4,5),(5,6),(6,7)],3).repartition(2).glom().collect()
[[(1, 2), (2, 3), (5, 6), (6, 7)], [(3, 4), (4, 5)]]
>>> sc.parallelize([(1, 2), (2, 3), (3,4),(4,5),(5,6),(6,7)],3).coalesce(2).glom().collect()
[[(1, 2), (2, 3)], [(3, 4), (4, 5), (5, 6), (6, 7)]]





>>> from operator import add
>>> sc.parallelize([1, 2, 3, 4, 5]).reduce(add)
15

>>> sc.parallelize([(1, 2),(3, 4), (3, 5),(1, 4)]).reduceByKey(lambda x,y:x+y).collect()
[(1, 6), (3, 9)]

>>> rdd = sc.textFile("/home/node1/324.txt").flatMap(lambda line : line.split(','))
>>> rdd.count()#count:返回此RDD中的元素数
6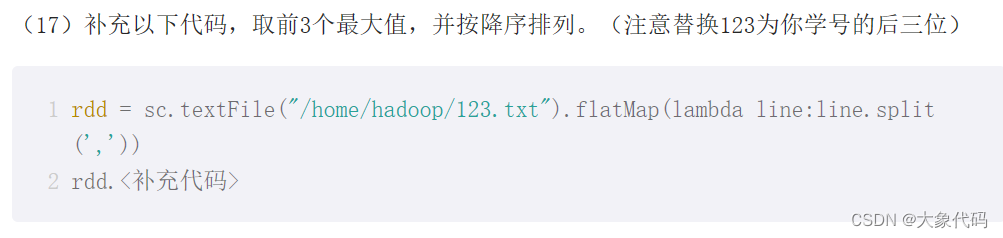

>>> rdd = sc.textFile("/home/node1/324.txt").flatMap(lambda line : line.split(','))
>>> rdd.top(3)
['997', '953', '932']


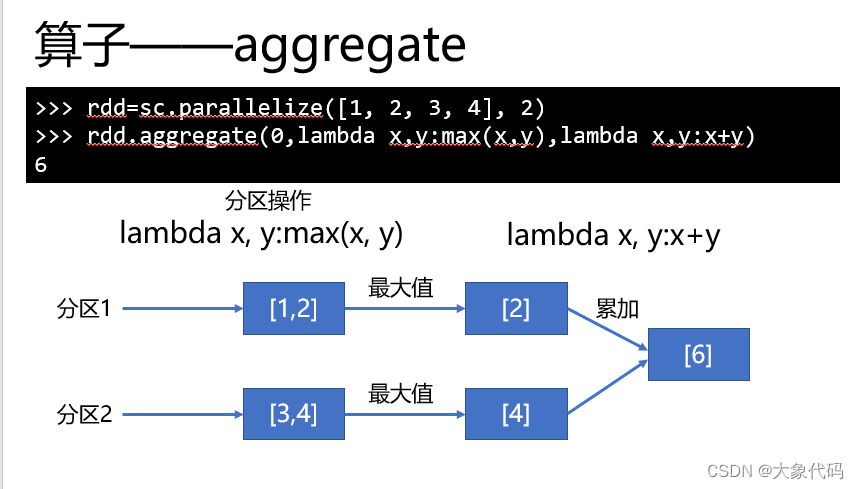
初始值不一样的话,会有不一样的结果
>>> rdd = sc.parallelize([1,2,3,4,5,6],2)
>>> rdd.aggregate(0,lambda x,y:max(x,y),lambda x,y:x+y)
9

aggregate:先对局部聚合,再对全局聚合
>>> rdd = sc.parallelize(["H","e","l","l","o","F","r","a","n","k"],2)
>>> rdd.glom().collect()#看分区情况
[['H', 'e', 'l', 'l', 'o'], ['F', 'r', 'a', 'n', 'k']]
>>> rdd.aggregate(' ',lambda x,y:str(x)+str(y),lambda x,y:str(x)+str(y))
' Hello Frank'

方法一:
>>> rdd = sc.parallelize([("a", 1), ("b", 3), ("a", 2), ("b", 4)])
