




 本文介绍布隆过滤器的基本原理与误判机制,并探讨如何通过调整参数降低误判率,同时提出一种改进方案——计数布隆过滤器。
本文介绍布隆过滤器的基本原理与误判机制,并探讨如何通过调整参数降低误判率,同时提出一种改进方案——计数布隆过滤器。
布隆过滤器(Bloom Filter)用来检测在大量数据中是否包含某个特定数据。
一、基本原理
1、存储过程
-
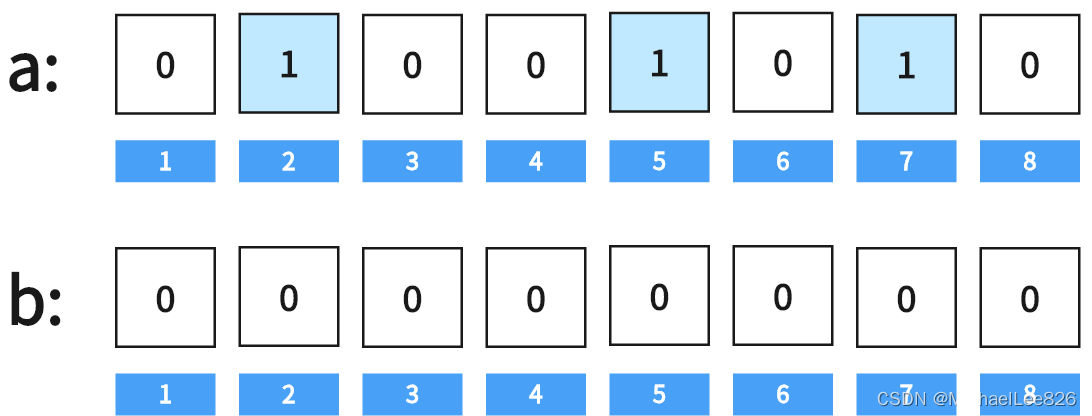
将长度为m的位数组a的所有位全部置0;

