



 本文详细介绍了Hive中的Join操作,包括CommonJoin、MapJoin、BucketMapJoin、SMBJoin和SkewJoin。CommonJoin通过排序和分发数据进行join,MapJoin将小表构建为哈希表并广播到所有map节点,BucketMapJoin基于分桶优化MapJoin,SMBJoin则利用已排序和分桶的表直接进行join。SkewJoin针对数据倾斜问题,采用混合join策略。这些优化技术旨在提高大数据处理效率。
本文详细介绍了Hive中的Join操作,包括CommonJoin、MapJoin、BucketMapJoin、SMBJoin和SkewJoin。CommonJoin通过排序和分发数据进行join,MapJoin将小表构建为哈希表并广播到所有map节点,BucketMapJoin基于分桶优化MapJoin,SMBJoin则利用已排序和分桶的表直接进行join。SkewJoin针对数据倾斜问题,采用混合join策略。这些优化技术旨在提高大数据处理效率。
2021SC@SDUSC
山大软工实践hive(4)-join算子
杂碎
- hive支持等值join,但不支持非等值join,也就是涉及<>的比较在join后进行
- JoinOperator为基础,其他join为在此之上的优化
common join
把每个表的读取排序分发给一组mapper(由RS算子实现),再输出给join算子进行join操作。小表优先放入内存以提高效率(内存满时大表就会部分地放在磁盘,使用时才从磁盘读取,让小表在内存减少反复读取磁盘的开销)

在Mapper阶段读取表的数据转换为键值对,经过shuffle让有相应key的输出到相应Reducer
在JoinOperator process方法中
// The input is sorted by alias, so if we are already in the last join
// operand,
// we can emit some results now.
