







由于EM算法的推导常使用GMM算法来举例子,故下面先介绍高斯混合算法
一般的高斯算法(单个高斯)
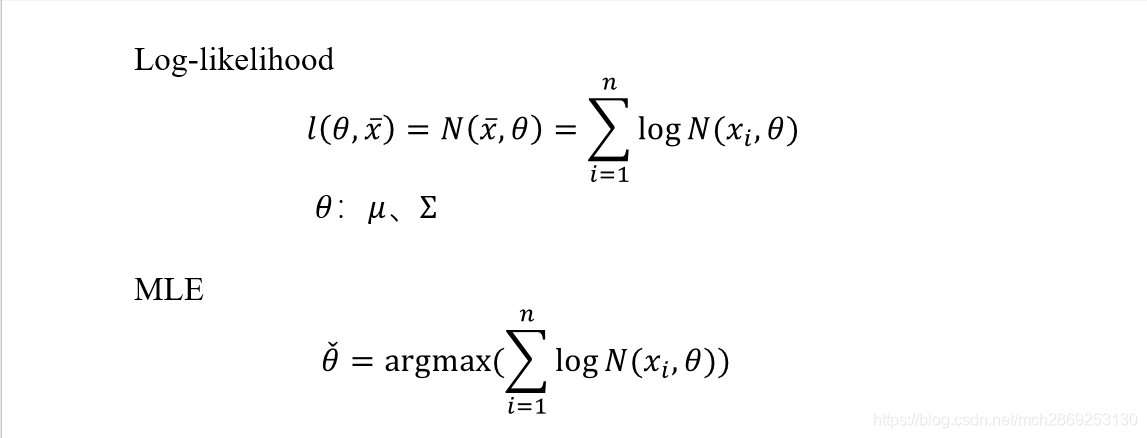
上式是单个高斯分布,对于单个高斯分布,给定一组观测数据,求参数时通常用MLE(极大似然估计)就可以了,具体做法就是分别对均值和方差求导数,然后令导数=0求解即可。
高斯混合算法
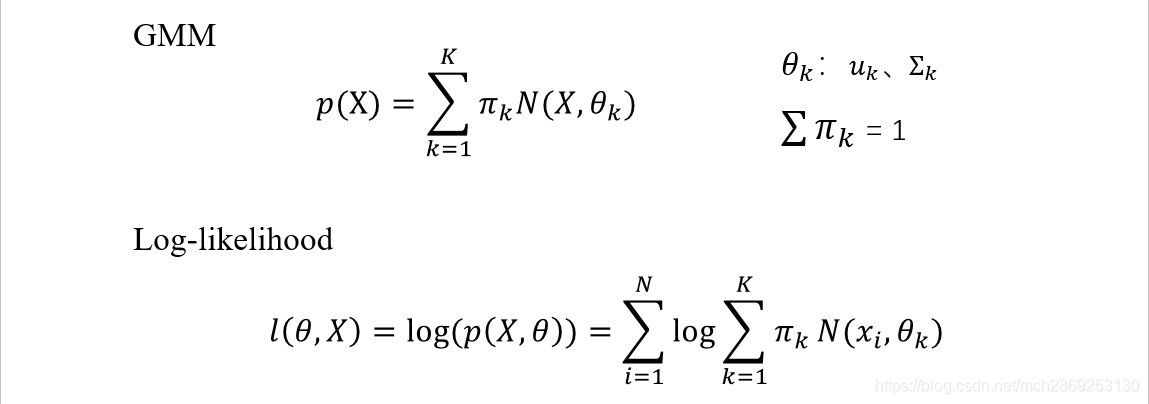
上面是高斯混合算法的一般形式和对数似然函数形式。与单个高斯分布相比,GMM算法是由k个高斯加权平均混合而成的,
π
k
\pi_{k}
πk是第k个高斯所占的权重(也就是每个高斯的先验概率),每个高斯均有自己的均值和方差,因此GMM共有
3
k
3k
3k个未知参数,但是又因为
π
k
\pi_{k}
πk的和为1,故最终若确定了前面
k
−
1
k-1
k−1个
π
i
\pi_{i}
πi,最后一个
π
k
\pi_{k}
πk就确定了,故共有
3
k
−
1
3k-1
3k−1个未知参数。
从似然函数可以看出,GMM算法的对数似然函数中
l
o
g
log
log里面是和式,故不能使用MLE来求解这
3
k
−
1
3k-1
3k−1个未知参数。应该使用EM算法来求解。
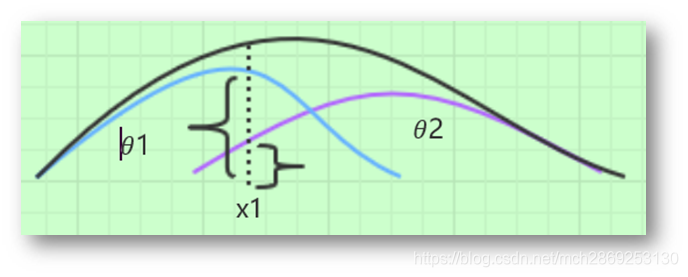
从这个图可以看出,样本空间中的一个样本点
x
1
x_{1}
x1的概率值是
x
1
x_{1}
x1分别由2个高斯产生的概率加权而成的,这个权值就是前面的
π
k
\pi_{k}
πk。从这里也可以看出GMM算法是软聚类算法,一个样本点是同时属于多个cluster,只是属于每个cluster的程度不同,样本点
x
1
x_{1}
x1最终属于哪个类就取
π
k
\pi_{k}
πk最大的那一类。
公式推导
下面的公式推导要用到贝叶斯公式和全概率公式,如果不清楚可以看链接:全概率公式、贝叶斯公式推导过程
单个样本
x
x
x的概率如下式
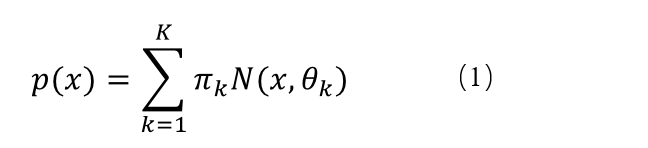
对于(1)式,对于单个样本点
x
x
x,虽然我们并不能观测到
x
x
x是属于哪一类的,但是
x
x
x肯定是属于
k
k
k类中的某一类,因此这里就存在一个隐变量,我们设为
z
z
z,
z
是
一
个
K
维
的
o
n
e
−
h
o
t
向
量
z是一个K维的one-hot向量
z是一个K维的one−hot向量,只有第k维为1,其余为0,表示样本点
x
x
