




目录
扩展——免费教程链接
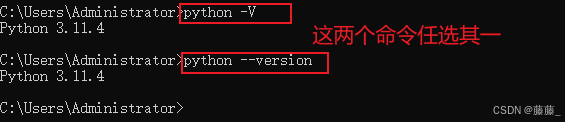
扩展——cmd查看python版本
三种波浪线
红色:代码错误,必须处理掉,代码才能执行。
灰色:基本所有的灰色波浪线都是PEP8造成,不会影响代码的正常执行。
(PEP8:python代码的书写规范,可以代码书写完成后使用 ctrl+alt+l 来自动格式化代码。)
绿色:认为书写的内容不是一个单词时出现,不影响代码的正常执行。
注释
# 单行注释(#号,可以使用 “ctrl+/” 快速给选中内容添加或取消注释)
'''
多行注释(三对单引号)
'''
"""
多行注释(三对双引号)
"""
变量
变量的定义
'''
变量名 = 数据值
变量名1,变量名2,变量名3 = 数据值
变量名1,变量名2,变量名3 = 数据值1,数据值2,数据值3
'''
a = "runoob" # 定义变量a 赋值为"runoob"
a = b = c = 1 # 定义变量a,b,c 都赋值为1
a, b, c = 1, 2, "runoob" # 定义变量a,b,c 分别赋值为1,2,"runoob"
变量名的命名规范
- 只能含字⺟、数字、下划线, 并且不能以数字开头
- 不能使⽤ Python 中的关键字作为变量名
- 区分⼤⼩写
建议的命名方式:
1.驼峰命名法
大驼峰:每个单词的首字母都大写,如MyName
小驼峰:第一个单词首字母小写,其他单词首字母都大写,如myName
2.下划线连接法
my_name
3.见名知意
局部变量和全局变量
局部变量:在函数体中定义的变量
1.局部变量只能在当前函数内部使⽤
2.在不同函数中,可以定义名字相同的局部变量, 两者之间没有影响
全局变量:在函数外部定义的变量
1.可以在任何函数中读取全局变量的值
2.如何函数中存在和全局变量名字相同的局部变量, 那么在函数中使⽤的是局部变量
3.若在函数内部想要修改全局变量的值, 需要添加global 关键字, 声明为全局变量
数据类型
常见的有以下几种
整型(int) :整数
浮点型(float) :⼩数
布尔类型(bool) :只有两个值,真(True,1)、假(False、0)
复数类型(complex) :3 + 4j或者complex(3,4) ,一般不会⽤
字符串(str) :使⽤引号(单引号、双引号、三引号)引起来的就是字符串
列表(list) :[1, 2, 3, 4]
元组(tuple) :(1, 2, 3, 4)
字典(dict) :{‘name’: ‘⼩明’,‘age’: 18}
集合(set):{1, 2, 3, 4}
获取变量数据类型
'''
type(变量)
'''
age = 18
print(type(age)) # <class 'int'>
数据类型转换
'''
变量 = 想要转化为的类型(原数据)
注意:
1.类型转换是不会改变原来数据的类型,是生成新类型
2.类型不是想怎么转就怎么转,只能有下面的几种转换
int():【float】【整数类型的字符串】——>int
float():【int】【数字类型的字符串(包括整数类型和小数类型)】——>float
str():【任意类型】——>str
'''
age = '18'
age1 = int(age)
print(type(age)) # <class 'str'>
print(type(age1)) # <class 'int'>
输入
获取用户键盘输入的内容
'''
变量 = input('提示语')
注意:
1.代码从上到下执行,遇到input函数时会暂停执行等待用户输入
2.回车代表输入结束
3.输入的内容会保存给变量,并且数据类型一定是str
'''
result = input('请输⼊内容:')
print(type(result), result) # 若输入的为:小明,则打印结果为:<class 'str'> 小明
输出
普通输出:
'''
print(内容1,内容2,...,sep='',end='')
注意:
1.sep表示分隔符,一般不写,默认' '(空格)
2.end表示结尾符,一般不写,默认'\n'(换行)
'''
name = '小明'
age = 18
print(name,age) # 小明 18
print(name,age,sep=',',end='。') # 小明,18。
格式化输出:
***法一:%格式化输出占位符号***
'''
print('XXX%dXXX%fXXX%sXXX...' % (digit,float,string))
注意:
1.%前表示要输出的字符串,在需要使用变量的地方用占位符号占位;%后是变量,将会用变量对应填充占位的地方
%d:填充整型数据 digit(特别的:%0nd。n表示整数一共占几位,在前方补0)
%f:填充浮点型数据 float(特别的:%.nf。n为保留小数的位数,默认6位)
%s:填充字符串数据 string (%s可以填充任意类型的数据)
2.若%后只有一个变量,那不必用括号
3.若字符串需要展示%,需要书写为%%
4.若字符串需要换行,使用\n
'''
name = '⼩明'
age = 18
height = 1.71
num = 90
print('我的名字是 %s, 年龄是 %d, 身⾼是 %f m' % (name, age, height)) # 我的名字是 小明, 年龄是 18, 身⾼是 1.710000 m
print('我的年龄是 %06d' % age) # 我的年龄是 000018
print('我的身⾼是 %.1f m' % height) # 我的身⾼是 1.7 m
print('某次考试及格率为 %d%%' % num) # 某次考试及格率为 90%
***(常用)法二:F-string***
'''
print(f'XXX{变量1}XXX{变量2}...')
注意:
1.想要使⽤的话,Python 的版本 >= 3.6
2.需要在字符串的前边加上 f 或者 F
'''
name = '⼩明'
age = 18
height = 1.71
stu_num = 1
num = 90
print(f'我的名字是 {name}, 年龄是 {age}, 身⾼是{height} m, 学号{stu_num}, 本次考试的及格率为{num}%')
# 我的名字是 ⼩明, 年龄是 18, 身⾼是1.71 m, 学号1, 本次考试的及格率为90%
print(f'我的名字是 {name}, 年龄是 {age}, 身⾼是{height:.3f} m, 学号 {stu_num:06d}, 本次考试的及格率为 {num}%')
# 我的名字是 ⼩明, 年龄是 18, 身⾼是1.710 m, 学号 000001, 本次考试的及格率为 90%
***法三:字符串.format()***
'''
'XXX{}XXX{}...'.format(变量1,变量2,...)