// Note this has to be done before adding the current row to the
// storage,
// to preserve the correctness for outer joins.
checkAndGenObject();
直到最右边的表被读完(join操作中最后的表),才进行join操作,否则把读取的内容放入内存
这个checkAndGenObject()由CommonJoinOperator,JoinOperator继承了这个类
而在CommonJoinOperator中,实现了各种连接(内外连接等),如下图部分
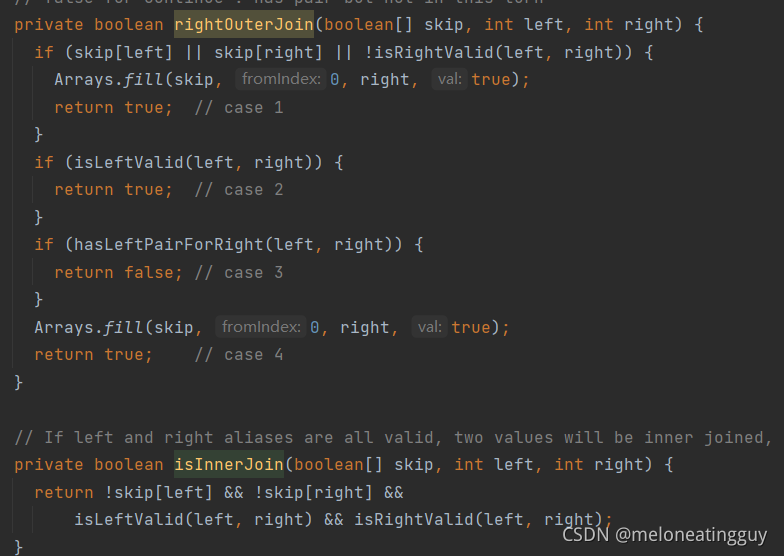
Map join
用小表(包含数据少的表)的join key为键创建hash表,把hash表广播到所有map节点上,map节点获取大表数据,根据hash表进行join操作
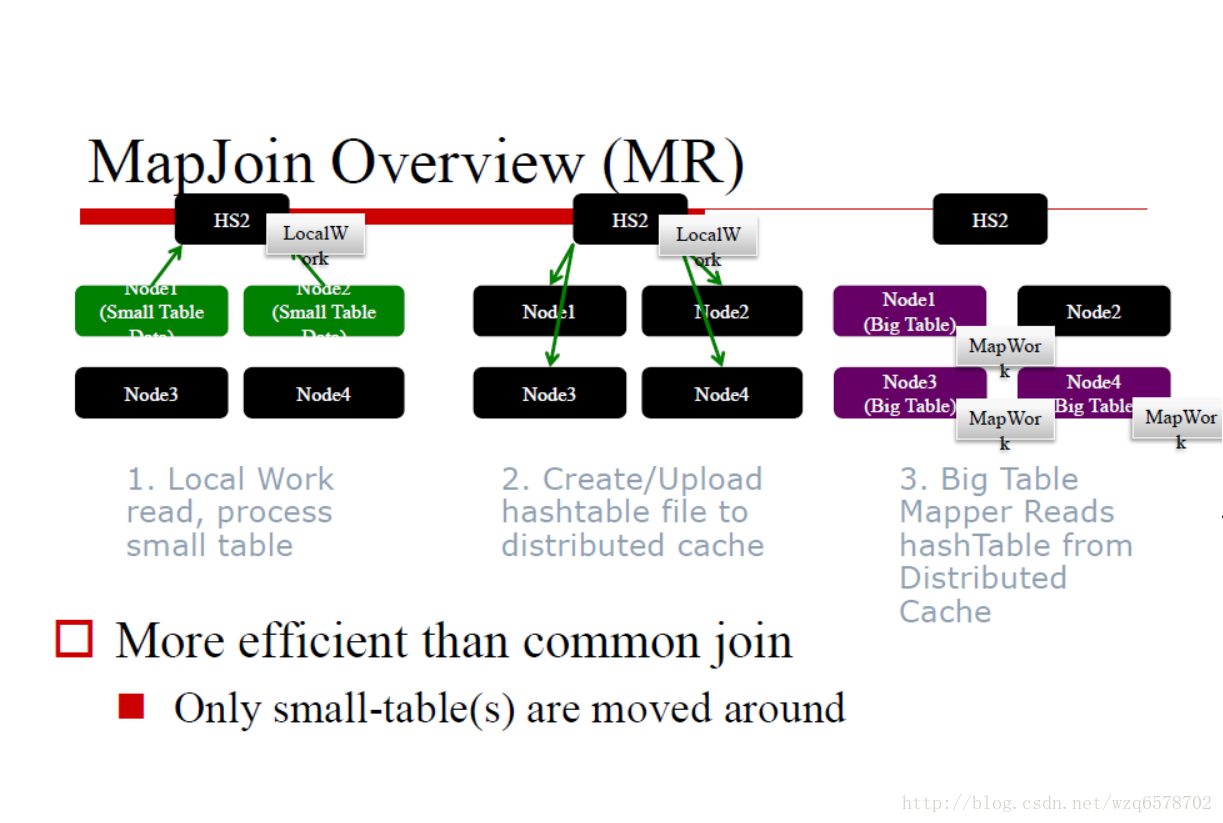
猜测:基于hash表只创建小表的hash表。如果不创建hash表,就会进行排序->join的操作(大小表都要排序,不然不能归并连接),造成排序上的开销,也相当于省略了RS节点。不过如果表原本就是按照join key排的序,如key为主键,则可进行普通join
比如下图,以CityId 进行join
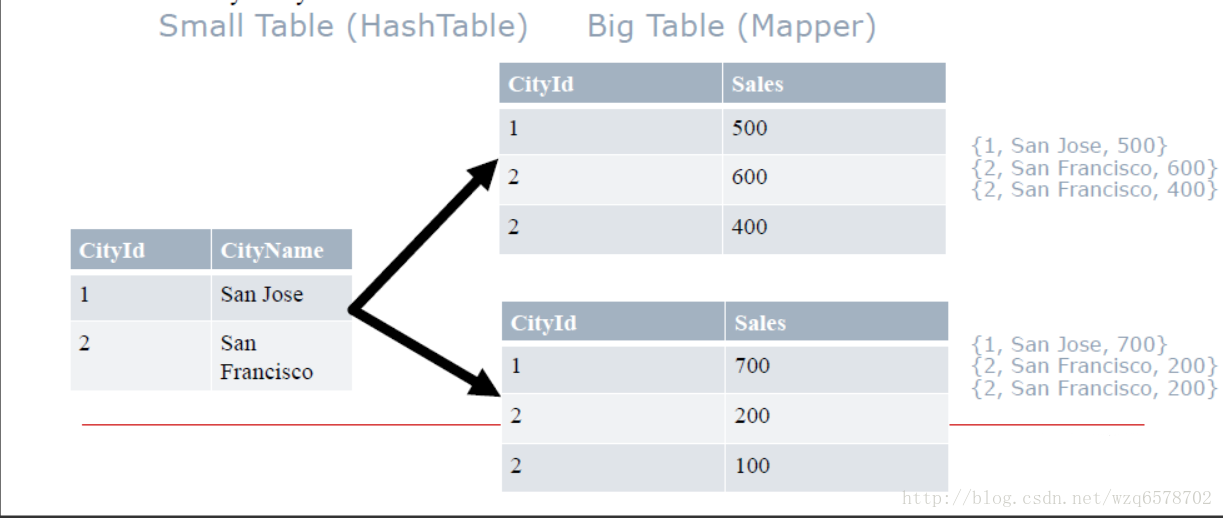
该方法适用于小表足够小的情况
猜测:小表过大会使每个map节点单次处理时间变长,虽然总时间可能会少。这是因为一般会把每个表分成许多map节点读取,让每个不同表的节点之间进行join,虽然次数多,但每个节点小,总而言之,把nm换成了(a个n/a)(b个m/b)
所有小表要能够完全读入内存,可手动要求进行map join,或按照默认(规定小表大小最大值)
BucketMapJoin
首先是Bucket表,在创建时声明如CLUSTERED BY (cityId) INTO 2 BUCKETS,就会把表按cityId分到两个桶储存(每个桶存一部分,比如id为奇数偶数)
