 RecRecNet:广角图像畸变矫正新算法
RecRecNet:广角图像畸变矫正新算法





摘要
论文地址:RecRecNet: Rectangling Rectified Wide-Angle Images by Thin-Plate Spline Model and DoF-based Curriculum Learning
源码地址:https://github.com/KangLiao929/RecRecNet
广角镜头在VR技术等领域有着诱人的应用,但它会使拍摄的图像产生严重的径向畸变。为了还原真实场景,以往的工作致力于校正广角图像的内容。然而,这种校正方法不可避免地会扭曲图像边界,改变相关的几何分布,并误导当前的视觉感知模型。在这项工作中,我们通过提出一种新的学习模型,即矩形校正网络(RecRecNet),探索在内容和边界上构建一种双赢的表示。特别是,我们提出了一个薄板样条(TPS)模块来构建用于图像矩形化的非线性和非刚性变换。通过学习校正后图像上的控制点,我们的模型可以灵活地将源结构扭曲到目标域,并实现端到端的无监督变形。为了缓解结构逼近的复杂性,我们接着启发RecRecNet通过基于自由度(DoF)的课程学习来掌握渐进变形规则。通过在每个课程阶段增加自由度,即从相似变换(4自由度)到单应变换(8自由度),网络能够探究更详细的变形,在最终的矩形化任务上实现快速收敛。实验表明,我们的方法在定量和定性评估上都优于对比方法。
算法实现
1.模型训练
环境安装:
conda create -n recrecnet python=3.6
git clone https://github.com/KangLiao929/RecRecNet.git
conda activate recrecnet
pip install -r requirements.txt
训练数据集下载:train.zip,test.zip 。
预训练模型下载地址:https://drive.google.com/file/d/1y9iTfWCycS3BAFViMsClbur11IY-HgXf/view,
下载之后将其放入.\checkpoint文件夹中。
生成数据:
sh scripts/curriculum_gen.sh
模型训练:
sh scripts/train.sh
模型测试:
sh scripts/test.sh
2.模型推理
2.1 C++推理
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <fstream>
#include <string>
#include <math.h>
#include <opencv2/dnn.hpp>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
using namespace dnn;
Mat linspace(float begin, float finish, int number)
{
float interval = (finish - begin) / (number - 1);//
Mat f(1, number, CV_32FC1);
for (int i = 0; i < f.rows; i++)
{
for (int j = 0; j < f.cols; j++)
{
f.at<float>(i, j) = begin + j * interval;
}
}
return f;
}
void get_norm_rigid_mesh_inv_grid(Mat& grid, Mat& W_inv, const int input_height, const int input_width, const int grid_h, const int grid_w)
{
float interval_x = input_width / grid_w;
float interval_y = input_height / grid_h;
const int h = grid_h + 1;
const int w = grid_w + 1;
const int length = h * w;
Mat norm_rigid_mesh(length, 2, CV_32FC1);
///norm_rigid_mesh.create(length, 2, CV_32FC1);
Mat W(length + 3, length + 3, CV_32FC1);
