






任务一 企业收入的多样性

import pandas as pd
import numpy as np
df1 = pd.read_csv('./data/test_1/Company.csv')
df2 = pd.read_csv('./data/test_1/Company_data.csv')
###### 处理df2 ######
# 从日期列中分割出年份
df2['年份'] = [x.split('/')[0] for x in df2['日期']]
# 计算p(x_i),因为返回的是序列,所以用transform
df2['p(x_i)'] = df2.groupby(['证券代码','年份'])['收入额'].transform(lambda x: (x/x.sum()))
# 计算log(p(x_i))
df2['log_res'] = df2['p(x_i)'].apply(lambda x: np.log(x))
###### 收入熵指标计算 ######
def my_calculate(x):
multiple_res = x['p(x_i)'] * x['log_res']
res = (-1) * multiple_res.sum()
return res
###### 计算df2收入熵指标 ######
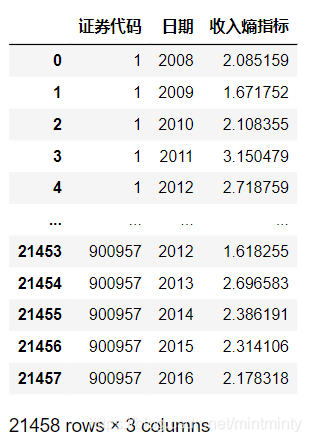
res = df2.groupby(['证券代码','年份']).apply(my_calculate)
res = res.to_frame()
res = res.reset_index()
res.columns = ['证券代码','日期','收入熵指标']
要讲两个表连接在一起,而且是关系型连接,自然想到了merge,但在连接之前要将df1中证券代码的格式统一一下,把#和占位0去掉。
###### 处理df1 ######
df1['证券代码'] = df1['证券代码'].str.replace('#','')
df1['证券代码'] = df1['证券代码'].apply(lambda x: int(x)) # 去除前面的占位0
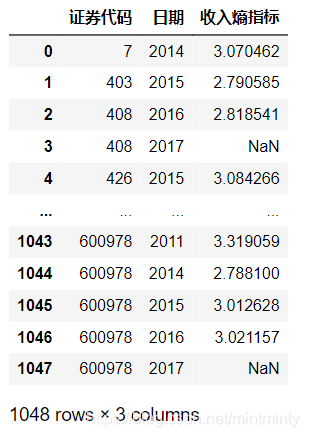
df1.merge(res, on=['证券代码','日期'], how='left')