在此基础上MapJoin,就会为每个桶创建一个hash表,其他操作类似
SMB join
比如一个表是CLUSTERED BY (cityId) SORTED BY (cityId) INTO 2 BUCKETS,既分桶又排序,并且join时按照该属性join,那就可以直接common join(直接省去排序分段的操作,即不用RS算子,不过桶太大应该还是会切割桶吧?),避免了广播hash表的开销
源代码注释声明,归并排序map join
/**
* Sorted Merge Map Join Operator.
*/
public class SMBMapJoinOperator extends AbstractMapJoinOperator<SMBJoinDesc> implements
Serializable {
Skew Join
有的键会出现特别多次,这可能导致reduce阶段数据倾斜
于是把join过程分为处理非倾斜键的Common join与处理倾斜键的map join
可以在创建表时指定某属性倾斜 — create table … skewed by (key) on (key_value);然后在逻辑优化时unoin两种join
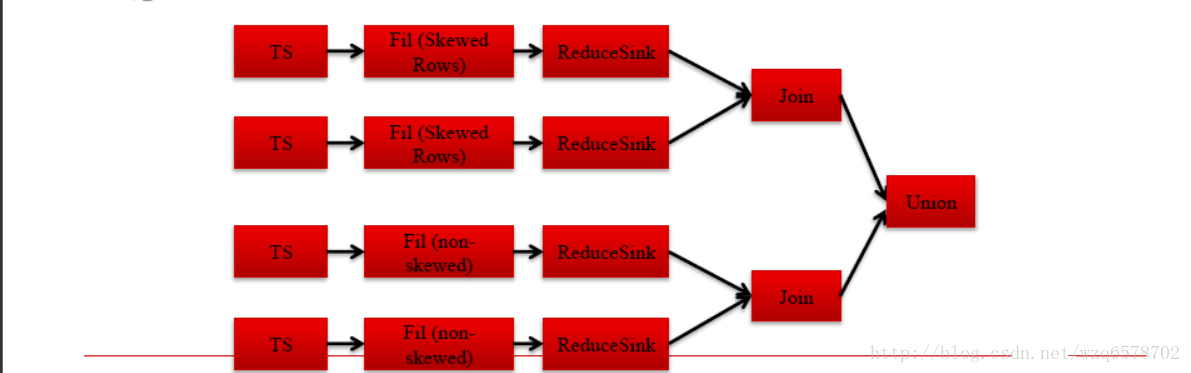
关于union算子,它不做什么事
/**
* Union Operator Just forwards. Doesn't do anything itself.
**/
public class UnionOperator extends Operator<UnionDesc> implements Serializable {
下一步
可以开始看逻辑优化部分,也可以看DAG是怎么构造的(输入怎么来的),理论上如果凑不出13篇,再看输入是怎么来的是不错的选择

















 3239
3239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