for (int i = 0; i < h; i++)
{
for (int j = 0; j < w; j++)
{
const int row_ind = i * w + j;
const float x = (j * interval_x) * 2.0 / float(input_width) - 1.0;
const float y = (i * interval_y) * 2.0 / float(input_height) - 1.0;
W.at<float>(row_ind, 0) = 1;
W.at<float>(row_ind, 1) = x;
W.at<float>(row_ind, 2) = y;
W.at<float>(length, 3 + row_ind) = 1;
W.at<float>(length + 1, 3 + row_ind) = x;
W.at<float>(length + 2, 3 + row_ind) = y;
norm_rigid_mesh.at<float>(row_ind, 0) = x;
norm_rigid_mesh.at<float>(row_ind, 1) = y;
}
}
for (int i = 0; i < length; i++)
{
for (int j = 0; j < length; j++)
{
const float d2_ij = powf(W.at<float>(i, 0) - W.at<float>(j, 0), 2.0) + powf(W.at<float>(i, 1) - W.at<float>(j, 1), 2.0) + powf(W.at<float>(i, 2) - W.at<float>(j, 2), 2.0);
W.at<float>(i, 3 + j) = d2_ij * logf(d2_ij + 1e-6);
}
}
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
W.at<float>(length + i, j) = 0;
}
}
W_inv = W.inv();
interval_x = 2.0 / (input_width - 1);
interval_y = 2.0 / (input_height - 1);
const int grid_width = input_height * input_width;
///Mat grid(length + 3, grid_width, CV_32FC1);
grid.create(length + 3, grid_width, CV_32FC1);
for (int i = 0; i < input_height; i++)
{
for (int j = 0; j < input_width; j++)
{
const float x = -1.0 + j * interval_x;
const float y = -1.0 + i * interval_y;
const int col_ind = i * input_width + j;
grid.at<float>(0, col_ind) = 1;
grid.at<float>(1, col_ind) = x;
grid.at<float>(2, col_ind) = y;
}
}
for (int i = 0; i < length; i++)
{
for (int j = 0; j < grid_width; j++)
{
const float d2_ij = powf(norm_rigid_mesh.at<float>(i, 0) - grid.at<float>(1, j), 2.0) + powf(norm_rigid_mesh.at<float>(i, 1) - grid.at<float>(2, j), 2.0);
grid.at<float>(3 + i, j) = d2_ij * logf(d2_ij + 1e-6);
}
}
norm_rigid_mesh.release();
}
void get_ori_rigid_mesh_tp(Mat& tp, Mat& ori_mesh_np_x, Mat& ori_mesh_np_y, const float* offset, const int input_height, const int input_width, const int grid_h, const int grid_w)
