




 该博客介绍了利用图像道路标注和车辆分割映射到点云上的方法,通过Unet类似网络在前视图和俯视图进行分割。数据处理中,使用MultiNet进行地面分割,MaskRCNN处理车辆,然后在两种视图上进行映射。模型设计包括添加dropout和pooling,以应对3D数据的噪声。为解决类别不平衡问题,采用了类别比例的开方作为损失权重。实验表明,这种方法在性能和速度上都有所表现。关键词涉及点云分割、图像映射和深度学习应用。
该博客介绍了利用图像道路标注和车辆分割映射到点云上的方法,通过Unet类似网络在前视图和俯视图进行分割。数据处理中,使用MultiNet进行地面分割,MaskRCNN处理车辆,然后在两种视图上进行映射。模型设计包括添加dropout和pooling,以应对3D数据的噪声。为解决类别不平衡问题,采用了类别比例的开方作为损失权重。实验表明,这种方法在性能和速度上都有所表现。关键词涉及点云分割、图像映射和深度学习应用。
1. 主要思想
通过什么方式,解决了什么问题
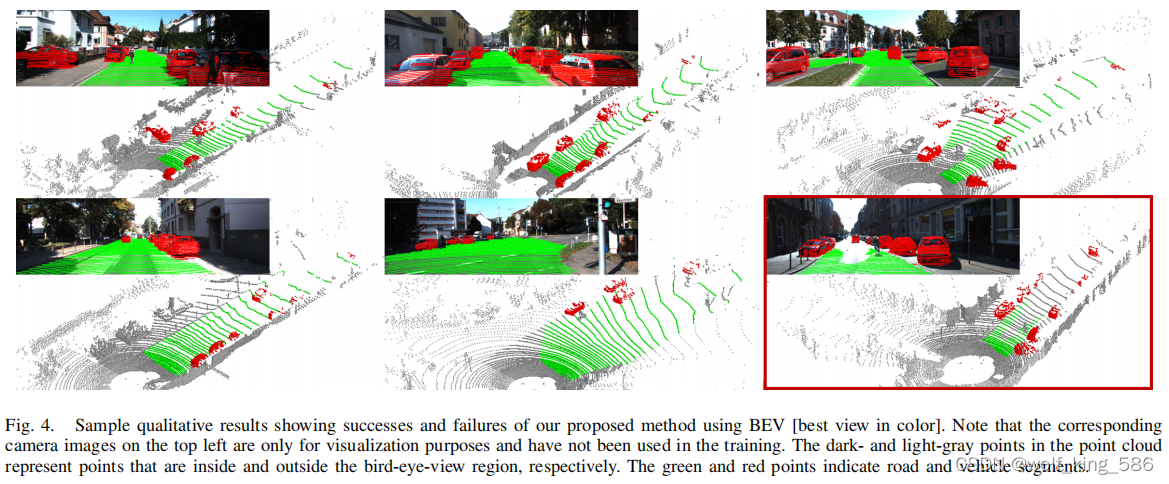
利用图像的道路标注的掩码,映射到点云地面点,然后生成训练集; 然后将点云前视图和俯视图映射,用类似Unet进行分割; 效果如下:
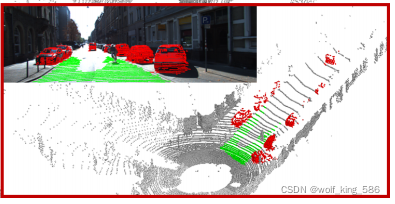
2. 具体方法
说明怎么解决的,具体设计是什么, 有什么启发性思考(作者的创新点)
2.1 数据准备过程
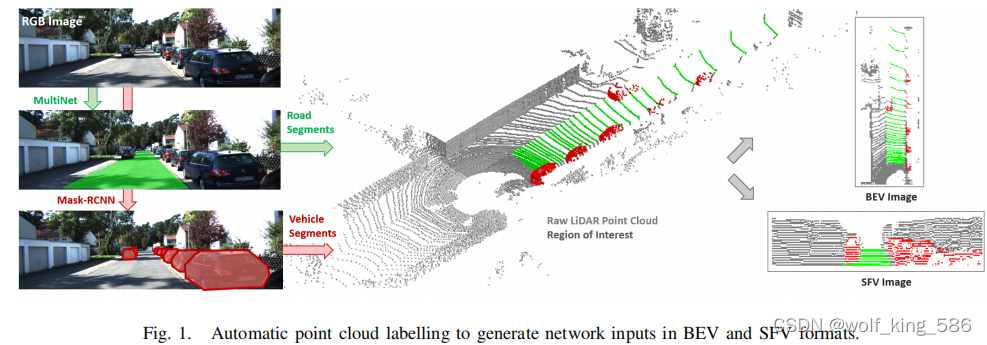
- 如下图所示,整个数据处理过程
- 1)先用MultiNet进行Kitti的地面分割, 为什么用MultiNet,因为作者说只有这个模型是在Kitti道路图像上训练过模型参数, 然后将图像上分割的映射到点云上。
- 2)然后再用MaskRCNN进行车辆的语义分割,然后映射到3D点云上
- 如图中间的效果, 考虑俯视图丢失了高度信息, 然后考虑了两种映射方式,将点云在前视图和俯视图上分别映射,然后用网络去预测学习;
俯视图
- 1)俯视图范围w=[-6, 12], L=[0,50] --> 映射为256x64大小的2D; cell_size(0.2, 0.3)
-
- 每个cell的编码:Similar to the work in 论文[4], in each grid cell, we compute the mean and maximum elevation, average reflectivity (i.e. intensity) value, and number of projected points.