x属于第k类。
p
(
z
k
=
1
)
=
π
k
p(z_{k}=1)=\pi_{k}
p(zk=1)=πk
上面的式子表示样本点
x
x
x属于第k类的概率是
π
k
\pi_{k}
πk,若确定了样本点
x
x
x属于第k类的概率
π
k
\pi_{k}
πk,则在这个条件下,样本点在第k类高斯分布中的概率分布就变成了单个的高斯分布。
p
(
x
∣
z
k
=
1
)
=
N
(
x
∣
μ
k
,
Σ
k
)
p(x|z_{k}=1)=N(x|\mu_{k},\Sigma_{k})
p(x∣zk=1)=N(x∣μk,Σk)
最终将样本点
x
x
x在k个高斯分布下的概率累加就是(2)式,也就是最终的GMM分布的概率公式
p
(
x
)
=
∑
z
p
(
z
)
p
(
x
∣
z
)
=
∑
k
=
0
K
−
1
π
k
N
(
x
∣
μ
k
,
Σ
k
)
(2)
\tag{2} \begin{aligned} p(x) = &\sum_{z}p(z)p(x|z) \\ = &\sum_{k=0}^{K-1} \pi_{k}N(x|\mu_{k}, \Sigma_{k}) \end{aligned}
p(x)==z∑p(z)p(x∣z)k=0∑K−1πkN(x∣μk,Σk)(2)
(2)式是由全概率公式得到的(
可
以
看
作
最
终
的
概
率
p
(
x
)
被
分
割
为
k
个
独
立
的
子
事
件
p
(
x
∣
z
)
可以看作最终的概率p(x)被分割为k个独立的子事件p(x|z)
可以看作最终的概率p(x)被分割为k个独立的子事件p(x∣z))。
由贝叶斯定理可以知道,
p
(
z
)
是
先
验
概
率
,
p
(
x
∣
z
)
是
似
然
概
率
p(z)是先验概率,p(x|z)是似然概率
p(z)是先验概率,p(x∣z)是似然概率,那么可以很方便的求出后验概率
p
(
z
∣
x
)
p(z|x)
p(z∣x)。
p
(
z
∣
x
)
=
p
(
z
)
p
(
x
∣
z
)
p
(
x
)
=
π
k
N
(
x
∣
μ
k
,
Σ
k
)
∑
k
=
0
K
−
1
π
k
N
(
x
∣
,
μ
k
,
Σ
k
)
\begin{aligned} p(z|x) = & {p(z)p(x|z) \over p(x)} \\ = &{\pi_{k}N(x|\mu_{k},\Sigma_{k}) \over \sum_{k=0}^{K-1}\pi_{k}N(x|,\mu_{k}, \Sigma_{k})} \end{aligned}