{
const float interval_x = input_width / grid_w;
const float interval_y = input_height / grid_h;
const int h = grid_h + 1;
const int w = grid_w + 1;
const int length = h * w;
tp.create(length + 3, 2, CV_32FC1);
ori_mesh_np_x.create(h, w, CV_32FC1);
ori_mesh_np_y.create(h, w, CV_32FC1);
for (int i = 0; i < h; i++)
{
for (int j = 0; j < w; j++)
{
const int row_ind = i * w + j;
const float x = j * interval_x + offset[row_ind * 2];
const float y = i * interval_y + offset[row_ind * 2 + 1];
tp.at<float>(row_ind, 0) = (j * interval_x + offset[row_ind * 2]) * 2.0 / float(input_width) - 1.0;
tp.at<float>(row_ind, 1) = (i * interval_y + offset[row_ind * 2 + 1]) * 2.0 / float(input_height) - 1.0;
ori_mesh_np_x.at<float>(i, j) = x;
ori_mesh_np_y.at<float>(i, j) = y;
}
}
for (int i = 0; i < 3; i++)
{
tp.at<float>(length + i, 0) = 0;
tp.at<float>(length + i, 1) = 0;
}
}
Mat _interpolate(Mat im, Mat xy_flat, Size out_size) ////xy_flat的形状是(2, 65536)
{
const int height = im.size[2];
const int width = im.size[3];
const int max_x = width - 1;
const int max_y = height - 1;
const float height_f = float(height);
const float width_f = float(width);
const int area = height * width;
const float* pdata = (float*)im.data; ////形状是(1,3,256,256)
Mat output(out_size.height, out_size.width, CV_32FC3);
for (int i = 0; i < height; i++)
{
for (int j = 0; j < width; j++)
{
const int col_ind = i * width + j;
float x = (xy_flat.at<float>(0, col_ind) + 1.0) * width_f * 0.5;
float y = (xy_flat.at<float>(1, col_ind) + 1.0) * height_f * 0.5;
int x0 = int(x);
int x1 = x0 + 1;
int y0 = int(y);
int y1 = y0 + 1;
x0 = std::min(std::max(x0, 0), max_x);
x1 = std::min(std::max(x1, 0), max_x);
y0 = std::min(std::max(y0, 0), max_y);
y1 = std::min(std::max(y1, 0), max_y);
int base_y0 = y0 * width;
int base_y1 = y1 * width;
int idx_a = base_y0 + x0;
int idx_b = base_y1 + x0;
int idx_c = base_y0 + x1;