-
- Compared to 论文[4], we avoid using the minimum and standard deviation values of the height as additional features since our experiments showed that there is no significant contribution coming from those channels.
前视图
- 1)和SqueezeSeg一样的投射方式
- 2)前视图一个不好的特性:遮挡,弯曲和变形:Although SFV returns more dense representation compared to BEV, SFV has certain distortion and deformation effects on small objects, e.g. vehicles. It is also more likely that objects in SFV tend to occlude each other. We, therefore, employ BEV representation as the main input to our network.
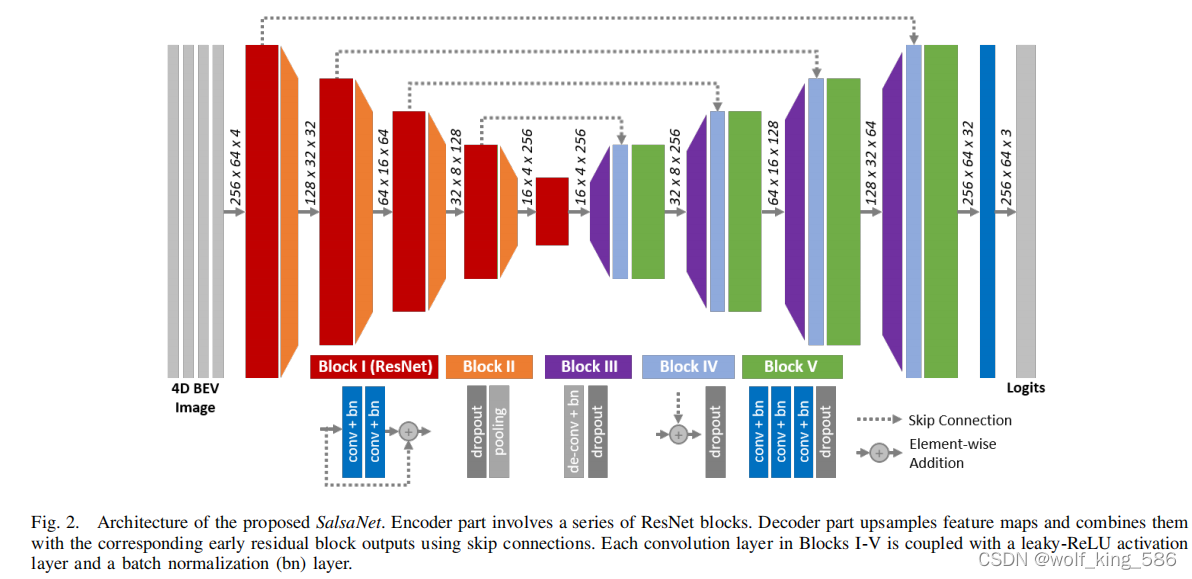
 2.2 模型
2.2 模型 - 在conv_block中的最后一层添加dropout和pooling; dropout对与3D这种噪声大的数据可能有好处;
- 下采样16x;
- dropout放置的位置作者给出了说明,参考的是文献[26],We here emphasize that dropout needs to be placed right after batch normalization. As shown in [26], an early application of dropout can otherwise lead to a shift in the weight distribution and thus minimize the effect of batch normalization during training.