'''
name = '小明'
age = 18
height = 1.71
stu_num = 1
num = 90
print('我的名字是 {}, 年龄是 {}, 身高是 {} m, 学号 {}, 本次考试的及格率为 {}%'.format(name,age, height, stu_num, num))
# 我的名字是 小明, 年龄是 18, 身高是 1.71 m, 学号 1, 本次考试的及格率为 90%
print('我的名字是 {}, 年龄是 {}, 身高是 {:.3f} m, 学号 {:06d}, 本次考试的及格率为{}%'.format(name, age, height, stu_num, num))
# 我的名字是 小明, 年龄是 18, 身高是 1.710 m, 学号 000001, 本次考试的及格率为90%
扩展——快捷键

运算符
算数运算符

比较运算符
大于 >
小于 <
大于等于 >=
小于等于 <=
等于 ==
不等于 !=
上面得到的结果全部都是bool类型
逻辑运算符
and:逻辑与,一假全假
or:逻辑或,一真全真
not:逻辑非,取反
赋值运算符
=
复合赋值运算符(将算术运算符和赋值运算符结合):a+=b —> a=a+b
+=
-=
*=
/=
//=
%=
成员运算符

身份运算符

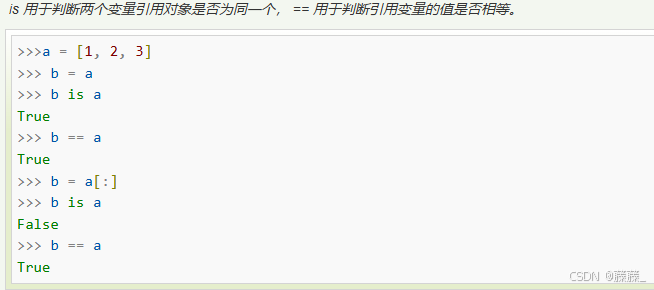
注意!区分is和==
判断
'''
if 判断条件1:
判断条件1为True时执行的代码
elif 判断条件2:
判断条件2为True时执行的代码
else:
以上条件都不成立,执行的代码
注意:
1.elif可以有很多个
2.只有if的条件不成立才会去判断elif
3.if/elif/else里可以嵌套多个if,称为if嵌套
'''
# 定义 score 变量记录考试分数
score = int(input('请输入你的分数'))
# 如果分数是大于等于90分应该显示优
if score >= 90:
print('优')
# 如果分数是大于等于80分并且小于90分应该显示良
elif (score >= 80) and score < 90:
print('良')
# 如果分数是大于等于70分并且小于80分应该显示中
elif score >= 70:
print('中')
# 如果分数是大于等于60分并且小于70分应该显示差
elif score >= 60:
print('差')
# 其它分数显示不及格
else:
print('不及格')
循环
while循环
'''
设置循环的初始条件(计数器)
while 判断条件:
需要重复执行的代码
改变循环的初始条件(计数器)
'''
# 输出五次啦啦啦
i = 0
while i < 5:
print('啦啦啦')
i += 1
for循环
'''
for 变量 in 容器:
重复执⾏的代码
注意:
1.容器中有多少个数据,循环会执⾏多少次
2.每次循环,会将容器中数据取出⼀个保存到 in 关键字前边的变量中
'''
# 输出0-4
# range(n):生成[0,n)之间的整数
for i in range(5):
print(i)
# 输出5-10
# range(a,b):生成[a,b)之间的整数
for m in range(5, 11):
print(m)
死循环和无限循环
死循环:一般是由写代码的人不小心造成的 bug, 代码一直不停的运行下去。
无限循环:写代码的人故意让代码无限制的去执行,代码一直不停的运行下去。
(无限循环的使用场景: 在书写循环的时候,不确定循环要执行多少次。一般会在循环中添加一个 if 判断, 当 if 条件成立,使用关键字 break 来终止循环)
break和continue
break:终止循环
continue:跳过本次循环
容器
容器中可以存放多个数据,常见的有以下
字符串
***定义***
'''
方式一:变量名 = 'XXX'
方式二:变量名 = "XXX"
方式三:变量名 = '''XXX'''
方式四:变量名 = """XXX"""
'''
# 使⽤单引号定义
my_str1 = 'hello'
# 使⽤双引号定义
my_str2 = "hello"
# 使⽤三引号定义
my_str3 = """hello"""
my_str4 = '''hello'''
# 字符串本身包含单引号的情况
my_str5 = "I'm ⼩明"
my_str6 = 'I\\\'m ⼩明' # \\ ---> \
my_str7 = 'I\'m ⼩明' # \为转义字符。在前加r表示原生字符串,\就不会被看做转义字符
my_str8 = r'I\'m ⼩明' #I\'m ⼩明
***下标***
'''
字符串[下标]
注意:
1.得到的结果为字符串指定位置的字符
2.下标是从左到右进行编号的,从0开始(python支持负数下标,从右到左进行编号,从-1开始)
'''
str1 = 'abcdefg'
# 打印字符串中最开始位置的字符
print(str1[0]) # a
# 打印最后⼀个位置的数据
print(str1[-1]) # g
# 打印倒数第⼆个位置的字符
print(str1[-2]) # f
***切片***
'''
字符串[start:end:step]
注意:
1.start 是开始位置的下标
2.end 是结束位置的下标(注意,不能取到这个位置的字符)
3.step 是步⻓,默认是 1
'''
str1 = 'abcdefg'
print(str1[0:3:1]) # abc
# 如果步⻓是 1 可以不写, 最后⼀个冒号也不写
print(str1[0:3]) # abc
# 如果开始位置为 0 ,可以不写, 但是冒号必须有
print(str1[:3]) # abc
print(str1[4:7]) # efg
# 别忘了下标支持负数哦
print(str1[-3:7]) # efg
# 如果最后⼀个字符也要取, 可以不写, 但是冒号必须有
print(str1[4:]) # efg
# 如果开始和结束都不写, 获取全部内容, 但是冒号必须有
print(str1[:]) # abcdefg
print(str1[0:7:2]) # aceg
print(str1[::2]) # aceg
# 反转(逆置) 字符串 字符串[::-1],步长为负数只有这一种使用场景
print(str1[::-1]) # gfedcba
***求长len()***
'''
len(字符串)
'''
str1 = 'abcdefg'
num = len(str1)
print(num) # 7
***查找find()***
'''
字符串.find(sub_str, start, end)
注意:
1.sub_str: 要查找的子字符串
2.start: 开始位置,表示从哪个下标位置开始查找, ⼀般不写,默认是0
3.end: 结束位置, 表示查找到哪个下标结束, ⼀般不写,默认是len()
4.返回值:
a.如果找到了,返回子字符串第⼀次出现时的正数下标(sub_str 中第⼀个字符的下标)
b.如果没找到,返回 -1
'''
str1 = "and itcast and itheima and Python"
# 查找第一个and
num = str1.find('and')
print(num) # 0
# 查找第二个and
num1 = str1.find('and', num+1)
print(num1) # 11
# 查找第三个and
num2 = str1.find('and', num1+1)
print(num2) # 23
# 查找第四个and(不存在,返回-1)
num3 = str1.find('and', num2+1)
print(num3) # -1
***替换replace()***
'''
字符串.replace(old_str, new_str, count)
注意:
1.old_str: 被替换的内容
2.new_str: 替换为的内容
3.count: 替换的次数, ⼀般不写,默认是全部替换
4.返回值: 替换之后的完整的字符串,注意原来的字符串没有发⽣改变
'''
str1 = 'good good good study'
# 将 str1 中的 good 改为 GOOD,全部改完
str2 = str1.replace('good', 'GOOD')
