




最近因为工作关系一直没时间来关注大模型本地化这一块,QWEN3-CODER:30b在网络上发布已经有一段时间了,今天被推送了一条消息 ,看介绍貌似比较强悍,趁着这个酷暑下午正好有咖啡空调和时间,那么就来测试一下吧。

首先需要一个OLLAMA (看个人喜欢吧),关于如何部署OLLAMA ,网上教程比较多,不熟悉的可自行搜索。基本上,玩这个需要一台服务器(笔记本其实也可以) 、一块GPU 、然后一个比较大的硬盘(需要装很多模型用)。
我的OLLAMA 是通过容器(DOCKER)部署的,对外映射了端口11434 ,因为是局域网,没有映射到外网,所以没有被盗用的风险。之前传出OLLAMA漏洞,是因为很多公网上的服务器,端口可以被直接访问,所以存在风险,这一点需要部署公网的注意了。
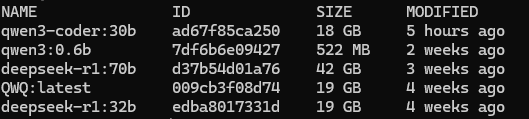
这是进入容器后的状画面,可以看到OLLAMA上装了几个模型,基本上,24G内存的GPU就能跑了。跑70B也比较顺畅。
因为这个是一个写代码的模型,所以强项是编程,不过既然玩了,就测试一下其他的功能先:

这个测试确实非常一般。。。
看一下基本参数吧
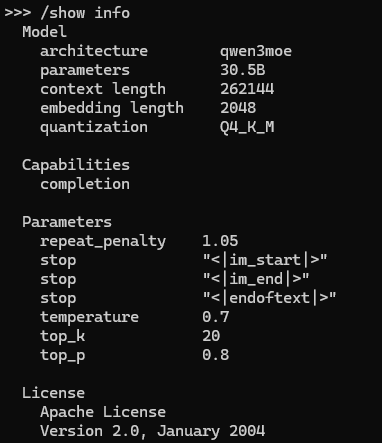
qwen3-coder 30B 模型参数显示,它的架构为 qwen3moe,拥有 30.5B 参数,上下文长度为 2048,量化级别为 Q4_K_M,具有补全能力。
参数设置包括 repeat_penalty 1.05、temperature 0.7、top_k 20 和 top_p 0.8,停止词为 "[im_start]""、"[im_end]" 和 "[endoftext]",采用 Apache License 2.0(2004年1月)。
粗略评价这个配置:这个模型参数配置合理,30.5B 参数量使其在编码任务中具有较强性能,2048的上下文长度适合处理中等复杂度的代码补全需求。Q4_K_M 量化降低了资源需求,同时保留了较高精度。
下面正式测试一下代码能力吧:
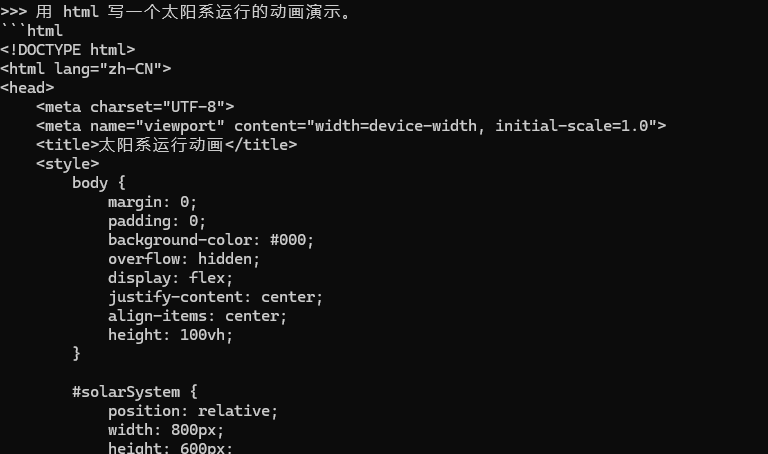
输出的速度可以说是秒出,很快。!