p(z∣x)==p(x)p(z)p(x∣z)∑k=0K−1πkN(x∣,μk,Σk)πkN(x∣μk,Σk)
给定一个样本点
x
n
x_{n}
xn,并且已知GMM模型的参数(也就是
π
,
μ
,
Σ
\pi, \mu,\Sigma
π,μ,Σ),求其属于第k类的概率是:
γ
n
k
=
p
(
z
k
=
1
∣
x
n
)
=
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
∑
k
=
0
K
−
1
π
k
N
(
x
n
∣
,
μ
k
,
Σ
k
)
(3)
\tag{3} \gamma_{nk}=p(z_{k}=1|x_{n})={\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k}) \over \sum_{k=0}^{K-1}\pi_{k}N(x_{n}|,\mu_{k}, \Sigma_{k})}
γnk=p(zk=1∣xn)=∑k=0K−1πkN(xn∣,μk,Σk)πkN(xn∣μk,Σk)(3)
对于一个样本
x
n
x_{n}
xn,其后验概率
γ
n
k
\gamma_{nk}
γnk的和为1,
γ
n
k
\gamma_{nk}
γnk表示样本
x
n
x_{n}
xn属于第k类cluster的概率。
假设我们有一组数据
X
=
x
1
,
x
2
,
,
,
x
n
X={x_{1},x_{2},,,x_{n}}
X=x1,x2,,,xn,并且知道这组数据中的每一个数据都是由哪个高斯产生的,也就是对于样本集
X
X
X中的某个样本
x
t
x_{t}
xt,知道其对应的
z
t
(
一
个
K
维
向
量
)
,
其
中
z
t
0
=
0
,
z
t
1
=
0
,
.
.
,
z
t
i
=
1
,
.
.
,
z
t
K
=
0
z_{t}(一个K维向量),其中z_{t0}=0,z_{t1}=0,..,z_{ti}=1,..,z_{tK}=0
zt(一个K维向量),其中zt0=0,zt1=0,..,zti=1,..,ztK=0。这样的
(
x
t
,
z
t
)
(x_t, z_t)
(xt,zt)我们称为完全数据。那么这组完全数据的似然函数就是
p
(
X
,
Z
∣
θ
)
=
p
(
X
,
Z
∣
π
,
μ
,
Σ
)
=
∏
t
=
1
n
∏
k
=
1
K
(
π
k
N
(
x
t
∣
μ
k
,
Σ
k
)
)
z
t
k