int idx_d = base_y1 + x1;
float x0_f = float(x0);
float x1_f = float(x1);
float y0_f = float(y0);
float y1_f = float(y1);
float wa = (x1_f - x) * (y1_f - y);
float wb = (x1_f - x) * (y - y0_f);
float wc = (x - x0_f) * (y1_f - y);
float wd = (x - x0_f) * (y - y0_f);
float pix_r = wa * pdata[idx_a] + wb * pdata[idx_b] + wc * pdata[idx_c] + wd * pdata[idx_d];
float pix_g = wa * pdata[area + idx_a] + wb * pdata[area + idx_b] + wc * pdata[area + idx_c] + wd * pdata[area + idx_d];
float pix_b = wa * pdata[2 * area + idx_a] + wb * pdata[2 * area + idx_b] + wc * pdata[2 * area + idx_c] + wd * pdata[2 * area + idx_d];
output.at<Vec3f>(i, j) = Vec3f(pix_r, pix_g, pix_b);
}
}
return output;
}
Mat draw_mesh_on_warp(const Mat warp, const Mat f_local_x, const Mat f_local_y)
{
const int height = warp.rows;
const int width = warp.cols;
const int grid_h = f_local_x.rows - 1;
const int grid_w = f_local_x.cols - 1;
double minValue_x, maxValue_x; // 最大值,最小值
cv::Point minIdx_x, maxIdx_x; // 最小值坐标,最大值坐标
cv::minMaxLoc(f_local_x, &minValue_x, &maxValue_x, &minIdx_x, &maxIdx_x);
const int min_w = int(std::min(minValue_x, 0.0));
const int max_w = int(std::max(maxValue_x, double(width)));
double minValue_y, maxValue_y; // 最大值,最小值
cv::Point minIdx_y, maxIdx_y; // 最小值坐标,最大值坐标
cv::minMaxLoc(f_local_y, &minValue_y, &maxValue_y, &minIdx_y, &maxIdx_y);
const int min_h = int(std::min(minValue_y, 0.0));
const int max_h = int(std::max(maxValue_y, double(height)));
const int cw = max_w - min_w;
const int ch = max_h - min_h;
const int pad_top = 0 - min_h + 5;
const int pad_bottom = ch + 10 - (pad_top + height);
const int pad_left = 0 - min_w + 5;
const int pad_right = cw + 10 - (pad_left + width);
Mat pic;
copyMakeBorder(warp, pic, pad_top, pad_bottom, pad_left, pad_right, BORDER_CONSTANT, Scalar(255, 255, 255));
pic.convertTo(pic, CV_8UC3);
for (int i = 0; i < (grid_h + 1); i++)
{
for (int j = 0; j < (grid_w + 1); j++)
{