print(str2) # GOOD GOOD GOOD study
# 将 str1 中的 good 改为 GOOD,只改两次
str3 = str1.replace('good', 'GOOD', 2)
print(str3) # GOOD GOOD good study
***拆分split()***
'''
字符串.split(sep, maxsplit)
注意:
1.sep:分隔符。表示字符串按照什么进⾏拆分,默认是空⽩字符(空格, 换⾏\n, tab键\t)
2.max_split:分隔次数。⼀般不写, 全部分隔
3.返回值: 将⼀个字符串拆分为多个,存到列表中
4.如果 sep 不写, 想要指定分隔次数,则需要按照如下⽅式使⽤:字符串.split(maxsplit=n) # n 是次数
'''
str1 = "hello world and itcast and itheima and Python"
# 将 str1 按照 and 字符进⾏拆分,全部拆分
result1 = str1.split('and')
print(result1) # ['hello world ', ' itcast ', ' itheima ', ' Python']
# 将 str1 按照 and 字符进⾏拆分, 拆分两次
result2 = str1.split('and', 2)
print(result2) # ['hello world ', ' itcast ', ' itheima and Python']
# 按照空⽩字符进⾏切割,全部拆分
result3 = str1.split()
print(result3) # ['hello', 'world', 'and','itcast', 'and', 'itheima', 'and', 'Python']
# 按照空⽩字符进⾏切割, 拆分⼀次
result4 = str1.split(maxsplit=1)
print(result4) # ['hello', 'world and itcast and itheima and Python']
***连接join()***
'''
连接符.join(列表)
注意:
1.列表中的数据必须都是字符串, 否则会报错
2.括号中的内容主要是列表,但也可以是其他
3.注意字符串还可以用 + 运算符连接在一起,用 * 运算符重复
'''
list1 = ['good', 'good', 'study']
# 将列表中的字符串使⽤空格连起来
str1 = ' '.join(list1)
print(str1) # good good study
# 将列表中的字符串使⽤ and 连起来
str2 = ' and '.join(list1)
print(str2) # good and good and study
str = '123'
# 将字符串输出两次
str3 = str * 2
print(str3) # 123123
# 将两个字符串连接起来
str4 = str + '456' # 123456
print(str4)
***遍历***
'''
for 变量 in 字符串:
print(变量)
'''
my_str = '一二三'
for i in my_str:
print(i)
列表
***定义***
'''
方式一:变量名 = list()
方式二:变量名 = list(容器)
方式三(常用):变量名 = []
方式四(常用):变量名 = [XXX,XXX,...]
'''
# 方式一
list1 = list()
print(type(list1), list1) # <class 'list'> []
# 方式二
list2 = list('hello')
print(type(list2), list2) # <class 'list'> ['h', 'e', 'l', 'l', 'o']
# 方式三
list3 = []
print(type(list3), list3) # <class 'list'> []
# 方式四
list3 = [1,'⼩明',3.14,False]
print(type(list3), list3) # <class 'list'> [1, '⼩明', 3.14, False]
***下标***
'''
列表[下标]
注意:
1.得到的结果为列表指定位置的元素
2.下标是从左到右进行编号的,从0开始(python支持负数下标,从右到左进行编号,从-1开始)
'''
list1 = ['⼩明', 18, 1.71, True]
# 获取第⼀个数据
print(list1[0]) # ⼩明
# 获取最后⼀个数据
print(list1[-1]) # True
***切片***
'''
列表[start:end:step]
注意:
1.start 是开始位置的下标
2.end 是结束位置的下标(注意,不能取到这个位置的元素)
3.step 是步⻓,默认是 1
'''
list1 = ['⼩明', 18, 1.71, True, 15, 16, 17]
print(list1[0:3:1]) # ['⼩明', 18, 1.71]
# 如果步⻓是 1 可以不写, 最后⼀个冒号也不写
print(list1[0:3]) # ['⼩明', 18, 1.71]
# 如果开始位置为 0 ,可以不写, 但是冒号必须有
print(list1[:3]) # ['⼩明', 18, 1.71]
print(list1[4:7]) # [15, 16, 17]
# 别忘了下标支持负数哦
print(list1[-3:7]) # [15, 16, 17]
# 如果最后⼀个元素也要取, 可以不写, 但是冒号必须有
print(list1[4:]) # [15, 16, 17]
# 如果开始和结束都不写, 获取全部内容, 但是冒号必须有
print(list1[:]) # ['⼩明', 18, 1.71, True, 15, 16, 17]
print(list1[0:7:2]) # ['⼩明', 1.71, 15, 17]
print(list1[::2]) # ['⼩明', 1.71, 15, 17]
# 反转(逆置)列表 列表[::-1],步长为负数只有这一种使用场景
print(list1[::-1]) # [17, 16, 15, True, 1.71, 18, '⼩明']
***求长len()***
'''
len(列表)
'''
list1 = ['⼩明', 18, 1.71, True, 15, 16, 17]
num = len(list1)
print(num) # 7
***查找index()***
'''
列表.index(point, start, end)
注意:
1.point: 要查找的数据
2.start: 开始位置,表示从哪个下标位置开始查找, ⼀般不写,默认是0
3.end: 结束位置, 表示查找到哪个下标结束, ⼀般不写,默认是len()
4.返回值:
a.如果找到了,返回数据第⼀次出现时的正数下标
b.如果没找到,代码直接报错
'''
list1 = [1, 3, 5, 7, 2, 3]
# 查找第一个3
num = list1.index(3)
print(num) # 1
# 查找第二个3
num1 = list1.index(3, num+1)
print(num1) # 5
# 查找第三个and
num2 = list1.index(3, num1+1) # 报错ValueError: 3 is not in list
***计数count()***
'''
列表.count(数据) # 统计数据在列表中总共出现了几次
'''
list1 = [1, 3, 5, 7, 2, 3]
num = list1.count(3)
print(num) # 2
***尾部添加数据append()***
'''
列表.append(数据) # 将数据添加到列表的尾部
'''
list1 = ['郭德纲']
list2 = ['孙越', '烧饼']
list1.append('郭麒麟')
print(list1) # ['郭德纲', '郭麒麟']
list1.append(list2)
print(list1) # ['郭德纲', '郭麒麟', ['孙越', '烧饼']]
***指定位置添加数据insert()***
'''