>>> rdd.groupByKey().mapValues(list).collect()
[('b', [3, 4]), ('a', [1, 2])]
方法二:
>>> rdd = sc.parallelize([("a", 1), ("b", 3), ("a", 2), ("b", 4)])
>>> rdd.groupByKey().map(lambda x:(x[0],list(x[1]))).collect()
[('b', [3, 4]), ('a', [1, 2])]

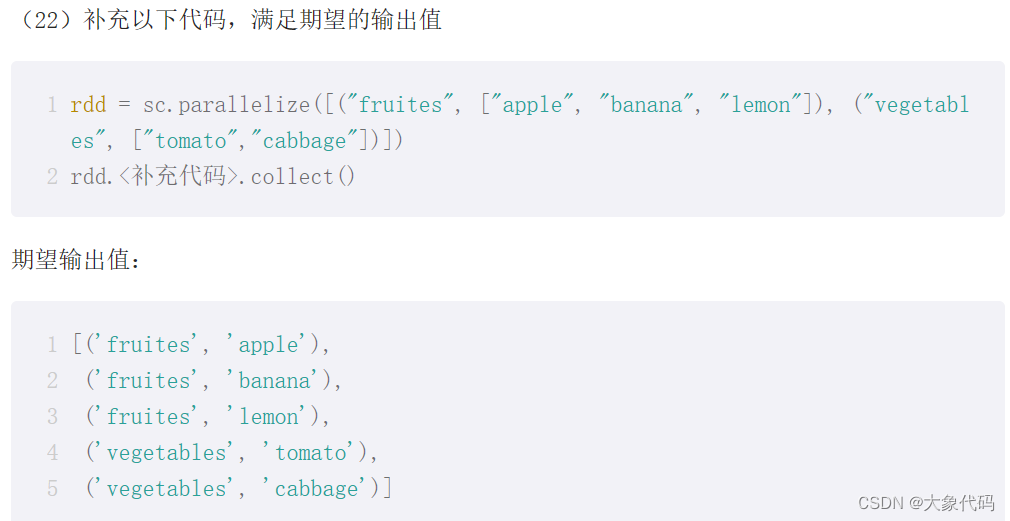
rdd = sc.parallelize([("fruites", ["apple", "banana", "lemon"]), ("vegetables", ["tomato","cabbage"])])
>>> def upperWordInList(lst):
... r = []
... for x in lst:
... r.append(x.capitalize())
... return r
...
>>> rdd.mapValues(upperWordInList).collect()
[('fruites', ['Apple', 'Banana', 'Lemon']), ('vegetables', ['Tomato', 'Cabbage'])]
>>> rdd = sc.parallelize([("fruites", ["apple", "banana", "lemon"]), ("vegetables", ["tomato","cabbage"])])
>>> def f(rdd):
... return rdd
...
>>> rdd.flatMapValues(f).collect()
[('fruites', 'apple'), ('fruites', 'banana'), ('fruites', 'lemon'), ('vegetables', 'tomato'), ('vegetables', 'cabbage')]
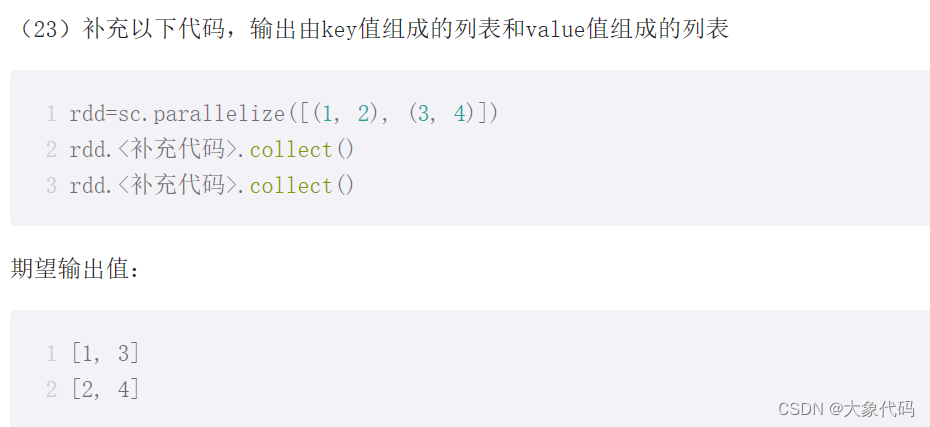
>>> rdd=sc.parallelize([(1, 2), (3, 4)])
>>> rdd.keys().collect()
[1, 3]
>>> rdd.values().collect()
[2, 4]
>>> rdd = sc.parallelize([("fruites", ["apple", "banana", "lemon"]), ("vegetables", ["tomato","cabbage"])]).flatMapValues(lambda x:x)
>>> rdd.countByKey()#统计每个Key键的元素数