if (j == grid_w && i == grid_h) continue;
else if (j == grid_w)
{
line(pic, Point(int(f_local_x.at<float>(i, j) - min_w + 5), int(f_local_y.at<float>(i, j) - min_h + 5)), Point(int(f_local_x.at<float>(i + 1, j) - min_w + 5), int(f_local_y.at<float>(i + 1, j) - min_h + 5)), Scalar(0, 255, 0), 2);
}
else if (i == grid_h)
{
line(pic, Point(int(f_local_x.at<float>(i, j) - min_w + 5), int(f_local_y.at<float>(i, j) - min_h + 5)), Point(int(f_local_x.at<float>(i, j + 1) - min_w + 5), int(f_local_y.at<float>(i, j + 1) - min_h + 5)), Scalar(0, 255, 0), 2);
}
else
{
line(pic, Point(int(f_local_x.at<float>(i, j) - min_w + 5), int(f_local_y.at<float>(i, j) - min_h + 5)), Point(int(f_local_x.at<float>(i + 1, j) - min_w + 5), int(f_local_y.at<float>(i + 1, j) - min_h + 5)), Scalar(0, 255, 0), 2);
line(pic, Point(int(f_local_x.at<float>(i, j) - min_w + 5), int(f_local_y.at<float>(i, j) - min_h + 5)), Point(int(f_local_x.at<float>(i, j + 1) - min_w + 5), int(f_local_y.at<float>(i, j + 1) - min_h + 5)), Scalar(0, 255, 0), 2);
}
}
}
return pic;
}
class RecRecNet
{
public:
RecRecNet(string model_path);
vector<Mat> detect(Mat srcimg);
private:
const int input_height = 256;
const int input_width = 256;
const int grid_h = 8;
const int grid_w = 8;
Mat grid;
Mat W_inv;
Net net;
};
RecRecNet::RecRecNet(string model_path)
{
this->net = readNet(model_path);
get_norm_rigid_mesh_inv_grid(this->grid, this->W_inv, this->input_height, this->input_width, this->grid_h, this->grid_w);
}
vector<Mat> RecRecNet::detect(Mat srcimg)
{
Mat img;
cv::resize(srcimg, img, Size(this->input_width, this->input_height),cv::INTER_LINEAR);
img.convertTo(img, CV_32FC3, 1.0 / 127.5, -1.0);
Mat blob = blobFromImage(img);
this->net.setInput(blob);
vector<Mat> outs;
this->net.forward(outs, this->net.getUnconnectedOutLayersNames());
const float* offset = (float*)outs[0].data;
Mat tp, ori_mesh_np_x, ori_mesh_np_y;