-
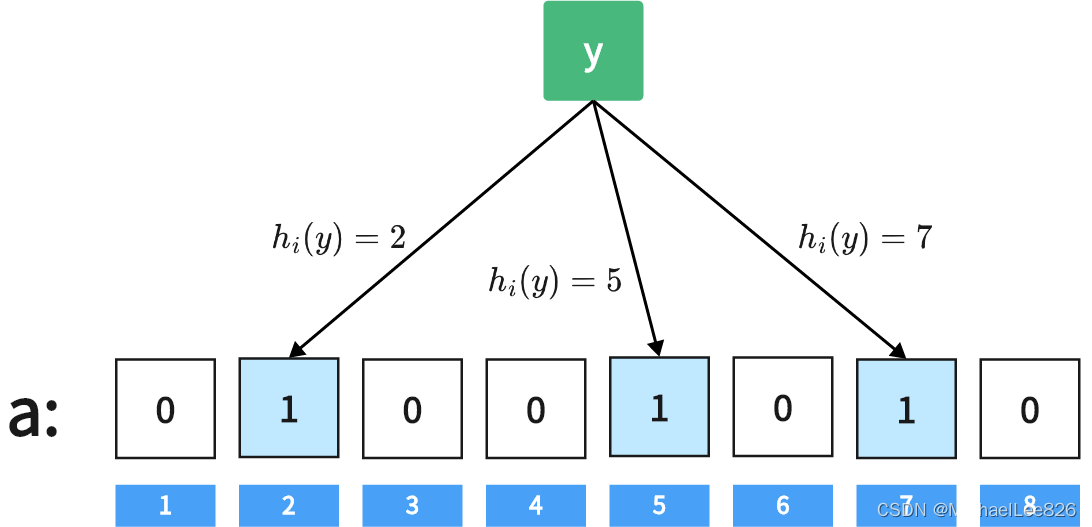
用k个相互独立的**哈希函数h()**对要存入的数据y进行计算;
h1(y)、h2(y)、h3(y)……hk(y) -
如果hi(y) = x,其中1≤i≤k,1≤x≤m,则将位数组a中第x位置1。
2、查找过程
-
生成一个元素全为0的位数组b,其大小与a相同;
-
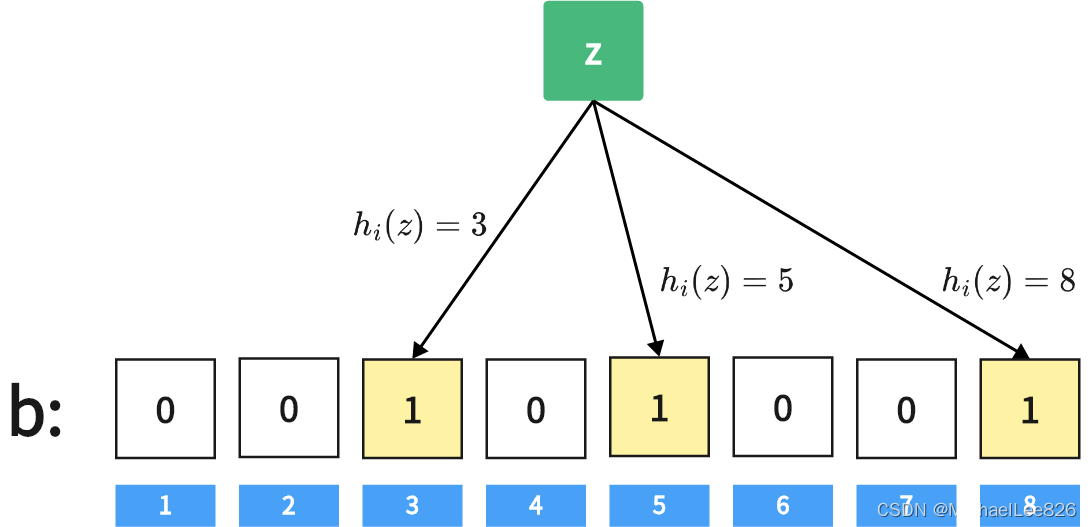
对当要查找某个数据z时,用相同的k个哈希函数对z进行计算,并在位数组b中相应的地方标记为1;
-
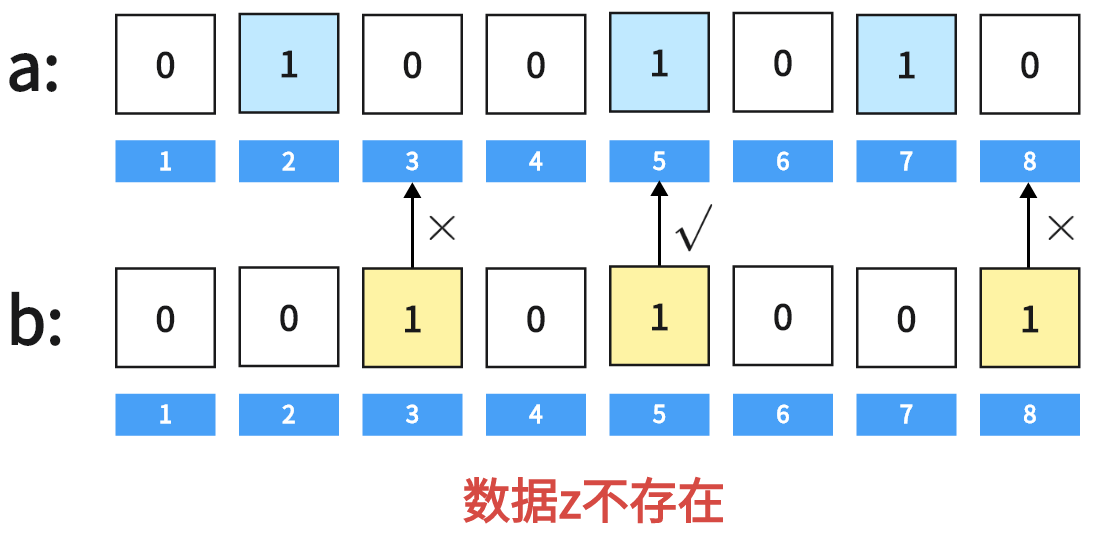
如果b中为1的元素,在a中也为1,则认为找到数据z,否则认为数据z不存在。
二、误判
例子:
元素A使数组a中第1、3、5位置1,元素B使数组a中第5、7、9位置1,现在要查找元素C。
经过三个哈希函数计算后,元素C使数组b中第1、5、9位置1。
比较数组a和数组b后发现,第1、5、9位都是1,因此得出错误结论:元素C在集合中。
Bloom Filter会发生误判,但不会发生漏判。即如果某元素不在集合中,可能判断为在;但如果某元素在集合中,则一定会做出正确判断。
三、参数确定
数组大小m、集合大小n、哈希函数个数k与误判率p的关系:
p=(1−e−kn/m)kp=(1-e^{-kn/m})^kp=(1−e−kn/m)k
最优哈希函数个数k为:
k=mnln2k=\frac mn ln2k=nmln2
影响内存大小的m:
m=−nlnp(ln2)2m=-\frac {nlnp}{(ln2)^2}m=−(ln2)2nlnp
四、改进
布隆过滤器只能用于增加元素并查询的情况,而无法删除其中的元素。
改进的方法称为计数布隆过滤器(Counting Bloom Filter),即位数组中,每一“位”用多个比特位来表示。当增加元素时,将相应的“位”加1,删除元素时,将相应的“位”减1。

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