p(X,Z|\theta)=p(X,Z|\pi,\mu,\Sigma)=\prod_{t=1}^{n} \prod_{k=1}^{K}(\pi_{k}N(x_{t}|\mu_{k},\Sigma_{k}))^{z_{tk}}
p(X,Z∣θ)=p(X,Z∣π,μ,Σ)=t=1∏nk=1∏K(πkN(xt∣μk,Σk))ztk
其中
θ
\theta
θ是k个高斯的参数,每个高斯含有3个参数,X是样本空间。
EM算法的推导
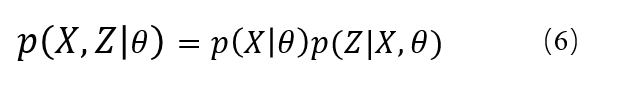
(6)式可由概率论的知识得到,其含义是在已知GMM参数的情况下,
X
,
Z
X,Z
X,Z的联合概率分布。
将(6)式中的
p
(
Z
∣
X
,
θ
)
p(Z|X,\theta)
p(Z∣X,θ)移到等号左边并取对数
l
o
g
p
(
X
∣
θ
)
=
l
o
g
p
(
X
,
Z
∣
θ
)
p
(
Z
∣
X
,
θ
)
(7)
\tag{7} logp(X|\theta) = log{p(X, Z|\theta) \over p(Z|X,\theta)}
logp(X∣θ)=logp(Z∣X,θ)p(X,Z∣θ)(7)
将(7)式等号右边分子分母同时除以
Z
的
真
实
分
布
q
(
Z
)
Z的真实分布q(Z)
Z的真实分布q(Z):
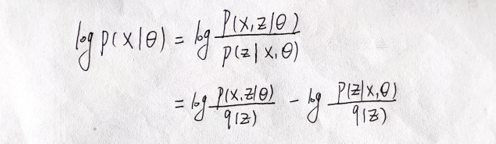
在上式两边同时乘以
Z
的
真
实
分
布
q
(
Z
)
并
对
Z
积
分
Z的真实分布q(Z)并对Z积分
Z的真实分布q(Z)并对Z积分得(相当于对
l
o
g
p
(
X
∣
θ
)
logp(X|\theta)
logp(X∣θ)求期望)
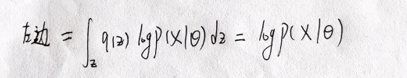
由于
l
o
g
p
(
X
∣
θ
)
logp(X|\theta)
logp(X∣θ)不含有Z,故最后
q
(
Z
)
q(Z)
q(Z)积分结果为1。
对等式右边积分结果如下:
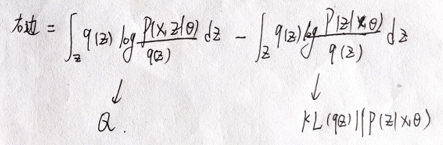
第二项连同负号是KL散度的形式,恒大于等于0,故有
l
o
g
p
(
X
∣
θ
)
≥
Q
logp(X|\theta) \ge Q
logp(X∣θ)≥Q
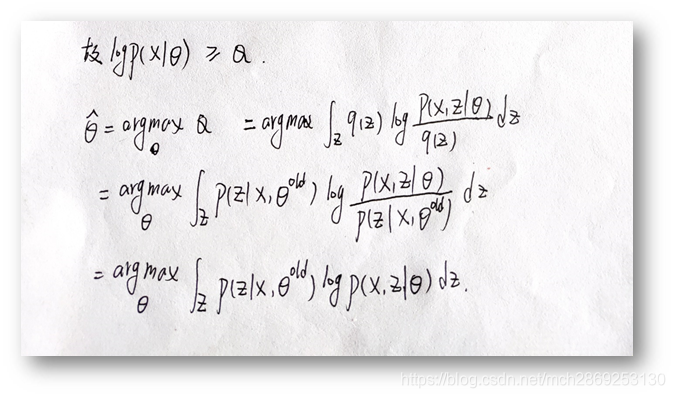
即Q函数是似然函数
l
o
g
p
(
X
∣
θ
)
logp(X|\theta)
logp(X∣θ)的一个下界,要最大化似然函数,只要最大化Q函数就可以了。
q
(
Z
)
是
Z
q(Z)是Z