列表.insert(下标,数据) # 将数据添加到下标位置。如果指定的下标位置本来有数据, 原数据会后移
'''
list1 = ['郭德纲', '郭麒麟']
list2 = ['孙越', '烧饼']
list1.insert(1,'岳岳')
print(list1) # ['郭德纲', '岳岳', '郭麒麟']
list1.insert(1,list2)
print(list1) # ['郭德纲', ['孙越', '烧饼'], '岳岳', '郭麒麟']
***合并extend()***
'''
列表1.extend(列表2) # 将列表2中的数据逐个添加到列表1的尾部
'''
list1 = ['郭德纲', '郭麒麟']
list2 = ['孙越', '烧饼']
list1.extend(list2)
print(list1) # ['郭德纲', '郭麒麟', '孙越', '烧饼']
***修改***
'''
列表[下标] = 数据
注意:
1.字符串中的字符是无法使用下标修改的,注意与列表区分
2.如果指定的下标不存在会报错
'''
my_list = [1, 3, 5, 7]
my_list[1] = 22
print(my_list) # [1, 22, 5, 7]
***删除指定位置的数据pop()***
'''
列表.pop(下标)
注意:
1.下标不写,默认删除最后一个数据
2.返回删除的数据
'''
my_list = [1, 3, 5, 7, 9, 2, 4, 6, 8, 0]
# 删除最后一个数据
num1 = my_list.pop()
print('删除的数据为:', num1) # 删除的数据为: 0
print(my_list) # [1, 3, 5, 7, 9, 2, 4, 6, 8]
# 删除下标为1的位置的数据
num2 = my_list.pop(1)
print('删除的数据为:', num2) # 删除的数据为: 3
print(my_list) # [1, 5, 7, 9, 2, 4, 6, 8]
***删除指定数据值的数据remove()***
'''
列表.remove(数据值)
注意:
1.如果数据值不存在,会报错
2.如果数据值有多个,只会删除第一个
3.返回None
'''
my_list = [1, 3, 1, 7, 9]
my_list.remove(7)
print(my_list) # [1, 3, 1, 9]
my_list.remove(1)
print(my_list) # [3, 1, 9]
my_list.remove(10) # 报错ValueError: list.remove(x): x not in list
***清空clear()***
'''
列表.clear()
'''
my_list = [1, 3, 1, 7, 9]
my_list.clear()
print(my_list) # []
***反转(倒置)reverse()***
'''
列表.reverse()
注意:
注意与切片反转[::-1]区分。[::-1]没有修改原列表;reverse()修改了原列表
'''
my_list = [1, 3, 1, 7, 9]
my_list.reverse()
print(my_list) # [9, 7, 1, 3, 1]
***复制copy()***
'''
变量 = 列表.copy()
'''
list1 = [1,2,3]
list2 = list1.copy()
print(list1) # [1,2,3]
***排序sort()***
'''
列表.sort()
注意:
1.默认升序
2.列表.sort(reverse=True)表示降序
'''
list1 = [2,1,3]
list1.sort()
print(list1) # [1, 2, 3]
list1.sort(reverse=True)
print(list1) # [3, 2, 1]
***去重***
'''
方式一:
set(列表) # set是集合,会自动去重
方式二:
遍历原列表中的数据判断在新列表中是否存在。 如果存在,不管;如果不存在,放⼊新的列表中。
注意:
1.方式一不能保证在新列表依然维持原列表的顺序
'''
list1 = [3,1,3,2]
# 方式1
new_list1 = list(set(list1))
print(new_list1) # [1, 2, 3]
# 方式二
new_list2 = []
for i in list1:
if i not in new_list2:
new_list2.append(i)
print(new_list2) # [3, 1, 2]
***遍历***
'''
for 变量 in 列表:
print(变量)
'''
my_list = [1,2,3]
for i in my_list:
print(i)
元组
元组和列表最大的区别:元组中的数据内容不能改变, 列表中的可以改变的。因此元组常应用在函数的传参或者返回值中使⽤, 保证数据不会被修改。
***定义***
'''
方式一:变量名 = tuple()
方式二:变量名 = tuple(容器)
方式三(常用):变量名 = ()
方式四(常用):变量名 = (XXX,XXX,...) # 注意若只有一个数据,必须要带逗号
'''
# 方式一
tuple1 = tuple()
print(type(tuple1), tuple1) # <class 'tuple'> ()
# 方式二
tuple2 = tuple([1, 2, 3])
print(type(tuple2), tuple2) # <class 'tuple'> (1, 2, 3)
tuple3 = tuple('hello')
print(type(tuple3), tuple3) # <class 'tuple'> ('h', 'e', 'l', 'l', 'o')
# 方式三
tuple4 = ()
print(type(tuple4), tuple4) # <class 'tuple'> ()
# 方式四
tuple5 = (1,'⼩明',3.14,False)
print(type(tuple5), tuple5) # <class 'tuple'> (1, '⼩明', 3.14, False)
tuple6 = (1,)
print(type(tuple6), tuple6) # <class 'tuple'> (1,)
***下标***
'''
元组[下标]
注意:
1.得到的结果为元组指定位置的元素
2.下标是从左到右进行编号的,从0开始(python支持负数下标,从右到左进行编号,从-1开始)
'''
tuple1 = ('⼩明', 18, 1.71, True)
# 获取第⼀个数据
print(tuple1[0]) # ⼩明
# 获取最后⼀个数据
print(tuple1[-1]) # True
***切片***
'''
元组[start:end:step]
注意:
1.start 是开始位置的下标
2.end 是结束位置的下标(注意,不能取到这个位置的元素)
3.step 是步⻓,默认是 1
'''
tuple1 = ('⼩明', 18, 1.71, True, 15, 16, 17)
print(tuple1[0:3:1]) # ('⼩明', 18, 1.71)
# 如果步⻓是 1 可以不写, 最后⼀个冒号也不写
print(tuple1[0:3]) # ('⼩明', 18, 1.71)
# 如果开始位置为 0 ,可以不写, 但是冒号必须有
print(tuple1[:3]) # ('⼩明', 18, 1.71)
print(tuple1[4:7]) # (15, 16, 17)
# 别忘了下标支持负数哦
print(tuple1[-3:7]) # (15, 16, 17)
# 如果最后⼀个元素也要取, 可以不写, 但是冒号必须有
print(tuple1[4:]) # (15, 16, 17)
# 如果开始和结束都不写, 获取全部内容, 但是冒号必须有
print(tuple1[:]) # ('⼩明', 18, 1.71, True, 15, 16, 17)
print(tuple1[0:7:2]) # ('⼩明', 1.71, 15, 17)
print(tuple1[::2]) # ('⼩明', 1.71, 15, 17)