# 居然报错啦!!
# ValueError: You are trying to merge on int64 and object columns. If you wish to proceed you should use pd.concat
# 转化为int后,提示让我用concat,但是concat 不是处理关系型合并的函数啊喂!
# 于是利用.info()看看有哪些是int类型,强制转化为str
o(* ̄▽ ̄*)ブ
df1['证券代码'] = df1['证券代码'].apply(lambda x: int(x)) # 就这样转化
# 把该转化的转化完
df1.merge(res, on=['证券代码','日期'], how='left') # 就不会报错啦
任务二 组队学习信息表的变换
这道题做了好久,反思一下还是长宽表变形那里的知识点不够熟悉,变来变去 搞了好久~
data = pd.read_csv('./data/test_1/组队信息汇总表.csv',encoding='utf-8')
data
# 这步就开始报错UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcb in position 0: invalid continuation byte
filename = open('./data/test_1/组队信息汇总表.csv')
data = pd.read_csv(filename,encoding='utf-8')
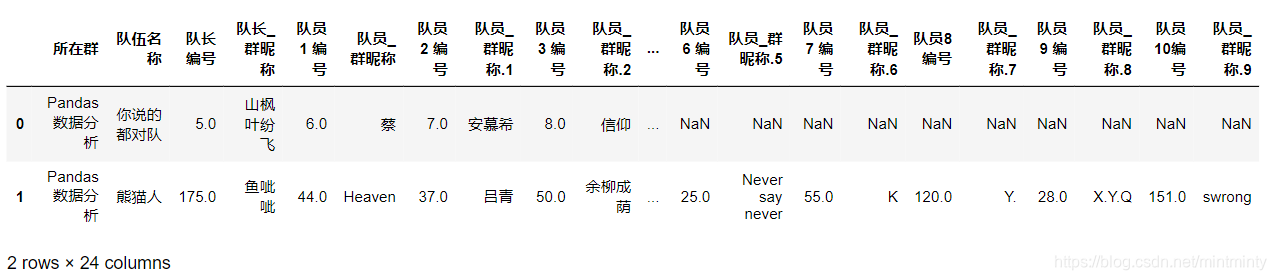
data.head(2)
# 所在群 没什么用,我先删掉~
data = data.drop('所在群',1)
# 要长宽表变形,参考wide_to_long的格式,首先将列索引名字变一下
a = [['编号_'+str(x), '昵称_'+str(x)] for x in range(11)] # 二维list
columns_name = sum(a, []) # 转化为一维list
columns_name = ['队伍名称'] + columns_name
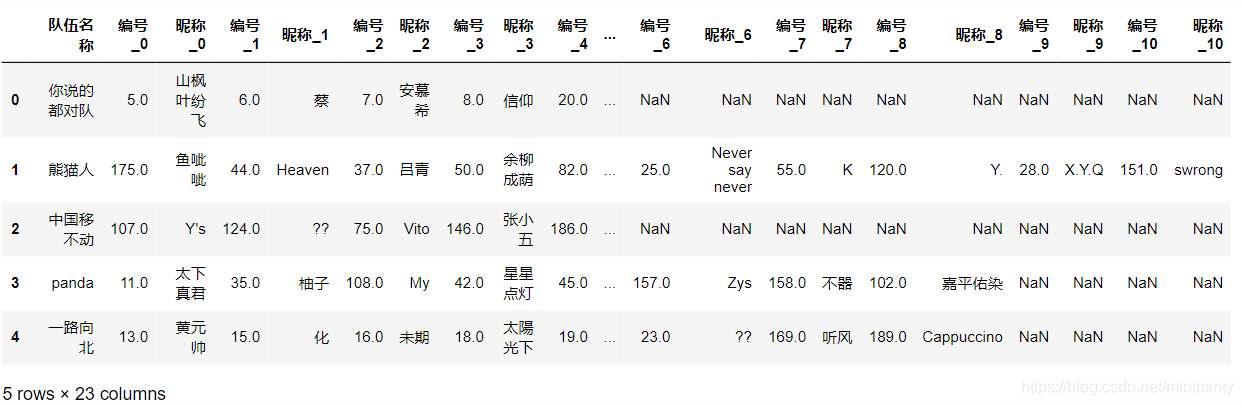
data.columns = columns_name
data.head()