q(Z)是Z的真实分布,虽然我们无法观测到,但是必定存在,在推导中用
Z
的
上
一
次
分
布
的
结
果
p
(
Z
∣
X
,
θ
o
l
d
)
Z的上一次分布的结果p(Z|X, \theta^{old})
Z的上一次分布的结果p(Z∣X,θold)来代替
q
(
Z
)
q(Z)
q(Z)。
a
r
g
m
a
x
argmax
argmax中,后面那一项与?没有关系,故可以甩掉。
最后令上面的结果等于新的
Q
Q
Q,新的Q函数中含有已知量
θ
o
l
d
和
未
知
量
θ
\theta^{old}和未知量\theta
θold和未知量θ。
至此,EM算法推导结束。
下面总结一下EM算法:
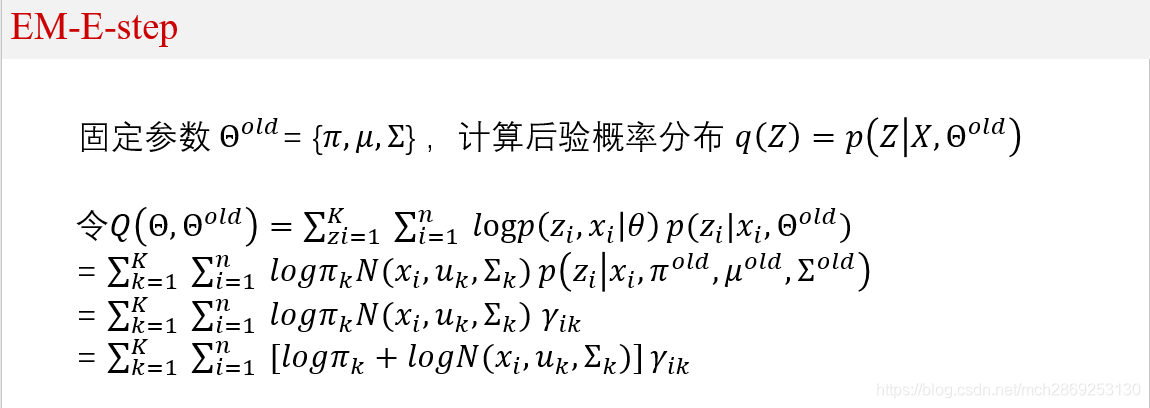
E-step:根据参数
θ
o
l
d
\theta^{old}
θold计算每个样本由第k类高斯产生的概率,也就是前面提到的后验概率
γ
n
k
\gamma_{nk}
γnk,将其值带入
Q
Q
Q函数,如上式所示。
根据Q函数的表达式可以看出,Q函数相当于是对变量
l
o
g
p
(
z
i
,
x
i
│
θ
)
logp(z_{i}, x_{i}│\theta)
logp(zi,xi│θ)求期望(将
p
(
z
i
∣
x
i
,
θ
o
l
d
)
p(z_{i}|x_{i}, \theta^{old})
p(zi∣xi,θold)看作其概率分布)。
这里的Q函数其实就是我们要求的似然函数的下界。
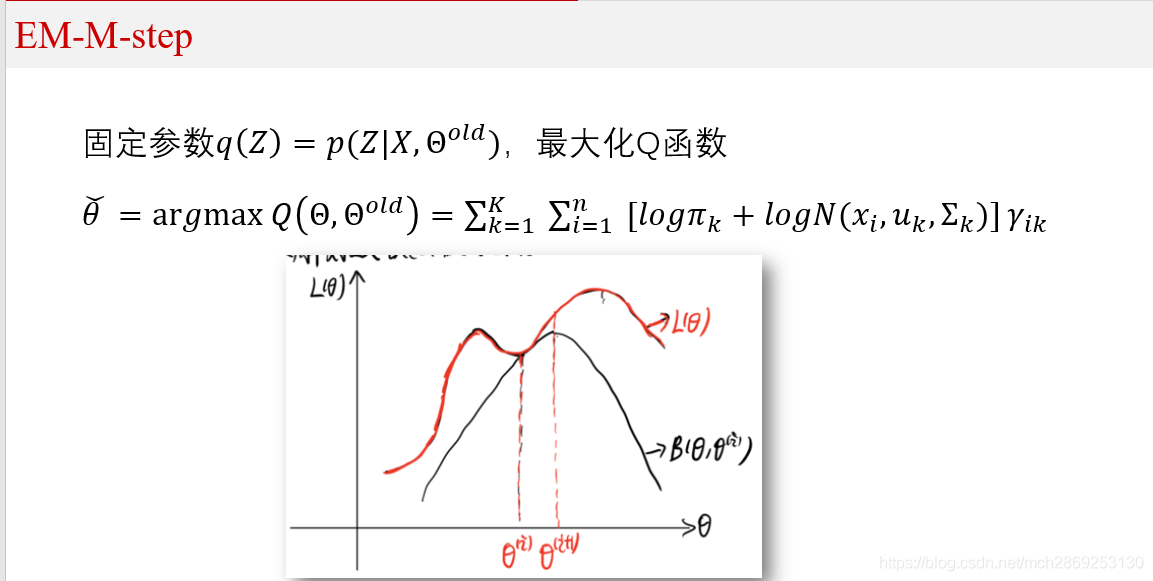
M-Step:根据计算得到的
γ
n
k
\gamma_{nk}
γnk,求出含有
θ
θ
θ的似然函数的下界(也就是Q函数)并最大化它,得到参数
θ
θ
θ的新值。
从图中可以看出,EM算法是迭代的求解参数,但是直接求解似然函数有困难,所以找到似然函数的一个下界Q函数,
每次先固定
Θ
Θ
Θ,然后求出
Q
(
Θ
)
Q(Θ)
Q(Θ)的表达式,再最大化
Q
(
Θ
)
Q(Θ)
Q(Θ)。
Q
Q
Q函数相当于是对
l
o
g
p
(
z
i
,
x
i
│
θ
)
logp(z_{i}, x_{i}│\theta)
logp(zi,xi│θ)求期望,故称作最大期望算法。
看不懂的同学可以看悉尼科技大学徐亦达的视频或者b站上的白板推导视频。

















 31万+
31万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