get_ori_rigid_mesh_tp(tp, ori_mesh_np_x, ori_mesh_np_y, offset, this->input_height, this->input_width, this->grid_h, this->grid_w);
Mat T = W_inv * tp; ////_solve_system
T = T.t(); ////舍弃batchsize
Mat T_g = T * this->grid;
Mat output_tps = _interpolate(blob, T_g, Size(this->input_width, this->input_height));
Mat rectangling_np = (output_tps + 1)*127.5;
rectangling_np.convertTo(rectangling_np, CV_8UC3);
Mat input_np = (img + 1)*127.5;
vector<Mat> outputs;
outputs.emplace_back(rectangling_np);
outputs.emplace_back(input_np);
outputs.emplace_back(ori_mesh_np_x);
outputs.emplace_back(ori_mesh_np_y);
return outputs;
}
int main()
{
RecRecNet mynet("models/recrecnet.onnx");
std::string path = "testimgs";
std::vector<std::string> filenames;
cv::glob(path, filenames, false);
for (auto file_name : filenames)
{
Mat srcimg = imread(file_name);
vector<Mat> outputs = mynet.detect(srcimg);
Mat input_with_mesh = draw_mesh_on_warp(outputs[1], outputs[2], outputs[3]);
namedWindow("srcimg", WINDOW_NORMAL);
imshow("srcimg", srcimg);
namedWindow("rect", WINDOW_NORMAL);
imshow("rect", outputs[0]);
namedWindow("mesh", WINDOW_NORMAL);
imshow("mesh", input_with_mesh);
waitKey(0);
destroyAllWindows();
}
}
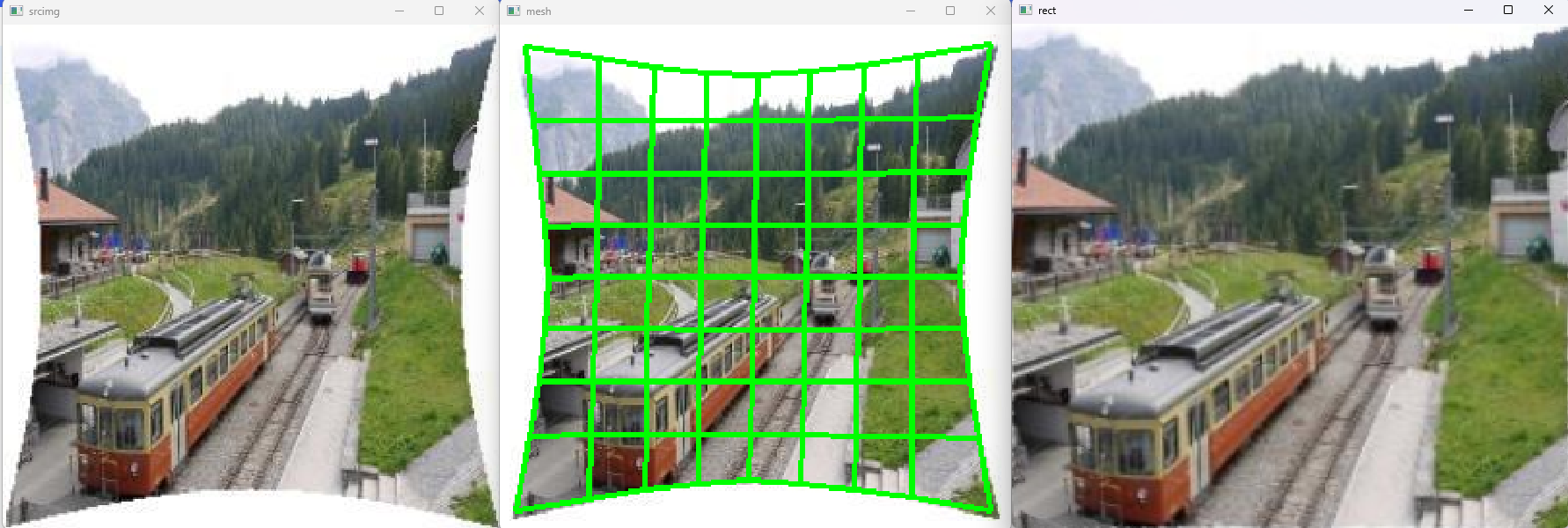
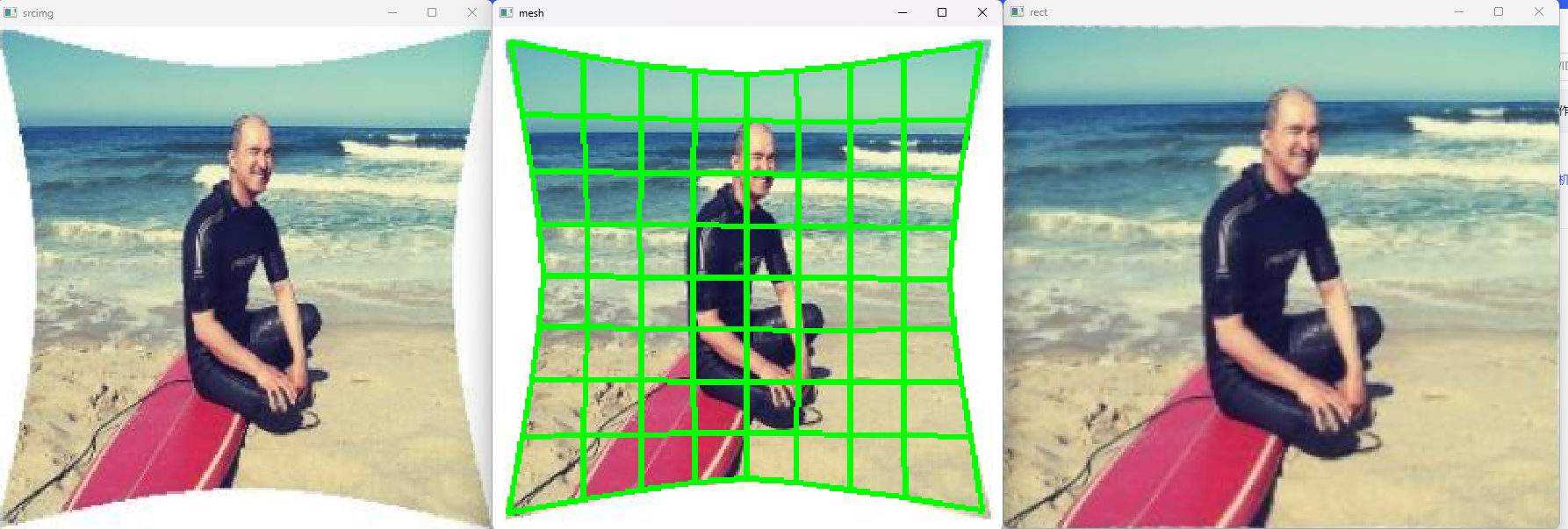
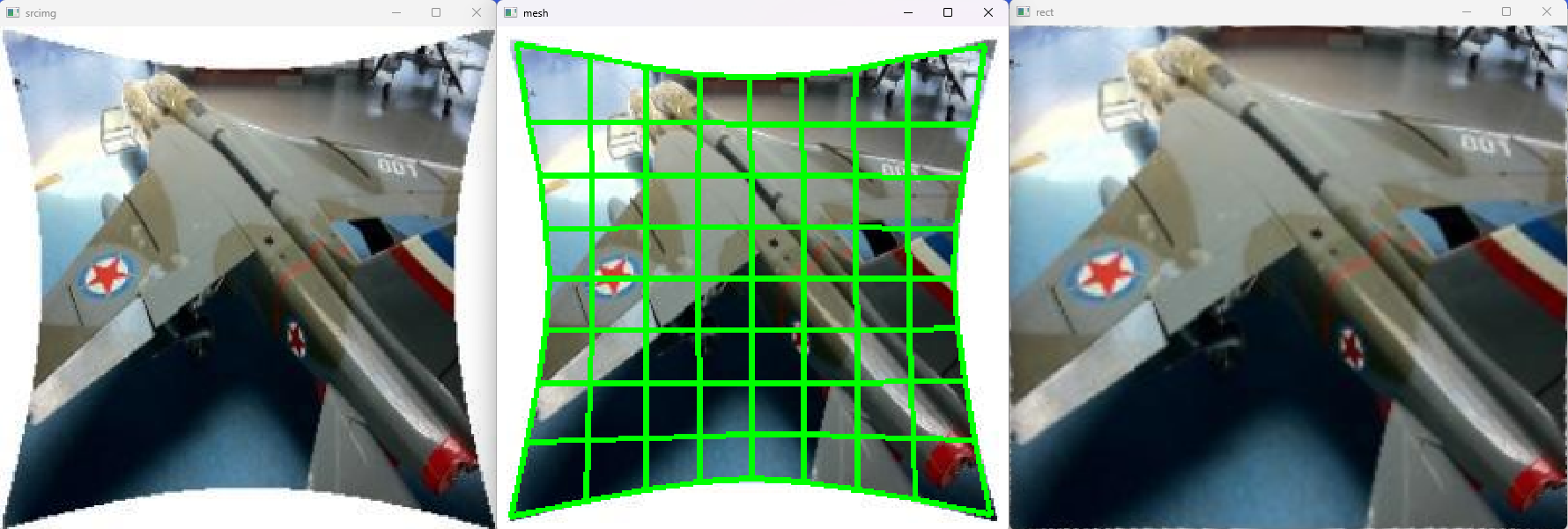
源码下载地址:https://download.youkuaiyun.com/download/matt45m/90362673
2.2 python推理
import cv2
import numpy as np
import argparse
from numpy_tps_transform import transformer, draw_mesh_on_warp
def get_rigid_mesh(height, width, grid_w, grid_h):
ww = np.matmul(np.ones([grid_h+1, 1]), np.expand_dims(np.linspace(0., float(width), grid_w+1), 0))
hh = np.matmul(np.expand_dims(np.linspace(0.0, float(height), grid_h+1), 1), np.ones([1, grid_w+1]))
ori_pt = np.concatenate((np.expand_dims(ww, 2), np.expand_dims(hh,2)), axis=2)
return ori_pt[np.newaxis, :] ###batchsize=1
def get_norm_mesh(mesh, height, width):
mesh_w = mesh[...,0]*2./float(width) - 1.