看下结果:
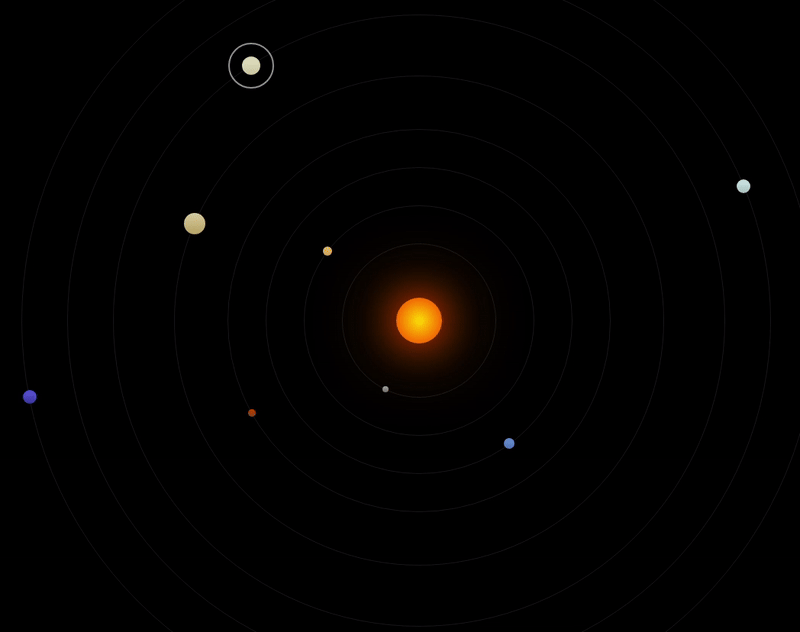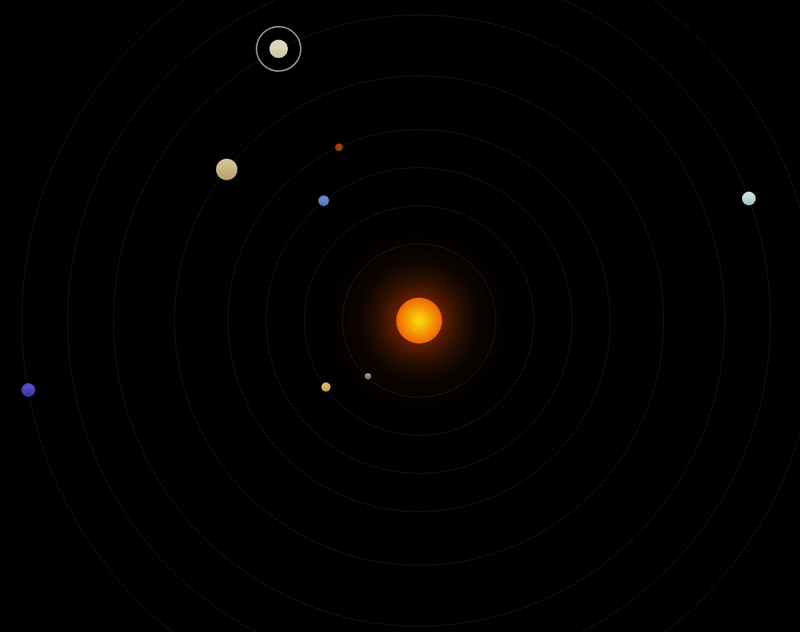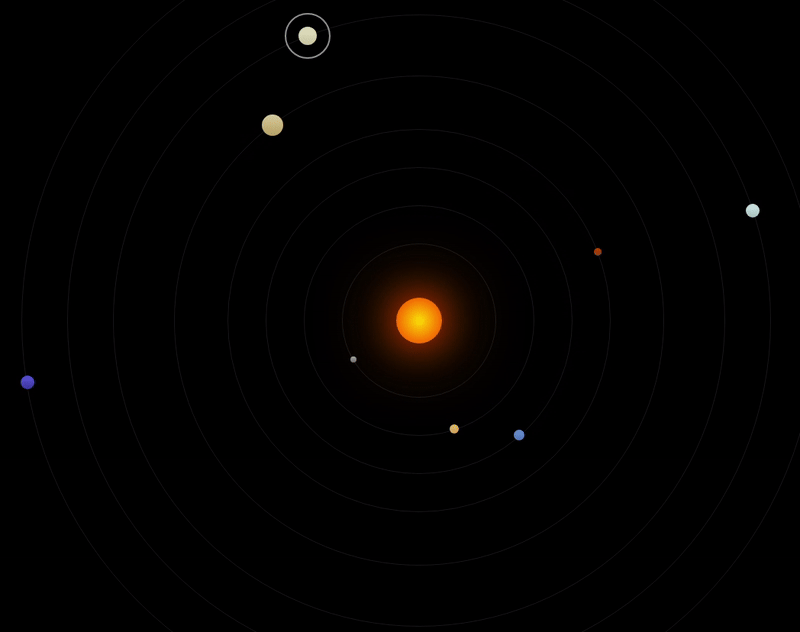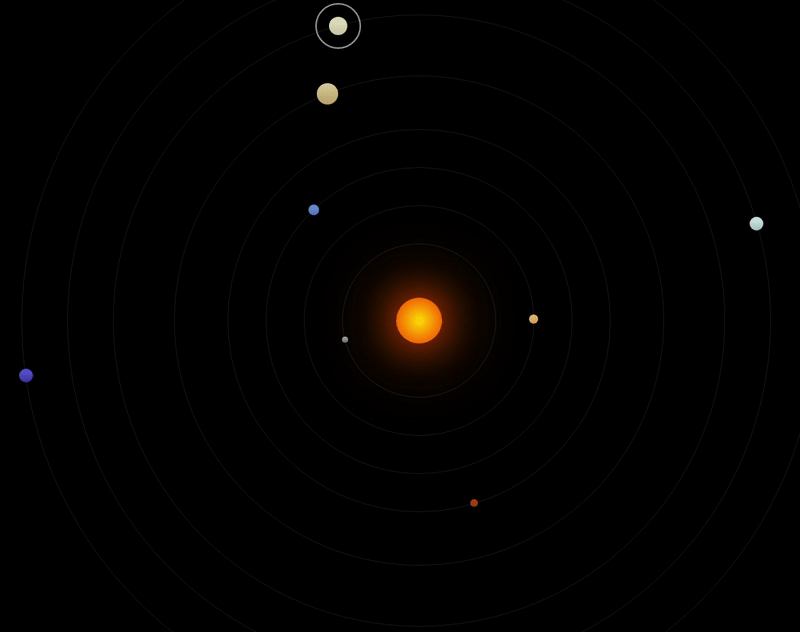 这个画面看上去基本的运行逻辑都有了,但是感觉外围的行星运行速度好像不对啊!
这个画面看上去基本的运行逻辑都有了,但是感觉外围的行星运行速度好像不对啊!
