




 本文探讨了冒泡排序的基本原理,并逐步展示了如何通过减少不必要的比较和提前判断列表是否已排序来优化冒泡排序算法,从而提高其效率。通过三次优化,冒泡排序的性能得到了显著提升。
本文探讨了冒泡排序的基本原理,并逐步展示了如何通过减少不必要的比较和提前判断列表是否已排序来优化冒泡排序算法,从而提高其效率。通过三次优化,冒泡排序的性能得到了显著提升。
基础版
# 冒泡排序
def bubble_sort(li):
li_len = len(li)
for i in range(li_len - 1):
for j in range(i + 1, li_len):
if li[i] > li[j]: # 只要当前数字比下一个大,就将它向上移动
li[i], li[j] = li[j], li[i]优化版一
# 优化:是不是每一次都要比较到末尾? ''' 肯定不需要! 第一次冒泡后,最大的元素在最末尾 第二次冒泡后,第二大的元素在倒数第二 第三次冒泡后,第三大的元素在倒数第三 ... 因此,可以依次类推,冒泡n次后,后面的n个元素都是有序的,所以不需要再进行额外的比较
def bubble_sort2(li):
li_len = len(li)
for i in range(li_len - 1):
for j in range(i + 1, li_len - i - 1): # 只对乱序的部分进行排序
if li[j] > li[j + 1]: # 只要当前数字比下一个大,就将它向上移动
li[j], li[j + 1] = li[j + 1], li[j]再优化
# 再优化:当排到某一趟时,如果这一趟过程中所有的数字都没有发生交换,是不是就可以认为列表是已经排好序了? ''' 答案是肯定的! '''
def bubble_sort3(li):
li_len = len(li)
for i in range(li_len - 1):
exchanged = False
for j in range(i + 1, li_len - i - 1): # 只对乱序的部分进行排序
if li[j] > li[j + 1]: # 只要当前数字比下一个大,就将它向上移动
li[j], li[j + 1] = li[j + 1], li[j]
# 如果这一趟发生了交换,就将exchanged的值置位True
exchanged = True
if not exchanged:
break # 如果这一趟没有发生交换,说明已经排好序!最后看一下测试结果!
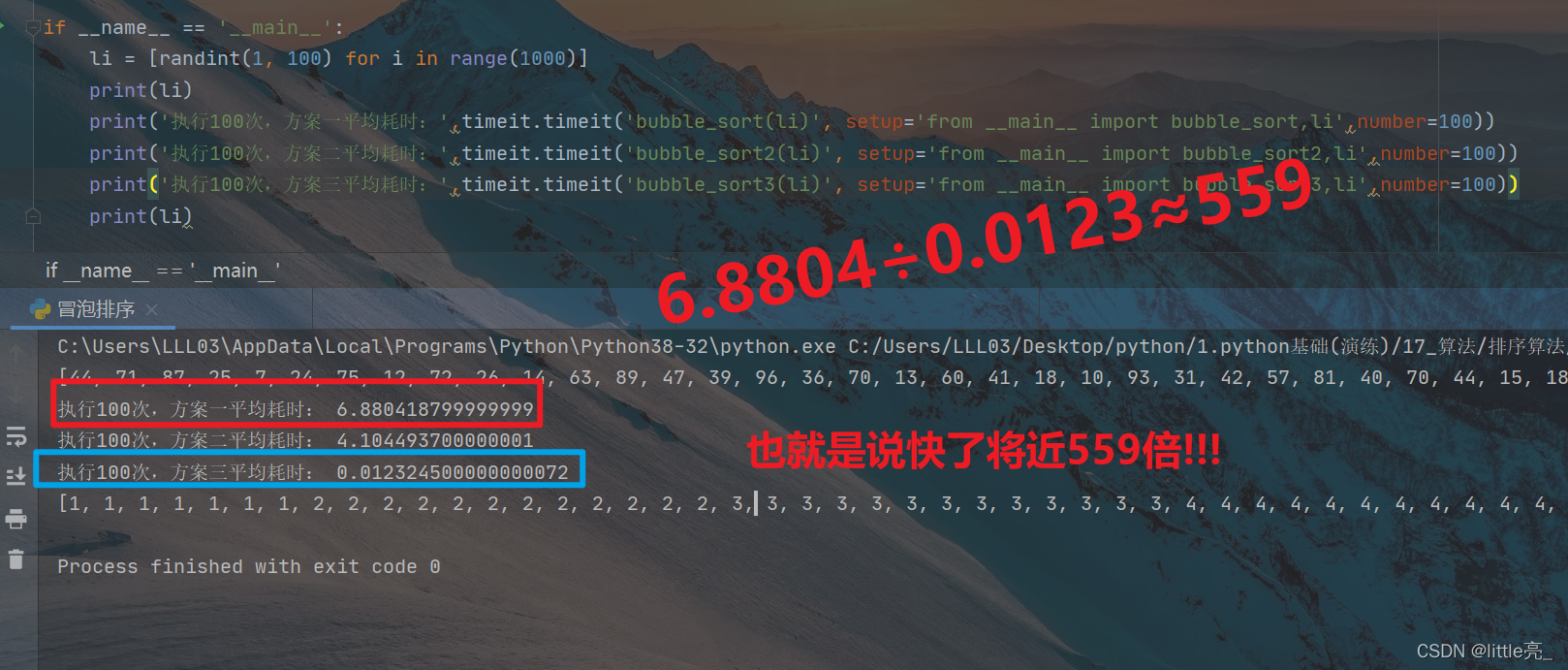
同步更新于个人博客系统:别小瞧冒泡排序,优化一下不也挺快的嘛?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