# 反转(逆置)元组 元组[::-1],步长为负数只有这一种使用场景
print(tuple1[::-1]) # (17, 16, 15, True, 1.71, 18, '⼩明')
***求长len()***
'''
len(元组)
'''
tuple1 = ('⼩明', 18, 1.71, True, 15, 16, 17)
num = len(tuple1)
print(num) # 7
***查找index()***
'''
元组.index(point, start, end)
注意:
1.point: 要查找的数据
2.start: 开始位置,表示从哪个下标位置开始查找, ⼀般不写,默认是0
3.end: 结束位置, 表示查找到哪个下标结束, ⼀般不写,默认是len()
4.返回值:
a.如果找到了,返回数据第⼀次出现时的正数下标
b.如果没找到,代码直接报错
'''
tuple1 = (1, 3, 5, 7, 2, 3)
# 查找第一个3
num = tuple1.index(3)
print(num) # 1
# 查找第二个3
num1 = tuple1.index(3, num+1)
print(num1) # 5
# 查找第三个and
num2 = tuple1.index(3, num1+1) # 报错ValueError: tuple.index(x): x not in tuple
***计数count()***
'''
元组.count(数据) # 统计数据在元组中总共出现了几次
'''
tuple1 = (1, 3, 5, 7, 2, 3)
num = tuple1.count(3)
print(num) # 2
***遍历***
'''
for 变量 in 元组:
print(变量)
'''
my_tuple = (1,2,3)
for i in my_tuple:
print(i)
字典
由多个键值对构成。键不可重复;键一般是字符串,可以是数字,不可是列表。
***定义***
'''
方式一:变量名 = dict()
方式二(常用):变量名 = {}
方式三(常用):变量名 = {key:value,key:value,...}
'''
# 方式一
dict1 = dict()
print(type(dict1), dict1) # <class 'dict'> {}
# 方式二
dict2 = {}
print(type(dict2), dict2) # <class 'dict'> {}
# 方式三
dict3 = {"name": "⼩明", "age": 18, "height": 1.71, "is_men": True, "like": ["抽烟", "喝酒", "烫头"]}
print(type(dict3), dict3) # <class 'dict'> {'name': '⼩明', 'age': 18, 'height': 1.71, 'is_men': True, 'like': ['抽烟', '喝酒', '烫头']}
***求长len()***
'''
len(字典)
'''
dict1 = {"name": "⼩明", "age": 18, "height": 1.71, "is_men": True, "like": ["抽烟", "喝酒", "烫头"]}
num = len(dict1)
print(num) # 5
***增加/修改***
'''
字典[键] = 值
注意:
1. 如果键不存在,就是添加键值对
2. 如果键已经存在,就是修改键值对的值
'''
my_dict = {"name": "⼩明", "age": 18, "like": ['抽烟', '喝酒', '烫头']}
# 增加
my_dict['sex'] = '男'
print(my_dict) # {'name': '⼩明', 'age': 18, 'like': ['抽烟', '喝酒', '烫头'], 'sex': '男'}
# 修改
my_dict['age'] = 19
print(my_dict) # {'name': '⼩明', 'age': 19, 'like': ['抽烟', '喝酒', '烫头'], 'sex': '男'}
***删除del/pop()***
'''
方式一:del 字典[键]
方式二:字典.pop(键)
'''
my_dict = {'name': '⼩明', 'age': 19, 'like': ['抽烟', '喝酒', '烫头', '学习'], 'sex': '男'}
# 方式一
del my_dict['sex']
print(my_dict) # {'name': '⼩明', 'age': 19, 'like': ['抽烟', '喝酒', '烫头', '学习']}
# 方式二
my_dict.pop('age')
print(my_dict) # {'name': '⼩明', 'like': ['抽烟', '喝酒', '烫头', '学习']}
***清空clear()***
'''
列表.clear()
'''
my_dict = {'name': '⼩明', 'like': ['抽烟', '喝酒', '烫头', '学习']}
my_dict.clear()
print(my_dict) # {}
***查询***
'''
方式一:字典[键]
方式二(常用):字典.get(键,值)
注意:(方式一)
1.如果键存在,返回键对应的值
2.如果键不存在,会报错
注意:(方式二)
1.如果键存在,返回键对应的值
2.如果键不存在, 返回括号中书写的值,没写就返回None
3.值⼀般不写, 默认是 None
'''
my_dict = {'name': '⼩明', 'age': 19, 'like': ['抽烟', '喝酒', '烫头', '学习']}
# 方式一
print(my_dict['name']) # ⼩明
print(my_dict['sex']) # 报错KeyError: 'sex'
# 方式二
print(my_dict.get('name')) # ⼩明
print(my_dict.get('name', 'zzz')) # ⼩明
print(my_dict.get('sex')) # None
print(my_dict.get('sex', '保密')) # 保密
***遍历(只遍历键)***
'''
方式一:
for 变量 in 字典:
print(变量)
方式二:
for 变量 in 字典.keys():
print(变量)
'''
my_dict = {'name': '⼩明', 'age': 18, 'sex': '男'}
# 方式一
for k in my_dict:
print(k)
# 方式二
for k in my_dict.keys():
print(k)
***遍历(只遍历值)***
'''
for 变量 in 字典.values():
print(变量)
'''
my_dict = {'name': '⼩明', 'age': 18, 'sex': '男'}
for k in my_dict.values():
print(k)
***遍历(遍历键值对)***
'''
for 变量1, 变量2 in 字典.items():
print(变量1, 变量2)
'''
my_dict = {'name': '⼩明', 'age': 18, 'sex': '男'}
for k, v in my_dict.items():
print(k, v)
总结
***字符串,列表,元组 ⽀持加法运算***
str1 = 'hello' + ' world'
print(str1) # hello world
list1 = [1, 2] + [3, 4]
print(list1) # [1, 2, 3, 4]
tuple1 = (1, 2) + (3, 4)
print(tuple1) # (1, 2, 3, 4)
***字符串,列表,元组 ⽀持乘⼀个数字***
str1 = 'hello ' * 3
print(str1) # hello hello hello
list1 = [1, 2] * 3
print(list1) # [1, 2, 1, 2, 1, 2]
tuple1 = (1, 2) * 3
print(tuple1) # (1, 2, 1, 2, 1, 2)
扩展——组包和拆包
***组包***
'''
变量名 = a,b,...