之前我让claude也出过同样的代码,用的同样的提示词,看下效果:
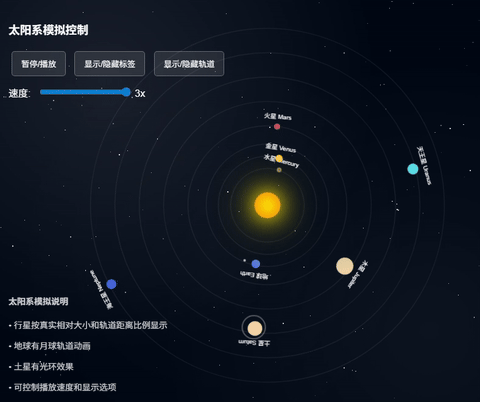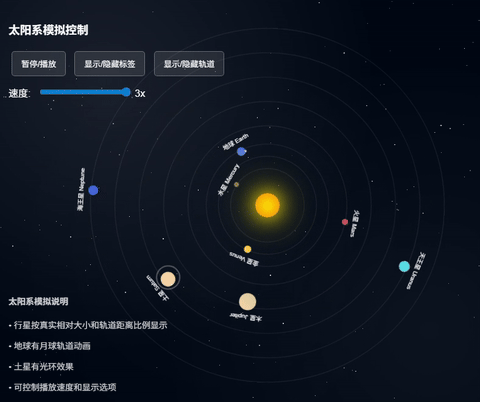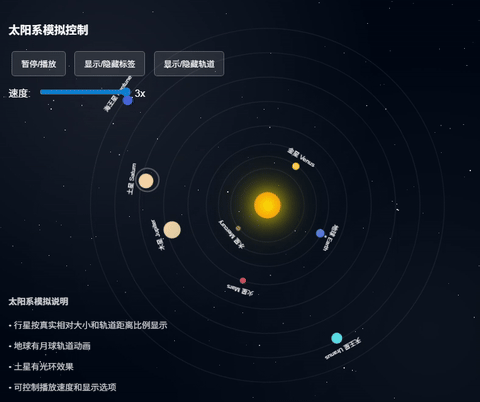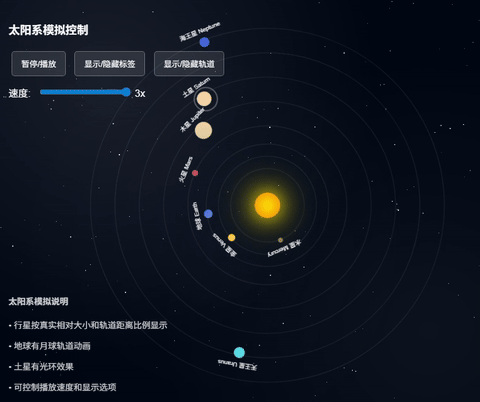
上面这个claude出的效果更真实,考虑更周到。