defaultdict(<class 'int'>, {'vegetables': 2, 'fruites': 3})

>>> rdd = sc.parallelize([ ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)], 2)
>>> rdd.reduceByKey(lambda x,y :x+y).collect()
[('mouse', 6), ('cat', 19), ('dog', 12)]
>>> rdd = sc.parallelize([ ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)], 2)
>>> rdd.aggregateByKey(0,lambda x,y:x+y,lambda x,y:x+y).collect()
[('mouse', 6), ('cat', 19), ('dog', 12)]

>>> x = sc.parallelize([("a", 1), ("b", 4)])
>>> y = sc.parallelize([("a", 2), ("a", 3)])
>>> x.join(y).collect()
[('a', (1, 2)), ('a', (1, 3))]
>>> x.leftOuterJoin(y).collect()
[('a', (1, 2)), ('a', (1, 3)), ('b', (4, None))]
>>> y.rightOuterJoin(x).collect()
[('a', (2, 1)), ('a', (3, 1)), ('b', (None, 4))]
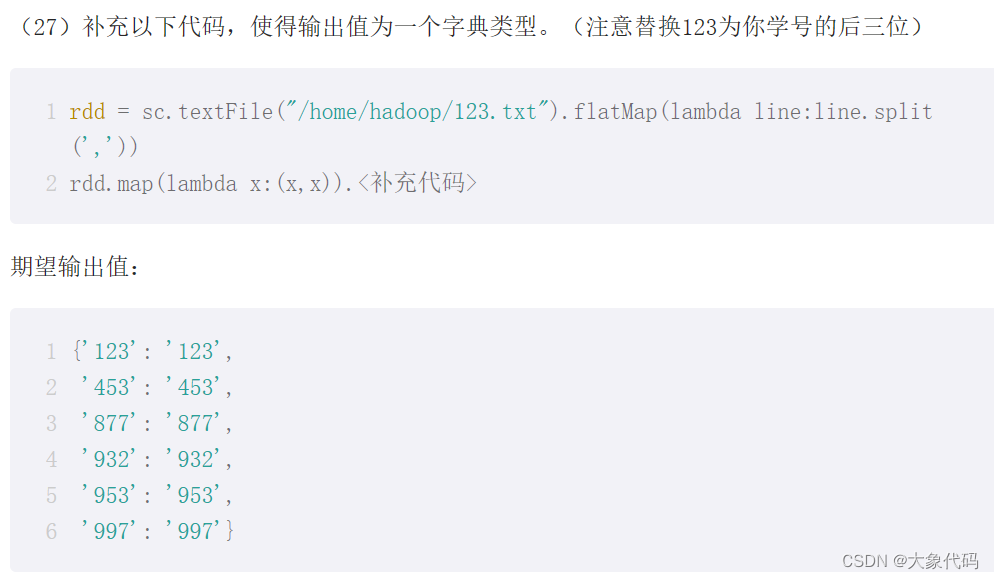
>>> rdd = sc.textFile("/home/node1/324.txt").flatMap(lambda line:line.split(','))
>>> rdd.collect()
['324', '997', '953', '932', '877', '453']
>>> rdd1=rdd.map(lambda x:(x,x))
>>> rdd1.collectAsMap()
{'932': '932', '324': '324', '997': '997', '953': '953', '877': '877', '453': '453'}

>>> rdd = sc.parallelize([("a",1),("b",1),("a", 1)])
>>> rdd.collectAsMap().keys()
dict_keys(['a', 'b'])
>>> rdd.countByKey().items()
dict_items([('a', 2), ('b', 1)])
