



课程资源:[中文课件](1.10 I/O Redirect | MIT6.S081)阅读材料CN[官网](6.S081 / Fall 2021)
Lec01 Introduction and Examples
整体介绍
课程目标:理解操作系统的设计(整体的结构)和实现(代码长什么样)
操作系统能干嘛?
- Abstraction:第一个就是抽象硬件(进程,文件系统)
- multiplex:在多个应用程序之间共用硬件资源
- Isolation:不同的活动之间不能相互干扰
- Sharing:数据能共享
- Security:所以在共享的同时,我们也希望在没有必要的时候不共享
- Performance:帮助应用程序获得高性能
Kernel是什么
ChatGPT 说:
在操作系统里,Kernel(内核) 就是 操作系统的核心部分。它负责直接和硬件打交道,并为上层的软件(应用程序)提供运行环境。可以把它理解成:
👉 硬件(CPU、内存、磁盘、网卡等)和应用程序之间的“中间层”。
内核的主要功能:
-
进程管理(Process Management)
- 创建、销毁、调度进程(决定哪个程序先用 CPU)。
- 提供进程间通信(IPC)。
-
内存管理(Memory Management)
-
给进程分配和回收内存。
-
提供虚拟内存机制,让每个进程“以为”自己有独占的内存空间。
-
-
文件系统管理(File System Management)
-
组织和管理磁盘上的数据。
-
提供统一的文件接口(打开、读写、关闭文件),屏蔽底层存储细节。
-
-
设备管理(Device Management)
-
管理硬件设备(打印机、键盘、网卡等)。
-
通过 驱动程序 把设备差异封装起来,对上层提供统一的接口。
-
-
系统调用接口(System Call Interface)
-
给用户程序提供调用内核功能的“入口”。
-
比如
read(),write(),fork(),都是系统调用。
-
类比理解
-
用户程序 = 乘客
-
硬件 = 汽车
-
内核 = 司机
-
用户程序不会直接“开车”,而是通过“司机”(内核)发出请求。
-
内核负责真正操作硬件,让系统安全、稳定地运行。
-
要不要我给你画一个 图解(应用程序 → 内核 → 硬件的关系),这样更直观?
read,write,exit 系统调用
read
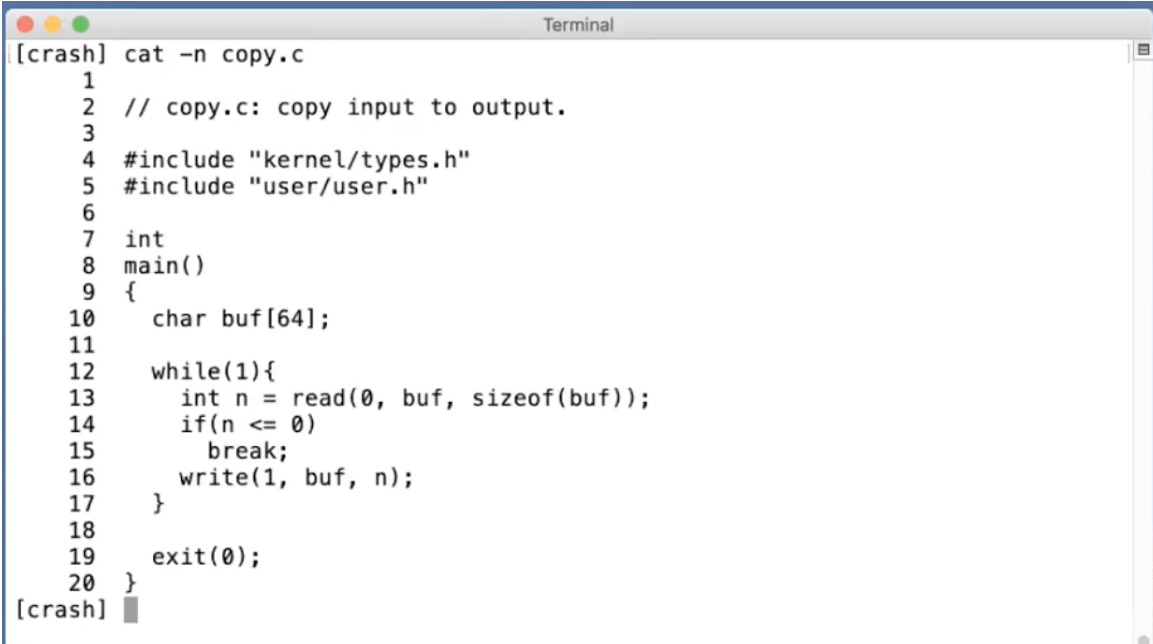