mesh_h = mesh[...,1]*2./float(height) - 1.
norm_mesh = np.stack([mesh_w, mesh_h], axis=3)
return norm_mesh.reshape((1, -1, 2))
class RecRecNet():
def __init__(self, modelpath):
self.net = cv2.dnn.readNet(modelpath)
self.grid_w, self.grid_h = 8, 8
self.input_width, self.input_height = 256, 256
self.output_names = self.net.getUnconnectedOutLayersNames()
self.rigid_mesh = get_rigid_mesh(self.input_height, self.input_width, self.grid_w, self.grid_h)
def detect(self, srcimg):
img = cv2.resize(srcimg, dsize=(self.input_width, self.input_height))
img = img.astype(np.float32) / 127.5 - 1.0
blob = cv2.dnn.blobFromImage(img)
self.net.setInput(blob)
offset = self.net.forward(self.output_names)[0]
mesh_motion = offset.reshape(self.grid_h+1, self.grid_w+1, 2)
ori_mesh = self.rigid_mesh + mesh_motion
norm_rigid_mesh = get_norm_mesh(self.rigid_mesh, self.input_height, self.input_width)
norm_ori_mesh = get_norm_mesh(ori_mesh, self.input_height, self.input_width)
output_tps = transformer(blob, norm_rigid_mesh, norm_ori_mesh, (self.input_height, self.input_width))
rectangling_np = ((output_tps[0]+1)*127.5).transpose(1,2,0)
input_np = ((blob[0]+1)*127.5).transpose(1,2,0)
ori_mesh_np = ori_mesh[0]
return rectangling_np.astype(np.uint8), input_np, ori_mesh_np
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--imgpath", type=str, default='testimgs/10.jpg')
args = parser.parse_args()
mynet = RecRecNet('model_deploy.onnx')
srcimg = cv2.imread(args.imgpath)
rectangling_np, input_np, ori_mesh_np = mynet.detect(srcimg)
# path = "rect.jpg"
# cv2.imwrite(path, rectangling_np)
input_with_mesh = draw_mesh_on_warp(input_np, ori_mesh_np, mynet.grid_w, mynet.grid_h)
# path = "mesh.jpg"
# cv2.imwrite(path, input_with_mesh)
cv2.namedWindow('srcimg', 0)
cv2.imshow('srcimg', srcimg)
cv2.namedWindow('rect', 0)
cv2.imshow('rect', rectangling_np)
cv2.namedWindow('mesh', 0)
cv2.imshow('mesh', input_with_mesh)