'''
pack = 1,2,3
print(pack) # (1, 2, 3)
***拆包***
'''
变量名1,变量名2,... = 容器
注意:
1.变量的个数要与容器中数据的个数保持一致
'''
a,b,c = (1,2,3)
print(a,b,c) # 1 2 3
a,b,c = [1,2,3]
print(a,b,c) # 1 2 3
a,b,c = '123'
print(a,b,c) # 1 2 3
a,b,c = {'name':'张三','sex':'男','age':18}
print(a,b,c) # name sex age
函数
***标准函数的定义和调用***
'''
定义:
def 函数名(形参1,形参2,...):
"""文档注释"""
函数体
调用:
函数名(实参1,实参2,...)
注意:
1.函数的返回值:(遇到return的话会结束函数的执行)
a.pass:表示函数没有返回值,返回None
b.return:表示函数没有返回值,返回None
c.return xxx:表示函数返回xxx
d.return xxx,xxx,...:表示函数返回(xxx,xxx,...)
2.文档注释不是必须写,用于告诉别人这个函数干什么的。
3.函数必须先定义才能调用。
4.函数可以嵌套调用,即在一个函数的定义中调用一个函数。
'''
def func1():
"""pass"""
pass
result = func1()
print(result) # None
def func2():
"""return"""
return
result = func2()
print(result) # None
def func3(a, b, c):
"""return xxx"""
num = a + b + c
return num
result = func3(1,2,3)
print(result) # 6
def func4(a, b, c):
"""return xxx,xxx,..."""
num1 = a + b
num2 = b + c
num3 = a + c
return num1,num2,num3
result = func4(1,2,3)
print(result,result[0],result[1],result[2]) # (3, 5, 4) 3 5 4
x,y,z = func4(1,2,3)
print(x,y,z) # 3 5 4
def func5():
"""函数的嵌套调用"""
num = func3(1,2,3) + 1
return num
result = func5()
print(result) # 7
***标准函数的参数***
'''
方式一:位置参数
方式二:关键字参数
方式三:缺省参数
方式四:不定长位置参数(也叫不定长元组参数)
方式五:不定长关键字参数(也叫不定⻓字典参数)
注意:(方式一)
1.调用时按顺序将实参传给形参
注意:(方式二)
1.调用时将指定数据值传给指定形参
2.关键字参数必须在位置参数之后
3.不要给一个形参传多个数据值
注意:(方式三)
1.意在定义函数时给某些形参默认值,给了默认值的形参变为缺省参数,调用时可以传实参也可以不传
a.如果传了实参,使用的就是传的实参值
b.如果没传实参,使用的就是默认值
2.缺省参数的书写要放在普通参数的后边
注意:(方式四)
1.在普通形参名称前面加上一个*,这个参数就变成了不定长位置参数。常写为*args
2.不定⻓位置参数,要写在普通参数的后⾯
注意:(方式五)
1.在普通形参名称前面加上两个*,这个参数就变成了不定长关键字参数。常写为**kwargs
2.不定⻓关键字参数,要写在所有参数的最后⾯
'''
def func(a, b, c):
print(f'a: {a}, b: {b}, c: {c}')
# 方式一
func(1, 2, 3) # a: 1, b: 2, c: 3
# 方式二
func(1, 2, c=3) # a: 1, b: 2, c: 3
# 方式三
def func(a, b, c=3):
print(f'a: {a}, b: {b}, c: {c}')
func(1, 2, 4) # a: 1, b: 2, c: 4
func(1, 2) # a: 1, b: 2, c: 3
#方式四
def func(*args):
print(type(args), args)
func(1, 2, 3) # <class 'tuple'> (1, 2, 3)
# 方式五
def func(**kwargs):
print(type(kwargs), kwargs)
func(a=1, b=2, c=3) # <class 'dict'> {'a': 1, 'b': 2, 'c': 3}
***匿名函数的使用***
'''
变量 = lambda 参数1,参数2,...: 表达式
变量()
注意:
1.匿名函数只能书写表达式(一行代码),表达式的结果就是返回值。
'''
# 1. ⽆参⽆返回值
func1 = lambda: print('hello lambda')
func1() # hello lambda
# 2. ⽆参有返回值
func2 = lambda: 'hello lambda'
print(func2()) # hello lambda
# 3. 有参⽆返回值
fuc3 = lambda a, b: print(a+b)
fuc3(10, 20) # 30
# 4. 有参有返回值
func4 = lambda a, b: a+b
print(func4(10, 20)) # 30
类和对象
类:相似事物的抽象,泛指的,比如“人”。由类名、属性、方法构成。
1.类名:事物的统称。比如“人”
2.属性:事物的特征。比如“名字”
3.方法:事物的行为。比如“吃饭”
对象:具体的事物,特指的,比如“张三”。
(但其实python中一切皆对象,类也叫类对象,这里提到的对象指的是实例对象)
***类的定义***
'''
class 类名:
属性
方法
注意:
1.类名:需满⾜⼤驼峰命名法(每个单词的⾸字⺟⼤写)。
2.属性:主要分为实例属性、类属性。
1)实例属性:是实例对象具有的属性,每个实例对象都存在。一般定义在类内部的_init_()方法中。
2)类属性:是类对象具有的属性,只在类对象中存在一份。一般定义在类内部,方法外部。
3.方法:主要分为实例方法、类方法、静态方法。
1)实例方法(常用):在类中直接定义的函数(第一个参数是self)。一般需要使用实例属性的都必须定义为实例方法。
关于self:
a.实际上self只是个形参而已,可以为任意变量名,只是我们习惯性写成self。
b.self虽说是形参,但调用时并不传递实参值,调用时会自动将调用这个方法的对象传递给self,所以self的本质是对象。
2)类方法(会用):在类中使用 @classmethod 装饰的函数(参数一般写作cls)。一般不需要使用实例属性,需要使用类属性的,定义为类方法。