后面又写了一个web来调用这个QWEN3-CODER:30b,效果还算理想。
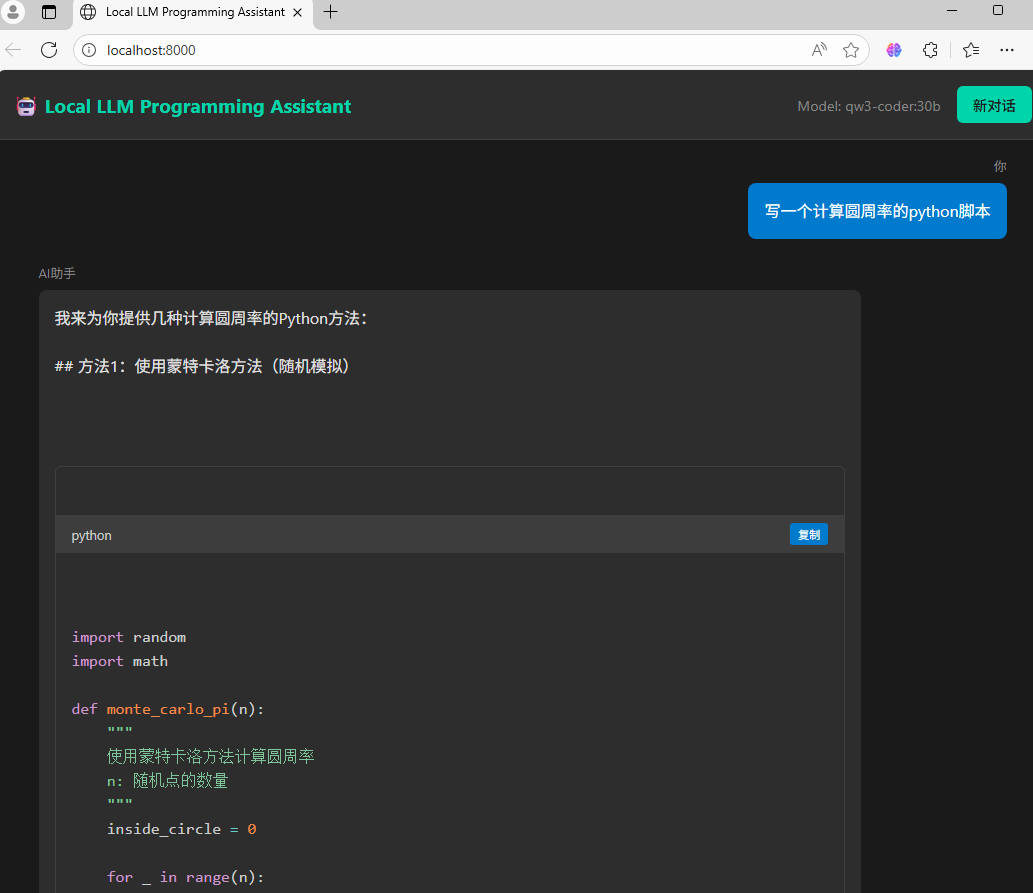
这次还出了不同的方案,(4种实现方案+1种综合方案)不错!
总结:
如果有些公司,需要内部代码编写 不能上外网,可以试一下这个模型,代码能力还是不弱的。


















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