第五章 SparkSQL 实验手册
【实验名称】 实验5.1:RDD DataFrame API 练习
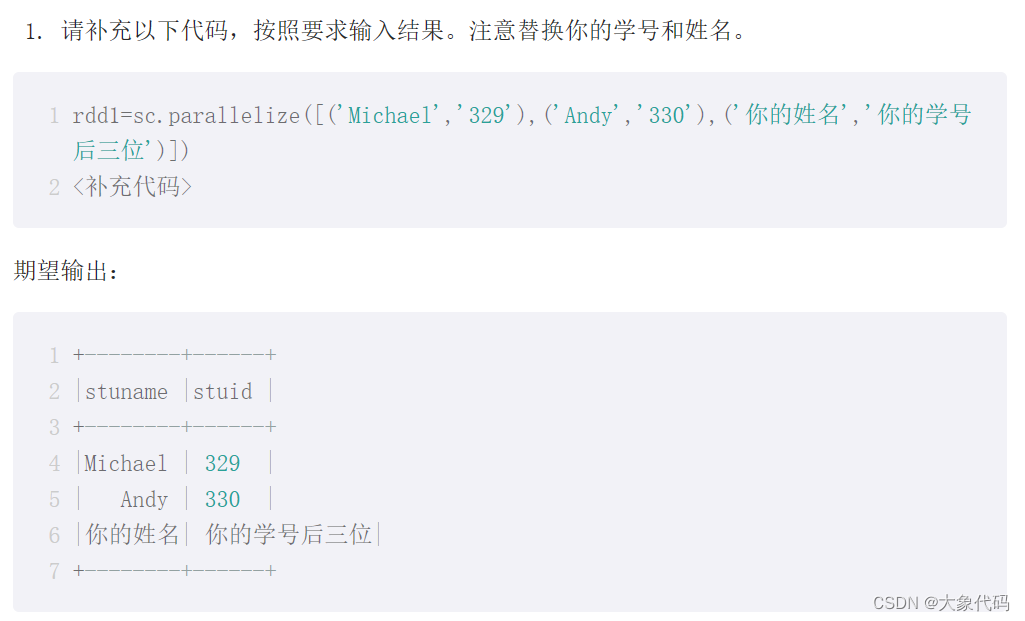
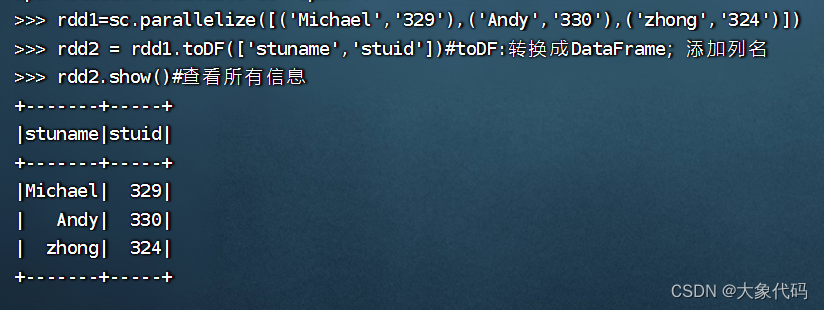
>>> from pyspark.sql import Row
>>> rdd=sc.parallelize([('Michael','329'),('Andy','330'),('mei','324')])
>>> df=spark.createDataFrame(rdd,['stuname','stuid'])
>>> df.collect()
[Row(stuname='Michael', stuid='329'), Row(stuname='Andy', stuid='330'), Row(stuname='mei', stuid='324')]
#data用rdd,指定scheme为列表
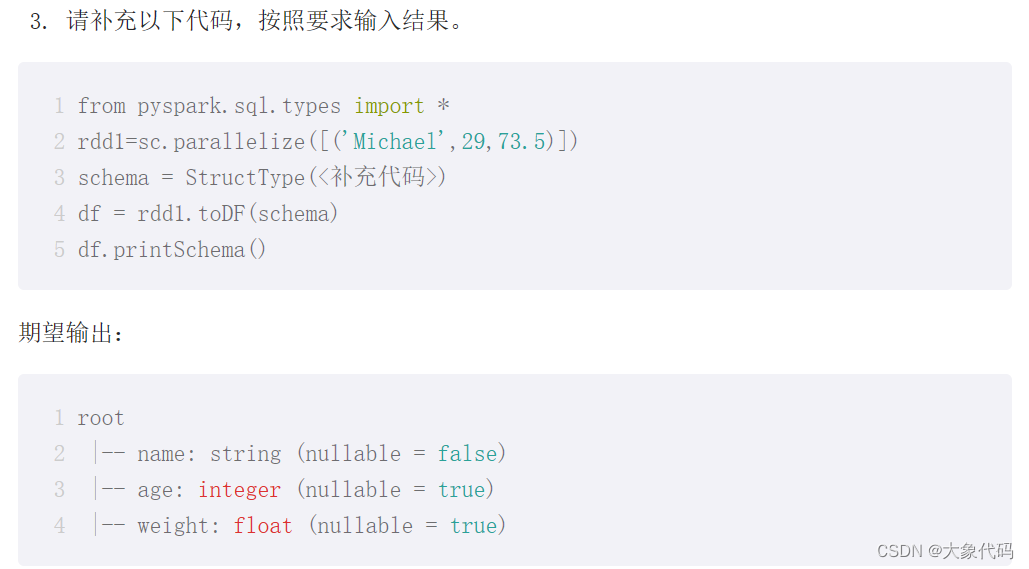
>>> from pyspark.sql.types import *
>>> rdd1=sc.parallelize([('Michael',29,73.5)])
>>> schema = StructType([StructField("name", StringType(), False),StructField("age", IntegerType(), True),StructField("weight", FloatType(), True)])
>>> df = rdd1.toDF(schema)
>>> df.printSchema()
root
|-- name: string (nullable = false)
|-- age: integer (nullable = true)
|-- weight: float (nullable = true)

>>> rdd = sc.parallelize( [{'name': 'Alice', 'age': 25}])
>>> spark.createDataFrame(rdd, "name:string,age:int").printSchema()
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)

>>> rdd = sc.parallelize( [('Michael','329')])
>>> spark.createDataFrame(rdd, "name: string, age: int").dtypes
[('name', 'string'), ('age', 'int')]
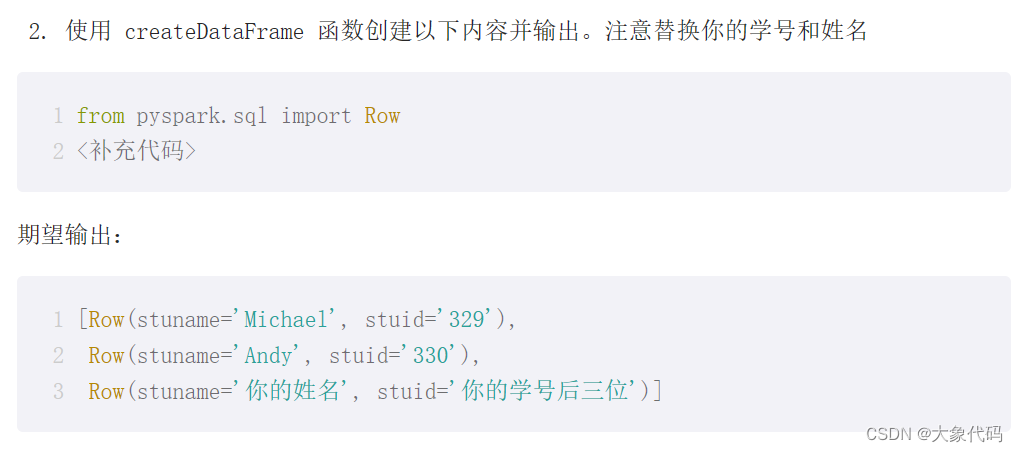