3)静态方法(了解):在类中使用 @staticmethod 装饰的函数(一般没有参数)。一般不需要使用实例属性,也不需要使用类属性的,定义为静态方法。
补充:
1.魔法方法:python 中有⼀类⽅法, 以两个下划线开头,两个下划线结尾,并且在满⾜某个条件的情况下, 会⾃动调⽤, 这类⽅法称为魔法方法。常用:
1)__init__():创建对象时会自动调用
2)__str__():使用print(对象)打印对象时会自动调用。注意该方法必须返回一个字符串,print(对象)时会输出该方法返回的字符串。若类没有定义该方法,则print(对象)时会默认输出对象的引用地址。
2.魔法属性:
1)__dict__:使用 对象.__dict__ ,可将对象的属性组成字典返回
'''
class Person:
# 定义类属性count
count = 0
def __init__(self, name, weight):
# 定义实例属性name、weight
self.name = name
self.weight = weight
Person.count += 1
def __str__(self):
return f"姓名: {self.name}, 体重:{self.weight}"
# 定义实例方法run()、eat()
def run(self):
print(f'{self.name}跑了步, 体重减少了0.5')
self.weight -= 0.5
def eat(self):
print(f'{self.name}吃了饭, 体重增加了1')
self.weight += 1
# 定义类方法show_count()
@classmethod
def show_count(cls):
print(cls.count)
# 定义静态方法show_help()
@staticmethod
def show_help():
print('这是帮助信息')
***类的使用***
'''
【创建实例对象】
变量 = 类名()
【调用实例方法】
对象.方法名()
【获取实例属性】
对象.属性名
【调用类方法】
类名.方法名()
【获取类属性】
类名.属性名
'''
# 创建实例对象zhangsan
zhangsan = Person('张三', 75.0)
print(zhangsan) # 姓名: 张三, 体重:75.0
# 获取实例对象zhangsan的所有属性
print(zhangsan.__dict__) # {'name': '张三', 'weight': 75.0}
# 调用实例方法run()
zhangsan.run() # 张三跑了步, 体重减少了0.5
print(zhangsan) # 姓名: 张三, 体重:74.5
# 调用实例方法eat()
zhangsan.eat() # 张三吃了饭, 体重增加了1
print(zhangsan) # 姓名: 张三, 体重:75.5
# 获取实例对象zhangsan的name属性值
print(zhangsan.name) # 张三
# 修改实例对象zhangsan的name属性值
zhangsan.name = '李四'
print(zhangsan.name) # 李四
# 为实例对象zhangsan增加属性sex
zhangsan.sex = '男'
print(zhangsan.sex) # 男
# 调用类方法show_count()
Person.show_count() # 1
# 获取类对象Person的count属性值
print(Person.count) # 1
# 修改类对象Person的count属性值
Person.count = 3
print(Person.count) # 3
# 为类对象Person增加属性type
Person.type = '人'
print(Person.type) # 人
# 调用静态方法show_help()
Person.show_help() # 这是帮助信息
***公有和私有***
'''
在类内部,属性名或方法名前加两个下划线__,它们就变为私有的。私有的属性和方法只能在类内部使用,外部使用会报错。
'''
class Person:
def __init__(self, name, age):
# 定义公有属性
self.name = name
# 定义私有属性
self.__age = age
# 定义公有方法
def methodPublic(self):
print('我是公有方法')
# 定义私有方法
def __methodPrivate(self):
print('我是私有方法')
xm = Person('小明', 18)
print(xm.name) # 小明
print(xm.__age) # 报错
xm.methodPublic() # 我是公有方法
xm.__methodPrivate() # 报错
***继承***
'''
class 子类名(父类名):
属性
方法
注意:
1.子类可以使用父类的公有属性和方法
2.正常创建的类看起来没有父类,其实也有,是object(object类是python中最顶级的类)
'''
class Animal:
def eat(self):
print('动物要吃东西')
class Dog(Animal):
def bark(self):
print('狗汪汪汪地叫')
animal = Animal()
animal.eat() # 动物要吃东西
dog = Dog()
dog.eat() # 动物要吃东西
dog.bark() # 狗汪汪汪地叫
***重写***
'''
若子类中定义了与父类中名字相同的方法,就是重写
注意:
1.重写之后调用的方法指的子类的方法,不再调用父类的方法。
2.重写的方式主要分为覆盖和扩展。
'''
# 覆盖
class Dog:
def bark(self):
print('汪汪汪叫.....')
class XTQ(Dog):
def bark(self):
print('嗷嗷嗷叫...')
xtq = XTQ()
xtq.bark() # 嗷嗷嗷叫...
# 扩展
class Dog:
def bark(self):
print('汪汪汪叫.....')
class XTQ(Dog):
def bark(self):
print('嗷嗷嗷叫...',end = ',')
super().bark()
xtq = XTQ()
xtq.bark() # 嗷嗷嗷叫...,汪汪汪叫.....
文件
文本文件(我们操作的基本都是文本文件):能够使⽤记事本软件打开的。比如txt, md, py , html, css, js , json
二进制文件:不能使⽤记事本软件打开的。比如exe, mp3, mp4, jpg, png
'''
以下所有用到的文件原内容都是:
哈哈哈哈哈
哈哈哈哈哈
哈哈哈哈哈
'''
***文件的打开、读写、关闭***
'''
【打开文件】
open(file, mode='...', encoding='...')