 2.3 类别不平衡问题
2.3 类别不平衡问题 - 用类别比例的开方作为loss weight的比例
 2.4 训练超参数配置
2.4 训练超参数配置 - 数据增强的特殊方式: adding random pixel noise with probaility of 0.5, random rotation [-5,5]
3. 实验支撑
记录一些关键实验的结论分析,具有启发性的实验和结论
- 性能对比(外部)
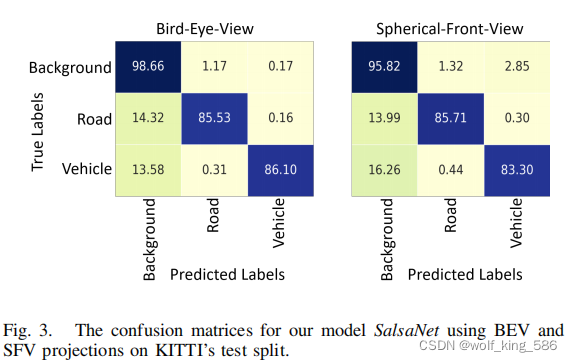
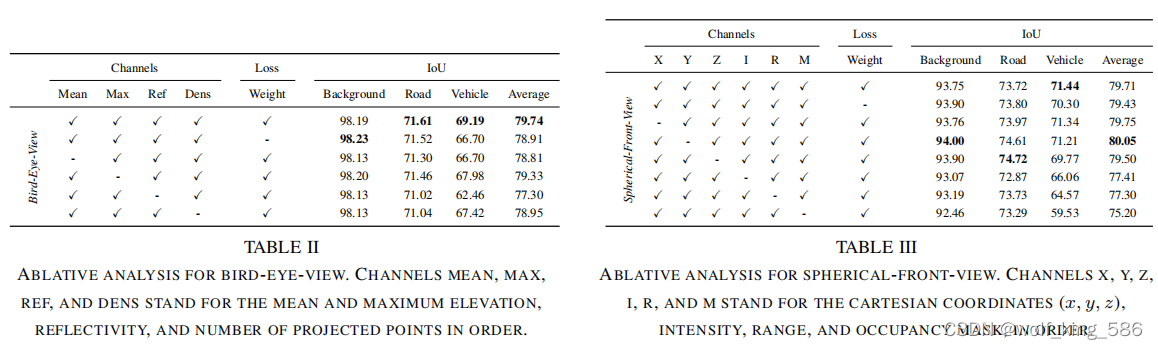
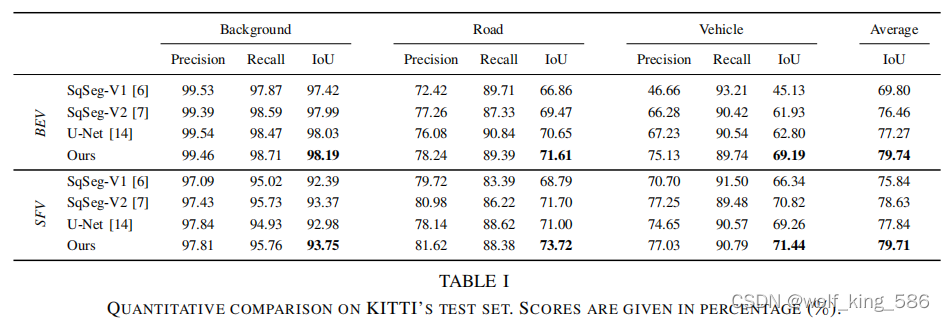 - 俯视图和前视图的性能对比 (内部)
- 俯视图和前视图的性能对比 (内部)
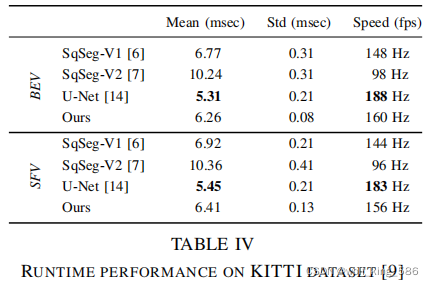
 - 速度对比
- 速度对比
4. 总结启示
针对中心思想和实验结论的总结和扩展思考
扩展思考 : 也就是用自己已有的知识或者自己的“土话”,重新理解paper(费曼学习法的精髓-便于记忆和举一反三的应用)
- 下面引用[11]需要学习一下, 如何半自动标注
- 这个论文的揭露了我们不一定把所有地面标出来,可以只标注freespace
- 这个论文loss weight的设计有一定参考价值
- 性能对比,不仅仅IOU, precision和recall的性能对比
5. 相关文献
主要的比较贴近的文献,关键性文献

















 1683
1683



 到【灌水乐园】发言
到【灌水乐园】发言