【实验名称】 实验5.2:自行设计实现RDD转为DataFrame
【实验要求】
请按要求完成以下实验内容,要求在实验报告记录你的思路,代码和结果。
1、修改 emp.csv 的第一行数据 SMITH 为你的姓名。上传 emp.csv 和 dept.csv 文件到虚拟机。
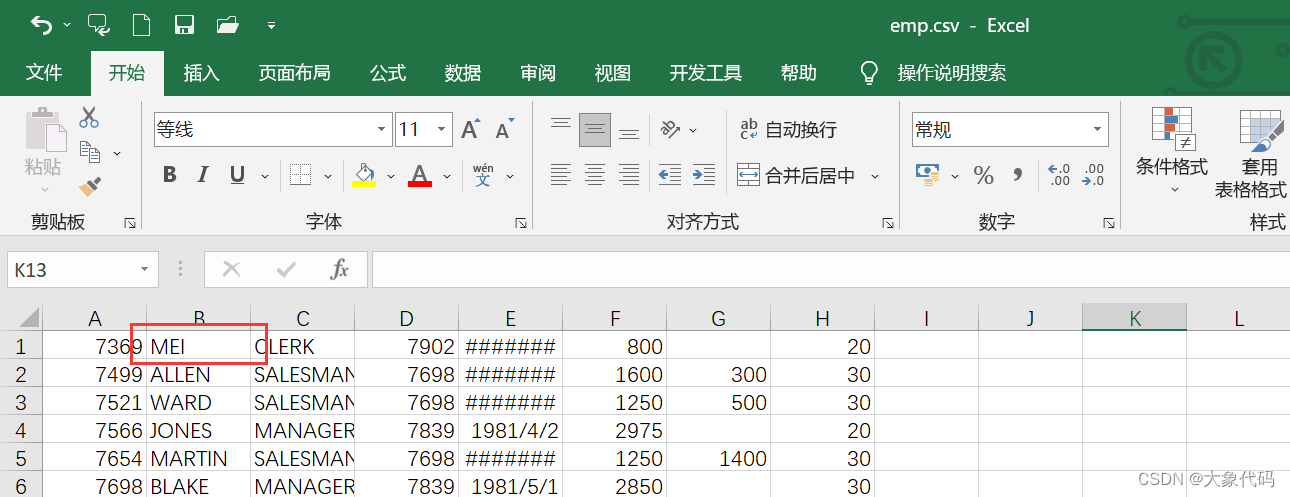
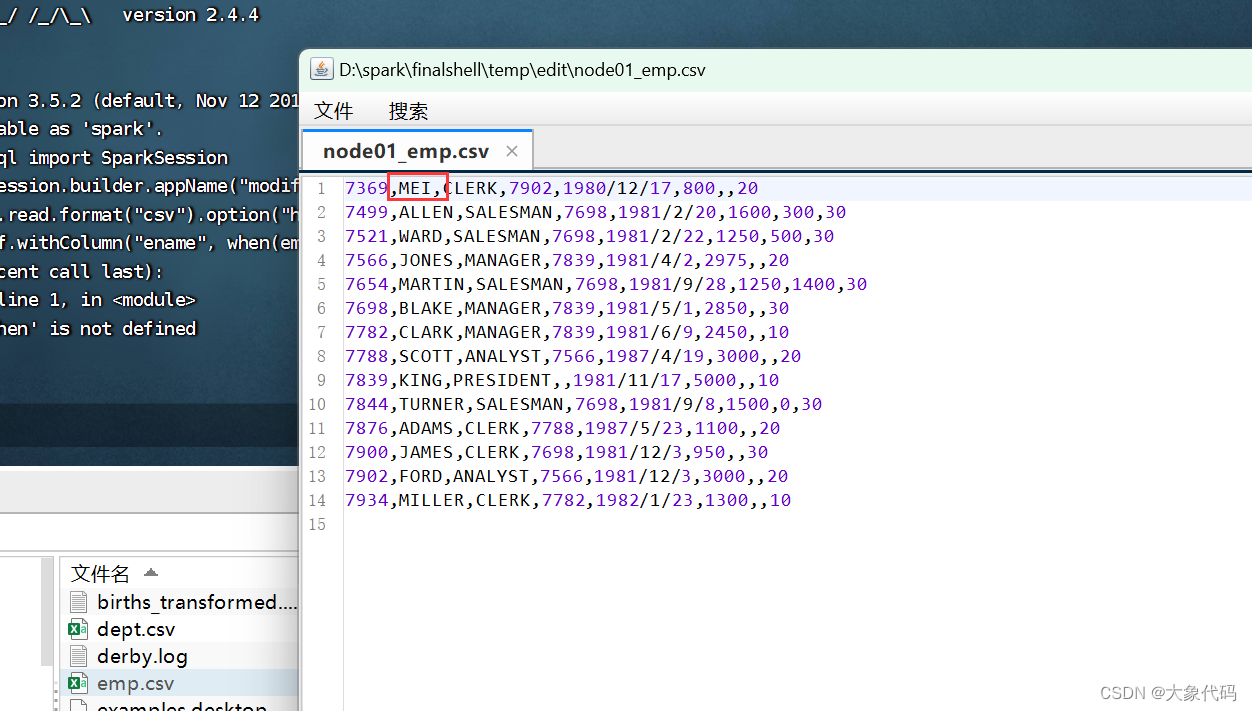
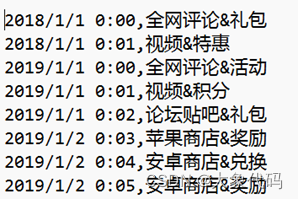
练习每行的数据分为2列包含“日期时间,来源&单词”,日期时间中间有个空格,数据为data_test.csv。统计每天排名第一的热词。分别用spark与pandas来完成上述第2问的数据处理
方法一:pandas(jupyter notebook)
import pandas as pd #导入数据包
data=pd.read_csv('data_test.csv', encoding='gbk', names=['日期时间','来源&单词']) #读取数据并指定列名
print(data)
# 分割日期时间和来源&单词列
#关键字参数n来限制分割的次数为1次,避免传递多余的参数给split()函数
data[['日期', '时间']] = data['日期时间'].str.split(' ', n=1, expand=True)
data[['来源', '单词']] = data['来源&单词'].str.split('&', n=1, expand=True)
# 统计每天排名第一的热词
words = data.groupby('日期').apply(lambda x: x['单词'].value_counts().idxmax()).reset_index()
# 重命名列名
words.columns = ['日期', '热词']
# 输出每天排名第一的热词
print(words)Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理。Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe、Series、分组对象、各种时间序列等。
代码中的data.groupby('日期')表示按照日期进行分组。
然后,apply(lambda x: x['单词'].value_counts().idxmax())表示对每个日期分组应用一个lambda函数,该lambda函数计算该日期分组中单词出现次数最多的单词(使用value_counts函数计算每个单词的出现次数,然后使用idxmax函数获取出现次数最多的单词)。
idxmax()返回最大值的索引值
最后,reset_index()函数用于将结果重新设置为DataFrame,并将日期和对应的出现次数最多的单词作为列。