注意:
1.file:是要打开的⽂件的路径。可以是相对路径,也可以是绝对路径。建议使⽤相对路径(相对于当前代码⽂件所在的路径, ./打头 )
2.mode:打开方式,可不写。
r:read 只读打开
w:write 只写打开
a:append 追加打开
3.encoding:编码方式。
gbk:将⼀个汉字转换为 2 个字节⼆进制
utf-8(常用):将⼀个汉字转换为 3 个字节⼆进
制
4.返回值:返回的是一个文件对象。
【读文件】
文件对象.read(n)
注意:
1.文件的打开方式需要为r
2.参数 n 表示读取多少个字符, ⼀般不写,表示读取全部内容
3.返回值:读取到的文件内容
【写文件】
⽂件对象.write('写⼊⽂件的内容')
注意:
1.⽂件的打开⽅式是 w 或者 a
2.⽂件不存在,会直接创建⽂件;⽂件存在,会覆盖原⽂件
3.返回值:写入的字符数
【关闭文件】
⽂件对象.close()
注意:
1.将⽂件占⽤的资源进⾏清理,同时会保存⽂件, ⽂件关
闭之后,这个⽂件对象就不能使⽤了
'''
# 打开⽂件
f1 = open('c:/Users/lai/Desktop/test/test1.txt', 'r', encoding='utf-8')
f2 = open('c:/Users/lai/Desktop/test/test2.txt', 'r', encoding='utf-8')
f3 = open('c:/Users/lai/Desktop/test/test3.txt', 'w', encoding='utf-8')
f4 = open('c:/Users/lai/Desktop/test/test4.txt', 'a', encoding='utf-8')
# 读⽂件全部内容
readf1 = f1.read()
print(readf1)
'''
哈哈哈哈哈
哈哈哈哈哈
哈哈哈哈哈
'''
# 读⽂件前七个字符(换行也算一个哦)
readf2 = f2.read(7)
print(readf2)
'''
哈哈哈哈哈
哈
'''
# 覆盖写入
writef3 = f3.write('哈哈哈哈哈')
print(writef3) # 5
'''
最终文件内容为:
哈哈哈哈哈
'''
# 追加写入
writef4 = f4.write('\n哈哈哈哈哈')
print(writef4) # 6
'''
最终文件内容为:
哈哈哈哈哈
哈哈哈哈哈
哈哈哈哈哈
哈哈哈哈哈
'''
# 关闭⽂件
f1.close()
f2.close()
f3.close()
f4.close()
***使⽤with open打开⽂件***
'''
with open(file, mode='...', encoding='...') as 变量:
文件的读写操作
注意:
1.这么写的好处是不用自己书写关闭文件的代码,出缩进后文件自动关闭
'''
with open('c:/Users/lai/Desktop/test/test1.txt', mode='r', encoding='utf-8') as f:
readf = f.read()
print(readf)
'''
哈哈哈哈哈
哈哈哈哈哈
哈哈哈哈哈
'''
***按行读取文件内容***
'''
⽂件对象.readline()
注意:
1.执行readline() 时,会扫描文件中的每一个字节,直到找到一个 \n,然后停止并读取此前的文件内容。
'''
with open('c:/Users/lai/Desktop/test/test1.txt', encoding='utf-8') as f:
while True:
readf = f.readline()
if readf:
print(readf)
else:
break
'''
哈哈哈哈哈
哈哈哈哈哈
哈哈哈哈哈
'''
扩展——json文件的读写
'''
原本的json文件内容为:
[
{
"name": "⼩明",
"age": 18,
"isMen": true,
"like": [
"听歌",
"游戏",
"购物",
"吃饭",
"睡觉",
"打⾖⾖"
],
"address": {
"country": "中国",
"city": "上海"
}
},
{
"name": "⼩红",
"age": 17,
"isMen": false,
"like": [
"听歌",
"购物",
"学习"
],
"address": {
"country": "中国",
"city": "北京"
}
}
]
'''
***json文件的读***
'''
1. 导包:import json
2. 读打开⽂件
3. 读⽂件:json.load(⽂件对象)
'''
import json
with open('c:/Users/lai/Desktop/test/test.json', 'r', encoding='utf-8') as f:
infolist = json.load(f)
print(infolist)
'''
[{'name': '⼩明', 'age': 18, 'isMen': True, 'like': ['听歌', '游戏', '购物', '吃饭', '睡觉', '打⾖⾖'], 'address': {'country': '中国', 'city': '上海'}}, {'name': '⼩红', 'age': 17, 'isMen': False, 'like': ['听歌', '购物', '学习'], 'address': {'country': '中国', 'city': '北京'}}]
'''
for info in infolist:
print(info)
'''
{'name': '⼩明', 'age': 18, 'isMen': True, 'like': ['听歌', '游戏', '购物', '吃饭', '睡觉', '打⾖⾖'], 'address': {'country': '中国', 'city': '上海'}}
{'name': '⼩红', 'age': 17, 'isMen': False, 'like': ['听歌', '购物', '学习'], 'address': {'country': '中国', 'city': '北京'}}
'''
***json文件的写***
'''
1. 导包:import json
2. 写打开⽂件
3. 写⽂件:json.dump(data, ⽂件对象)
'''
import json
data = [{'name': '⼩张', 'age': 18, 'isMen': True, 'like': ['听歌', '游戏', '购物', '吃饭', '睡觉', '打⾖⾖'], 'address': {'country': '中国', 'city': '上海'}}]
with open('c:/Users/lai/Desktop/test/test.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False)
'''
最终的文件内容:
[{'name': '⼩张', 'age': 18, 'isMen': True, 'like': ['听歌', '游戏', '购物', '吃饭', '睡觉', '打⾖⾖'], 'address': {'country': '中国', 'city': '上海'}}]
'''
异常
异常:程序在运⾏时,如果 Python 解释器 遇到⼀个错误,会停⽌程序的执⾏,并且提示⼀些错误信息,这就是异常。
异常捕获:程序遇到异常, 默认会终⽌代码程序的执⾏, 可以使⽤ 异常捕获, 让程序代码继续运⾏
异常传递: 在函数嵌套调⽤的过程中, 被调⽤的函数 ,发⽣了异
常,如果没有捕获,会将这个异常向外层传递. … 如果传到最
外层还没有捕获,才报错
'''
try:
书写可能发⽣异常的代码
except 异常类型1:
发⽣了异常1执⾏的代码
except 异常类型2:
发⽣了异常2执⾏的代码
...
except Exception as 变量:
发⽣其他常见异常执⾏的代码
(Exception 是常⻅异常类的⽗类, 这⾥书写 Exception可以捕获常⻅的所有异常, 常用print(变量)来打印异常信息)
else:
没有发⽣异常会执⾏的代码
finally:
不管有没有发⽣异常,都会执⾏的代码
注意:
1.若抛出指定异常类型及其子类的异常,会执行相应except缩进中的代码,且后续的代码也能正常执行。
2.异常类型可不写,代表遇到任意异常类型都执行except缩进中的代码。
'''
num = input('请输⼊数字:')
num = int(num)
a = 10 / num
'''
若在控制台输入字符串,回车会抛出异常:
ValueError: invalid literal for int() with base 10: '...'
若在控制台输入0,回车会抛出异常:
ZeroDivisionError: division by zero
'''
try:
num = input('请输⼊数字:')
num = int(num)
a = 10 / num
except ValueError:
print('请输⼊正确的数字')
except Exception as e:
print(f"错误信息为: {e}")
else:
print('没有发⽣异常我会执⾏')
finally:
print('不管有没有发⽣异常,我都会执⾏')
'''
若在控制台输入字符串,回车会打印如下内容:
请输⼊正确的数字
不管有没有发⽣异常,我都会执⾏
若在控制台输入0,回车会打印如下内容:
错误信息为: division by zero
不管有没有发⽣异常,我都会执⾏
若在控制台输入正常的数字,回车会打印如下内容:
没有发⽣异常我会执⾏
不管有没有发⽣异常,我都会执⾏
'''
import 与 from…import
'''
将整个模块导入,语句为: import 模块
从某个模块中导入某个对象,语句为: from 模块 import 对象
从某个模块中导入多个对象,语句为: from 模块 import 对象1, 对象2, 对象3
将某个模块中的全部对象导入,语句为: from 模块 import *
'''


















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