# 开始变形!(突然二次元
res = pd.wide_to_long(data.reset_index(), stubnames=['昵称','编号'], i='队伍名称',j='成员',sep='_',suffix='.+').dropna().reset_index()
# 是否队长部分的处理
res['成员'] = res.成员.values + 1
res.loc[res['成员']!=1,'成员'] = 0
res = res.sort_values(['队伍名称','成员'],ascending=False).reset_index()
res = res.drop(['level_0','index'],1)
res.rename(columns={'成员':'是否队长'})
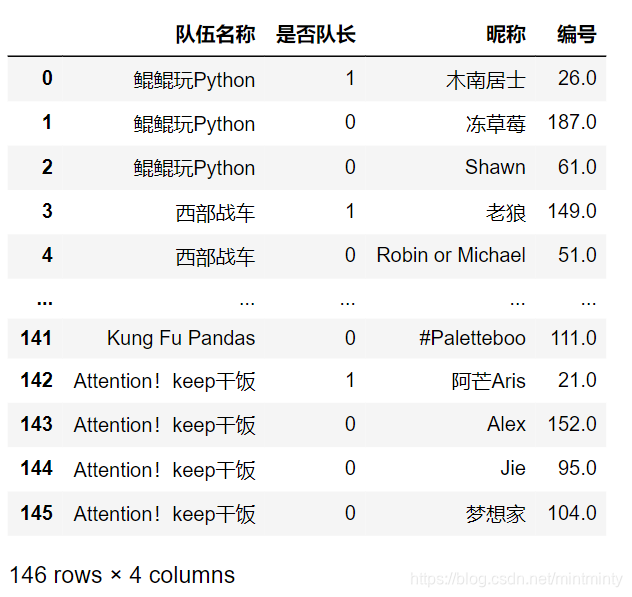
终于做完了…步履维艰
任务三 美国大选投票情况

第一题
哈哈哈哈哈哈这题坑可太多了,不知道是设置的坑,还是我自己给自己挖的… 掉坑填坑过程很揪头发,解决了之后就非常想记录下来。
坑1
- 第一问感觉很简明嘛,就根据
countymerge一个,再判断是不是符合条件就好啦。于是我开心分割字符串,痛快抛弃state字段(要你也没用,干脆删掉) - 好 得到处理完的两个表,开始
merge一切都是这样顺利我真棒!做到这里突然发现,left merge之后怎么行还变多了??? - 推测可能是右表出现了重复值,果不其然 比如
yuma county就有两个,Arizona 和 Colorado 各一个… - 好吧,
state我需要你~~ 需要重新处理下表格
坑2 这是一个花了比较长时间的坑 /(ㄒoㄒ)/~~
total_votes.merge(county_population,on=['county','state'],how='left')结果中的Population全为nan- ???为啥
- 百度说可能是两个表的
key类型不一致,好的 查看info()发现都是object,不是这个问题昂 - 中间省略曲折过程#%…&%%#@#%
- 问题居然出在字符串分割步骤
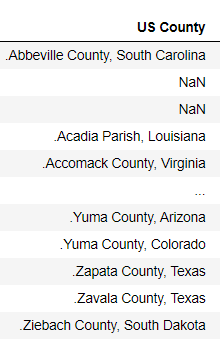
看上去人畜无害
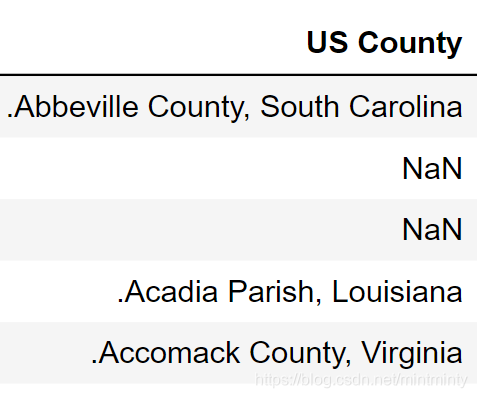
逗号后有空格?

逗号后有空格!!