andas.DataFrame.reset_index
函数作用:重置索引或其level。
重置数据帧的索引,并使用默认索引。如果数据帧具有多重索引,则此方法可以删除一个或多个level。
函数主要有以下几个参数:reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
各个参数介绍:
level:可以是int, str, tuple, or list, default None等类型。作用是只从索引中删除给定级别。默认情况下删除所有级别。
drop:bool, default False。作用是删除所有索引所在列。这会将索引重置为默认的整数索引。
inplace:bool, default False。修改数据帧(不要创建新对象)。
col_level:int or str, default=0。如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一层。
col_fill:object, default。如果列有多个级别,则确定其他级别的命名方式。如果没有,则复制索引名称。
另外一种写法:pandas
import pandas as pd #导入数据包
data=pd.read_csv('data_test.csv', encoding='gbk', names=['日期时间','来源&单词']) #读取数据并指定列名
print(data)
# 分割日期时间和来源&单词列
#关键字参数n来限制分割的次数为1次,避免传递多余的参数给split()函数
data[['日期', '时间']] = data['日期时间'].str.split(' ', n=1, expand=True)
data[['来源', '单词']] = data['来源&单词'].str.split('&', n=1, expand=True)
# 统计每天排名第一的热词
daily_top_words = data.groupby('日期')['单词'].value_counts().groupby(level=0).head(1)
daily_top_words = daily_top_words.reset_index() # 将Series转换为DataFrame
daily_top_words.columns = ['日期', '热词','次数'] # 重命名列名,一一对应(列数)
# 输出结果
print(daily_top_words)daily_top_words = data.groupby('日期')['单词'].value_counts().groupby(level=0).head(1)
这段代码是使用pandas库对数据进行处理的,以下是代码的解释:
