




前言
上一篇文章介绍了使用SemanticKernel/C#的RAG简易实践,在上篇文章中我使用的是兼容OpenAI格式的在线API,但实际上会有很多本地离线的场景。今天跟大家介绍一下在SemanticKernel/C#中如何使用Ollama中的对话模型与嵌入模型用于本地离线场景。
开始实践
本文使用的对话模型是gemma2:2b,嵌入模型是all-minilm:latest,可以先在Ollama中下载好。
2024年2月8号,Ollama中的兼容了OpenAI Chat Completions API,具体见https://ollama.com/blog/openai-compatibility。
因此在SemanticKernel/C#中使用Ollama中的对话模型就比较简单了。
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(modelId: "gemma2:2b", apiKey: null, endpoint: new Uri("http://localhost:11434")).Build();
这样构建kernel即可。
简单尝试一下效果:
public async Task<string> Praise()
{
var skPrompt = """
你是一个夸人的专家,回复一句话夸人。
你的回复应该是一句话,不要太长,也不要太短。
""";
var result = await _kernel.InvokePromptAsync(skPrompt);
var str = result.ToString();
return str;
}

就这样设置就成功在SemanticKernel中使用Ollama的对话模型了。
现在来看看嵌入模型,由于Ollama并没有兼容OpenAI的格式,所以直接用是不行的。
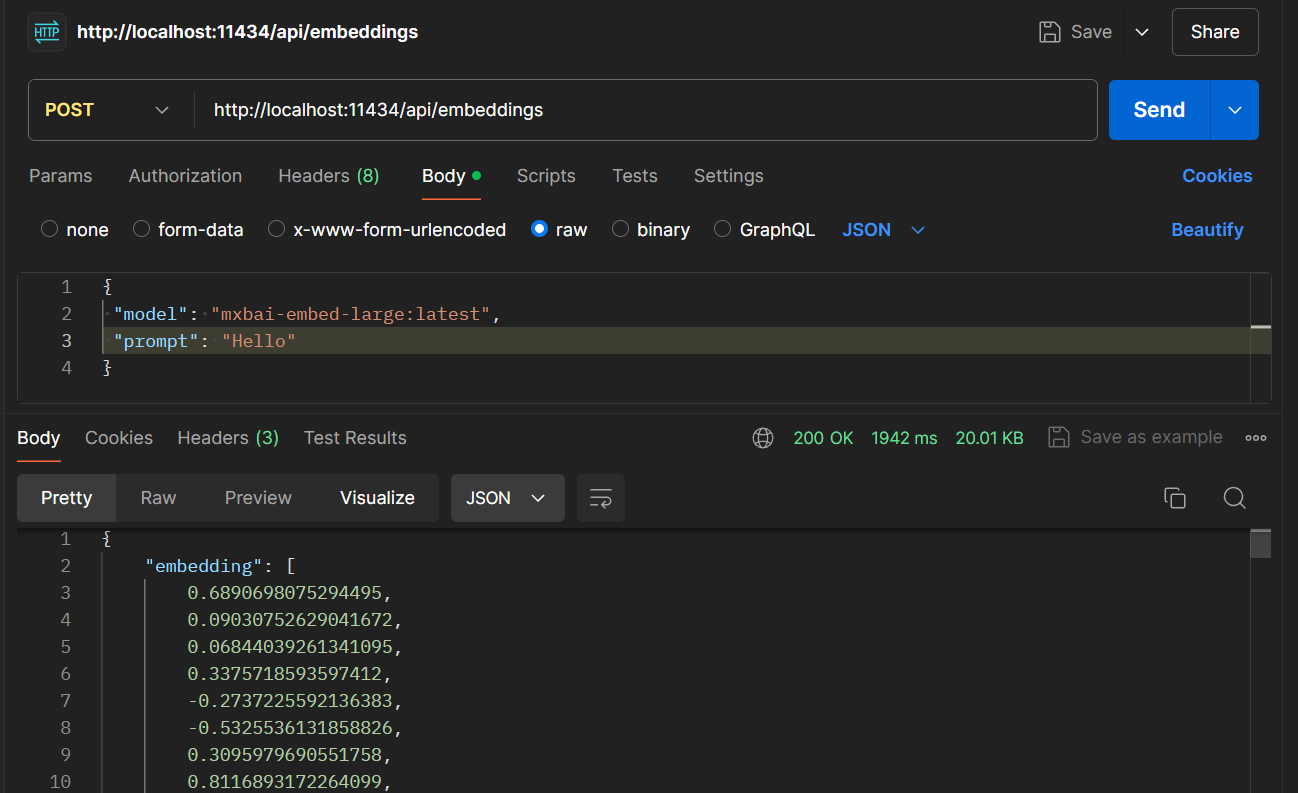
Ollama的格式是这样的:
OpenAI的请求格式是这样的:
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









