




前言
本文为学习官方文档Graph RAG Cookbook — CAMEL 0.2.47 documentation的学习记录。
配置Neo4j图数据库
第一步先配置 Neo4j 图数据库。
在浏览器中导航到 Neo4j Aura 控制台。
选择新建实例。
选择创建免费实例。
复制并保存实例的用户名和生成的密码,或者将凭据下载为 .txt 文件。
勾选确认复选框,然后选择继续。
每个账户只能创建一个 AuraDB 免费实例。
免费实例限制为 200,000 个节点和 400,000 个关系。
地址:https://neo4j.com/docs/aura/classic/auradb/getting-started/create-database/
免费额度已经够我们学习使用的了。
什么是知识图谱数据库?为什么是 Neo4j?
想象一下,我们生活中的信息并不是孤立的。一个人“居住在”一个城市,一个公司“开发了”一个产品,一篇文章“讨论了”一个主题。这些信息之间充满了“关系”。传统的数据库(比如表格形式的关系型数据库)虽然能存储大量数据,但在表达和查询这些复杂的“关系”时,可能会变得非常复杂和低效。
知识图谱数据库应运而生,它就像一个巨大的“概念关系网”。它以图形(Graph)的形式来存储数据,主要由两部分组成:
- 节点 (Nodes): 代表现实世界中的“事物”或“概念”,比如一个人、一个地点、一个组织、一个事件、一个产品等等。可以想象成社交网络里的“人”。
- 边 (Relationships): 代表节点之间的“关系”或“联系”。比如“居住在”、“属于”、“开发了”、“写了”、“讨论了”等等。可以想象成社交网络里的“朋友关系”或“关注关系”。每条边都有方向和类型。
除了节点和边,它们还可以拥有属性 (Properties),用来存储关于节点或边的额外信息。比如,一个“人”节点可以有“姓名”、“年龄”属性;一条“居住在”边可以有“开始日期”属性。节点还可以有标签 (Labels),用来分类节点的类型(例如:Person, Organization, Product)。

上图:一个简单的知识图谱示例,展示了节点、标签和关系。
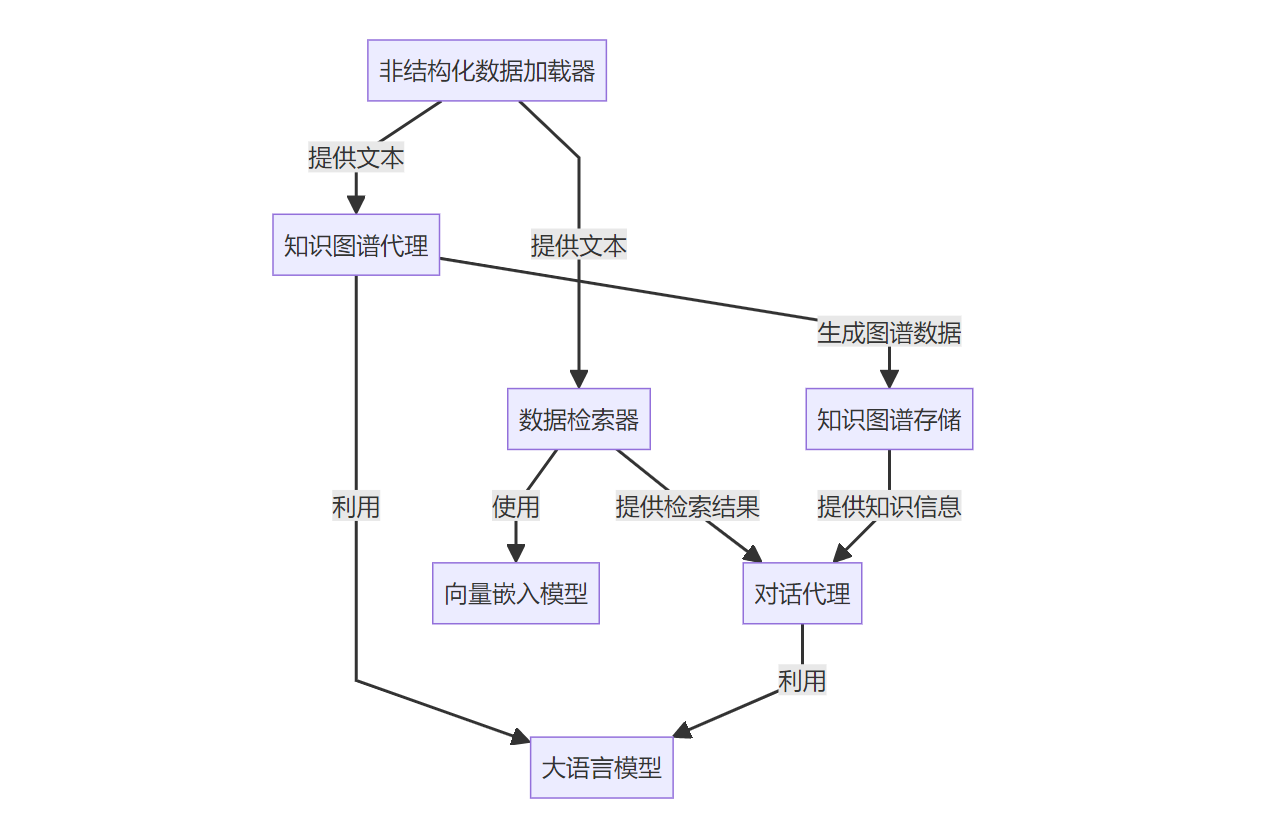
Neo4j 是一种流行的、高性能的图数据库,专门用于存储和处理知识图谱。它使用一种称为 Cypher 的强大图查询语言,可以非常直观和高效地查询节点和它们之间的关系。
在 本文中,我们将 Neo4j 用作我们的知识图谱存储层。它存放着由知识图谱代理从各种来源(比如文档、网页)中提取出来的结构化数据(节点和边)。这样存储的好处是:
- 关系清晰: 直接以图的形式存储,数据的关系一目了然。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