1. `data.groupby('日期')['单词']`:这一部分是将数据按照日期进行分组,并选择"单词"列作为分组的依据。
2. `.value_counts()`:这一部分是对每个日期下的单词进行计数,得到每个单词出现的频次。
3. `.groupby(level=0)`:这一部分是对计数结果再次按照日期进行分组。
4. `.head(1)`:这一部分是选择每个日期下频次最高的单词,只保留一个结果。
综合起来,这段代码的作用是找出每个日期下出现频次最高的单词。结果是一个DataFrame,包含日期和对应的频次最高的单词。
请注意,这段代码需要使用pandas库,并且数据应该是一个DataFrame对象。如果你想在Spark中使用类似的功能,可以考虑使用Spark的DataFrame API或者RDD的相关操作来实现类似的功能。
方法二:spark
>>> import codecs
>>> with codecs.open("data_test.csv", encoding="gbk") as file:
... data = file.readlines()
...
>>> data_rdd = sc.parallelize(data)
>>> data_rdd.collect()
['2018/1/1 0:00,全网评论&礼包\r\n', '2018/1/1 0:01,视频&特惠\r\n', '2019/1/1 0:00,全网评论&活动\r\n', '2019/1/1 0:01,视频&积分\r\n', '2019/1/1 0:02,论坛贴吧&礼包\r\n', '2019/1/2 0:03,苹果商店&奖励\r\n', '2019/1/2 0:04,安卓商店&兑换\r\n', '2019/1/2 0:05,安卓商店&奖励\r\n']
>>> data_rdd = data_rdd.map(lambda line: line.strip().split(",")) \
... .map(lambda data: (data[0].split(" ")[0], data[1].split("&")[1])) \
... .map(lambda data: ((data[0], data[1]), 1)) \
... .reduceByKey(lambda a, b: a + b) \
... .map(lambda data: (data[0][0], data[0][1], data[1])) \
... .groupBy(lambda data: data[0]) \
... .map(lambda group: (group[0], max(group[1], key=lambda data: data[2])[1]))
>>> for row in data_rdd.collect():
... print(row[0], row[1])
...
