




堆排序:一种高效的排序算法
在计算机科学中,排序算法是一项重要的基础工具,用于将一组数据按照某种规则重新排列。堆排序是其中一种高效的排序算法,它基于二叉堆数据结构实现。在本文中,我们将介绍堆排序的原理、实现方法以及其时间复杂度分析。
1. 堆的基本概念
在理解堆排序之前,我们首先需要了解堆的基本概念。堆是一种特殊的二叉树,它满足以下两个性质:
- 父节点的值始终大于或等于(最大堆)或小于或等于(最小堆)其子节点的值。
- 堆总是一棵完全二叉树,即除了最底层,其他层的节点都被填满,且最底层的节点尽可能地集中在左侧。
2. 堆排序的原理
堆排序的主要思想是先将待排序的数组构建成一个堆,然后逐步将堆顶元素与堆的最后一个元素交换,并重新调整堆,使其满足堆的性质,最终得到有序序列。堆排序包括以下步骤:
- 构建堆:从待排序的数组中构建一个堆,通常使用的是最大堆。
- 调整堆:将堆顶元素与堆的最后一个元素交换,并重新调整堆,使其满足堆的性质。
- 重复以上步骤,直到整个数组有序。
这里的调整堆我们使用向下调整。
当我们创建小堆的时候我们会得到最小值,然后我们将最小值与最后一个数据交换,并将传入向下调整的堆元素个数-1,这样我们就可以保存好最大值;然后将交换的值向下调整,这样我们就可以找到次大值,并再次放到最后。然后n--,以此类推。
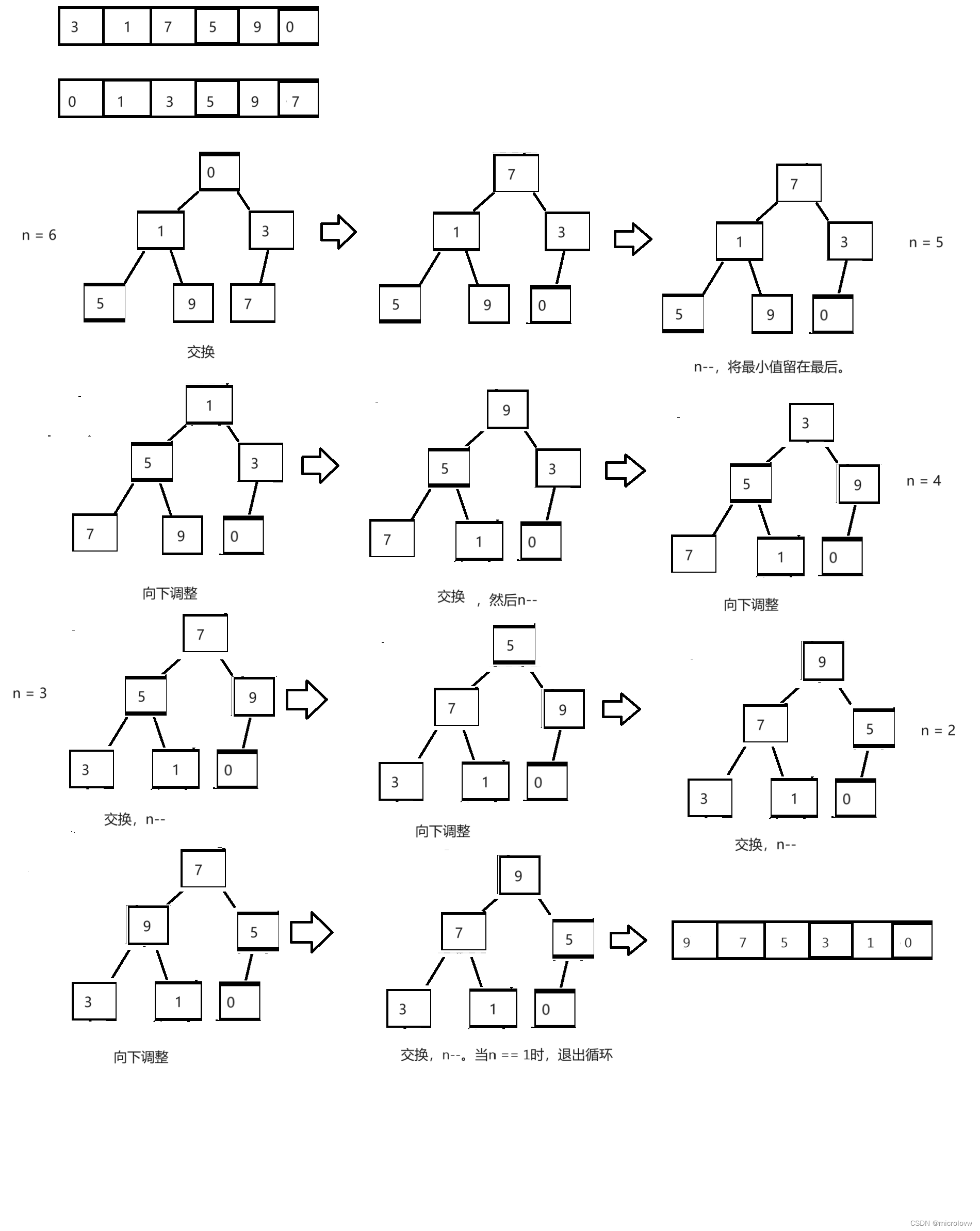
由于我们堆排序并不需要使用完全的堆,所以我们只需要写几个函数几个。
大家按照以下代码,然后按照上面简图一步一步推,就可以掌握堆排序。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