如果你看第13行的read,它接收3个参数:
-
第一个参数是文件描述符,指向一个之前打开的文件。Shell会确保默认情况下,当一个程序启动时,文件描述符0连接到console的输入,文件描述符1连接到了console的输出。所以我可以通过这个程序看到console打印我的输入。当然,这里的程序会预期文件描述符已经被Shell打开并设置好。这里的0,1文件描述符是非常普遍的Unix风格,许多的Unix系统都会从文件描述符0读取数据,然后向文件描述符1写入数据。
-
read的第二个参数是指向某段内存的指针,程序可以通过指针对应的地址读取内存中的数据,这里的指针就是代码中的buf参数。在代码第10行,程序在栈里面申请了64字节的内存,并将指针保存在buf中,这样read可以将数据保存在这64字节中。
-
read的第三个参数是代码想读取的最大长度,sizeof(buf)表示,最多读取64字节的数据,所以这里的read最多只能从连接到文件描述符0的设备,也就是console中,读取64字节的数据。
open



open系统调用会返回一个新分配的文件描述符,这里的文件描述符是一个小的数字,可能是2,3,4或者其他的数字。
之后,这个文件描述符作为第一个参数被传到了write,write的第二个参数是数据的指针,第三个参数是要写入的字节数。数据被写入到了文件描述符对应的文件中。
文件描述符本质上对应了内核中的一个表单数据。内核维护了每个运行进程的状态,内核会为每一个运行进程保存一个表单,表单的key是文件描述符。这个表单让内核知道,每个文件描述符对应的实际内容是什么。这里比较关键的点是,每个进程都有自己独立的文件描述符空间,所以如果运行了两个不同的程序,对应两个不同的进程,如果它们都打开一个文件,它们或许可以得到相同数字的文件描述符,但是因为内核为每个进程都维护了一个独立的文件描述符空间,这里相同数字的文件描述符可能会对应到不同的文件。
Shell
ls > out重定向grep x < out注:grep x会搜索输入中包含x的行
fork系统调用

在第12行,我们调用了fork。fork会拷贝当前进程的内存,并创建一个新的进程,这里的内存包含了进程的指令和数据。之后,我们就有了两个拥有完全一样内存的进程。fork系统调用在两个进程中都会返回,在原始的进程中,fork系统调用会返回大于0的整数,这个是新创建进程的ID。而在新创建的进程中,fork系统调用会返回0。所以即使两个进程的内存是完全一样的,我们还是可以通过fork的返回值区分旧进程和新进程。
在第16行,你可以看到代码检查pid。如果pid等于0,那么这必然是子进程。
![[Pasted image 20250912172542.png]]
输出看起来像是垃圾数据。这里实际发生的是,fork系统调用之后,两个进程都在同时运行
exec,wait 系统调用
exec 函数要求参数以数组形式传递,且数组第一个元素必须是程序名(通常与执行的程序名一致),后续元素才是实际要传递的参数,最后以 0(或 NULL)结尾。
例如代码中的 argv[] = { "echo", "this", "is", "echo", 0 }:
- 第一个元素
"echo"是程序名(相当于命令行中输入的echo) - 后面的
"this"、"is"、"echo"才是真正传递给echo程序的参数


对于那些想要运行程序,但是还希望能拿回控制权的场景,可以先执行fork系统调用,然后在子进程中调用exec。

Unix提供了一个wait系统调用,如第20行所示。wait会等待之前创建的子进程退出。

学生提问:为什么父进程在子进程调用exec之前就打印了“parent waiting”?
Robert教授:这里只是巧合。父进程的输出有可能与子进程的输出交织在一起,就像我们之前在fork的例子中看到的一样,只是这里正好没有发生而已。并不是说我们一定能看到上面的输出,实际上,如果看到其他的输出也不用奇怪。我怀疑这里背后的原因是,exec系统调用代价比较高,它需要访问文件系统,访问磁盘,分配内存,并读取磁盘中echo文件的内容到分配的内存中,分配内存又可能需要等待内存释放。所以,exec系统调用背后会有很多逻辑,很明显,处理这些逻辑的时间足够长,这样父进程可以在exec开始执行echo指令之前完成输出。这样说得通吧?
I/O Redirect

Shell之所以有echo hello > out 重定向的能力 ,是因为Shell首先会像第13行一样fork,然后在子进程中,Shell改变了文件描述符。文件描述符1通常是进程用来作为输出的(也就是console的输出文件符),Shell会将文件描述符1改为output文件,之后再运行你的指令。同时,父进程的文件描述符1并没有改变。所以这里先fork,再更改子进程的文件描述符,是Unix中的常见的用来重定向指令的输入输出的方法,这种方法同时又不会影响父进程的输入输出。因为我们不会想要重定向Shell的输出,我们只想重定向子进程的输出

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