2018/1/1 特惠
2019/1/2 奖励
2019/1/1 礼包
编码问题:
Python的codecs模块来处理编码问题
可以尝试使用codecs.open函数,并指定其他可能的编码格式来打开文件。例如,你可以尝试使用"gbk"编码格式。
# 打开文件并读取数据
with codecs.open("data_test.csv", encoding="gbk") as file:
data = file.readlines()
# 创建RDD
data_rdd = sc.parallelize(data)解释:
这段代码使用`codecs.open`函数打开一个名为"data_test.csv"的文件,并指定了文件的编码格式为"gbk"。
`codecs.open`是一个Python内置的函数,用于以指定的编码格式打开文件。在这个例子中,文件名为"data_test.csv",并且使用"gbk"编码格式打开。
`with`语句用于确保文件在使用完后被正确关闭,以避免资源泄漏。在`with`语句块中,我们将文件对象赋值给变量`file`,并使用`readlines`方法读取文件的所有行。
这段代码假设你正在读取一个以"gbk"编码格式保存的CSV文件,并将文件的内容存储在`data`变量中。请注意,`data`将是一个包含文件中所有行的列表。每一行都是一个字符串。
# 数据预处理
data_rdd = data_rdd.map(lambda line: line.strip().split(",")) \
.map(lambda data: (data[0].split(" ")[0], data[1].split("&")[1])) \
.map(lambda data: ((data[0], data[1]), 1)) \
.reduceByKey(lambda a, b: a + b) \
.map(lambda data: (data[0][0], data[0][1], data[1])) \
.groupBy(lambda data: data[0]) \
.map(lambda group: (group[0], max(group[1], key=lambda data: data[2])[1]))
解释:
这段代码是使用Spark的RDD操作对一个数据集进行处理和转换的示例。
首先,`data_rdd`是一个RDD对象,代表了一个分布式的、不可变的数据集。这个RDD对象通过一系列的转换操作来对数据进行处理。
1. `map(lambda line: line.strip().split(","))`: 使用`map`函数对每一行数据进行操作,使用逗号作为分隔符将每一行拆分成一个字符串列表。
2. `map(lambda data: (data[0].split(" ")[0], data[1].split("&")[1]))`: 使用`map`函数对每个数据元素进行操作,将日期和单词进行提取和转换。
3. `map(lambda data: ((data[0], data[1]), 1))`: 使用`map`函数对每个数据元素进行操作,将日期和单词作为键,将出现次数初始化为1。
4. `reduceByKey(lambda a, b: a + b)`: 使用`reduceByKey`函数对键值对进行操作,将具有相同键的值进行累加。
5. `map(lambda data: (data[0][0], data[0][1], data[1]))`: 使用`map`函数对每个数据元素进行操作,将键值对转换为日期、单词和出现次数的元组。
6. `groupBy(lambda data: data[0])`: 使用`groupBy`函数将数据按照日期进行分组。
7. `map(lambda group: (group[0], max(group[1], key=lambda data: data[2])[1]))`: 使用`map`函数对每个分组进行操作,找到每个日期中出现次数最多的单词。
这部分代码是对每个分组进行操作的`map`函数。它的作用是找到每个日期中出现次数最多的单词。
具体来说,`group`表示每个分组,它是一个包含日期和该日期对应的所有单词和出现次数的元组。`group[0]`表示日期,`group[1]`表示该日期对应的所有单词和出现次数的列表。
在`max(group[1], key=lambda data: data[2])`中,`max`函数用于找到`group[1]`中出现次数最多的单词和对应的出现次数。`key=lambda data: data[2]`表示使用`data[2]`(即出现次数)作为比较的关键字。
最终,`map(lambda group: (group[0], max(group[1], key=lambda data: data[2])[1]))`将返回一个包含日期和出现次数最多的单词的元组。
请注意,这段代码使用了函数式编程的概念,其中`lambda`函数用于定义匿名函数。它在这里用于指定比较的关键字。
最终,这段代码将返回一个包含日期和出现次数最多的单词的元组的RDD对象。
请注意,这段代码使用了函数式编程的概念,其中`lambda`函数用于定义匿名函数。`map`、`reduceByKey`和`groupBy`等函数是Spark提供的用于分布式数据处理的操作函数。
# 显示结果
for row in data_rdd.collect():
print(row[0], row[1])解释:
这段代码使用`collect()`函数将RDD对象`data_rdd`中的数据收集到驱动程序中,并遍历每个元素进行打印。
具体来说,`collect()`函数将RDD中的数据收集到驱动程序中,返回一个包含RDD中所有元素的列表。然后,`for`循环遍历这个列表中的每个元素,将每个元素的第一个和第二个值打印出来。
假设`data_rdd`中的元素是由两个值组成的元组,那么`row[0]`表示元组的第一个值,`row[1]`表示元组的第二个值。通过`print(row[0], row[1])`语句,将每个元组的第一个和第二个值打印出来。
这段代码的目的是将RDD中的数据打印出来,以便查看和调试。请注意,`collect()`函数将所有数据收集到驱动程序中,如果数据量很大,可能会导致内存问题。因此,在实际生产环境中,应该谨慎使用`collect()`函数,并考虑使用其他操作来处理大规模数据集。



















 3306
3306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