这个逗号后面有个小空格…我没注意
county_population['US County'].str.split(',',expand=True)这样分出来的state前面有个小空格,那两个表的该字段内容就不一样了,于是merge出来是空值。改成county_population[['county','state']]=county_population['US County'].str.split(', ',expand=True)就解决了。是我太马虎了。
county_population = pd.read_csv('./data/test_1/county_population.csv')
president_county_candidate = pd.read_csv('./data/test_1/president_county_candidate.csv')
county_population[['county','state']]=county_population['US County'].str.split(', ',expand=True)
county_population['county'] = county_population['county'].str.replace('.','')
county_population = county_population.drop(['US County'],1)
total_votes = president_county_candidate.groupby(['county','state'])['total_votes'].sum().to_frame()
total_votes = total_votes.reset_index()
res = total_votes.merge(county_population,on=['county','state'],how='left')
res = res.fillna(0)
res[res['total_votes']>(res['Population']/2)].count()
>>> 3033
第二题
president_county_candidate = pd.read_csv('./data/test_1/president_county_candidate.csv')
# 长表变宽表
president_county_candidate.pivot(index='state',columns='candidate',values='total_votes')
# 阿忘记了,有重复值,要有个sum的操作,需要用pivot_table
res = president_county_candidate.pivot_table(index='state',columns='candidate',values='total_votes',aggfunc='sum')
res = res.fillna(0)
# 符合题意的columns顺序
columns_name = res.sum(0).sort_values(ascending=False).index.tolist()
# 表的变形
result = res.reindex(index=res.index, columns=columns_name)
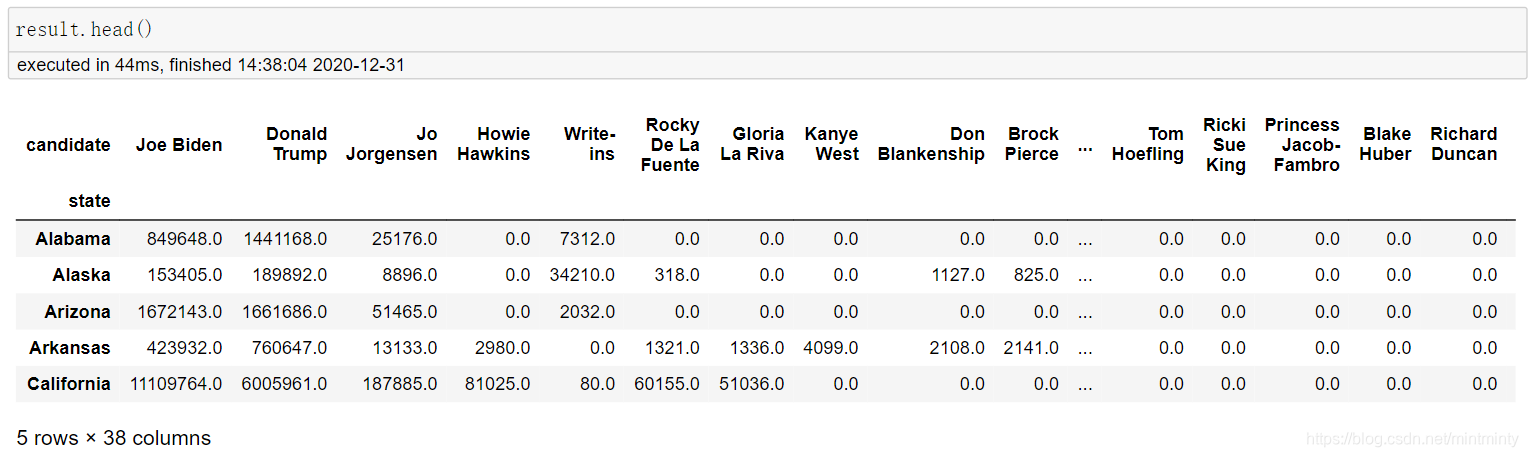
第三题
得票率 = 该候选人得票数 / 该县全部票数 * 100%
president_county_candidate = pd.read_csv('./data/test_1/president_county_candidate.csv')
president_county_candidate['得票率'] = president_county_candidate.groupby(['state','county'])['total_votes'].apply(lambda x: x/x.sum())
president_county_candidate.sort_values('state')
# 拜登在该县的得票率减去川普在该县的得票率为该县的BT指标
res = president_county_candidate.pivot(index=['state','county'],columns='candidate',values='得票率')
res['BT'] = res['Joe Biden']-res['Donald Trump']
res = res.reset_index()
res = res.groupby(['state'])['BT'].apply(lambda x:x.median()>0).to_frame()
res[res.BT==True].index
>>>
Index(['California', 'Connecticut', 'Delaware', 'District of Columbia',
'Hawaii', 'Massachusetts', 'New Jersey', 'Rhode Island', 'Vermont'],
dtype='object', name='state')

















 288
288




 到【灌水乐园】发言
到【灌水乐园】发言