cv2.waitKey(0)
cv2.destroyAllWindows()
源码下载地址:https://download.youkuaiyun.com/download/matt45m/90362758?spm=1001.2014.3001.5503
论文解读
1. 引言
由于广角镜头比传统镜头具有更大的视野(FoV),它已广泛应用于计算成像、虚拟现实(VR)和自动驾驶等各种应用中。通过采用特定的映射,广角镜头可以产生凸起的非直线图像,而不是具有透视直线的图像。然而,这种映射机制违反了针孔相机假设,拍摄的图像会遭受严重的径向畸变。
为了消除广角镜头引起的畸变,人们提出了畸变校正算法。例如,传统方法使用校准目标(如棋盘格)和特定场景假设来校准广角镜头。近年来,深度学习为该领域带来了新的启发。它有助于基于学习到的语义特征自动校正广角图像中的径向畸变。为了追求更好的性能,最近的工作通过不同的特征、学习范式、校准表示和畸变先验等改进了学习框架。
我们注意到上述畸变校正方法主要集中在校正图像内容。通过将畸变图像向主中心收缩,所有像素的空间分布被重新排列,从而产生校正结果。然而,这种校正方式不可避免地会扭曲图像边界,使图像在视觉上呈现出较窄的视野和不规则的形状。此外,我们发现这种变形的边界会显著影响当前主流的视觉感知模型,因为它们大多是在矩形图像数据集上进行训练的。如图1所示,Mask R - CNN会被校正后的图像误导,导致在边界附近出现分割和检测结果缺失的情况(冲浪板被忽略)。虽然一些工作[28]使用外绘策略填充变形边界之外的空白区域,但生成的内容通常是虚构的,并且会扭曲原始的语义特征。
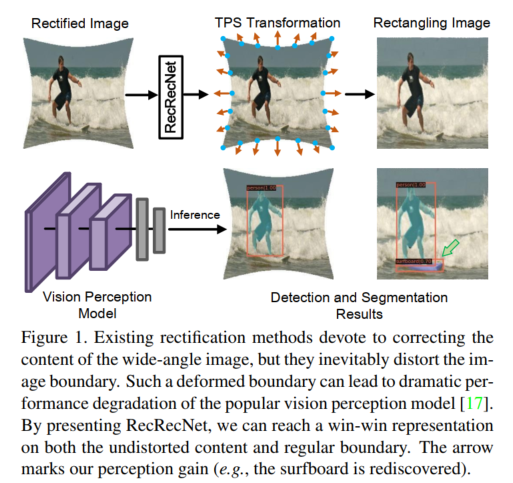
在这项工作中,我们探索一种在不引入任何额外语义信息的情况下,对广角图像在内容和边界上实现双赢的校正表示。对于这种新的表示,扭曲的内容得到校正,同时图像边界保持笔直,如图1所示。为此,我们提出了一种矩形校正网络(名为RecRecNet)。具体来说,我们提出了一个薄板样条(TPS)运动模块来构建用于校正广角图像的非线性和非刚性变换。它可以通过学习校正后图像上的控制点,灵活地将源结构扭曲到目标域。控制点分布在图像的整个区域,而图1仅显示了部分点以进行直观说明。
随后,我们设计了一种基于自由度的课程学习方法,进一步启发RecRecNet掌握渐进变形规则,减轻复杂结构逼近的负担,并为训练初始化一个更好的起点。课程学习的一般范式[3]为训练学习模型引入了一种启发式和有目的的策略。通过在课程的不同阶段逐步学习各种样本或知识,模型可以更快地收敛,这类似于人类和动物的学习方式。在这方面,我们将设计阶段/变换的自由度从相似变换(4自由度)增加到单应变换(8自由度)。此外,我们的课程过程揭示了图像边界从直线、斜线到曲线的简单到复杂的顺序。因此,我们的RecRecNet可以发现更多的几何细节,并在最终的矩形化阶段更快地收敛。
在追求双赢的校正表示的同时,我们还深入分析了为什么变形的边界会使感知变形,即为什么变形的图像边界会显著影响视觉感知模型。我们惊奇地发现,变形的边界会在原始特征图上引入新的特征,这进一步形成新的语义或导致非显著特征的盲点。并且我们证明了这种效应在其他研究领域中普遍存在。我们总结主要贡献如下:
- 我们提出了一种矩形校正网络(RecRecNet),用于校正后的广角图像的双赢表示。据我们所知,这在以前的文献中从未被研究过。
- 提出了一个薄板样条(TPS)运动模块,以灵活地构建非线性和非刚性的矩形化变换。我们还深入分析了为什么变形的图像边界会显著影响视觉感知模型。
- 为了掌握渐进变形规则并减轻复杂结构逼近的负担,设计了一种基于自由度的课程学习方法来启发我们的RecRecNet。
2、相关工作
2.1 畸变校正
广角镜头的畸变校正方法可分为传统方法和基于学习的方法。大多数传统技术集中于检测手工制作的特征[35, 24, 10, 2]。然而,这些技术由于诸如铅垂线和曲线等特定约束而经常失败。近年来,人们开始研究使用深度学习进行盲畸变校正。它可以在没有任何场景假设的情况下校正广角图像的径向畸变。例如,基于回归的方法[39, 4, 52, 34, 29]预测输入的畸变参数,然后使用估计的参数离线或在线校正畸变。基于重建的方法[30, 26, 51, 7]直接学习从畸变图像到校正输出的像素级映射或位移场。
尽管这些校正方法具有灵活性和效率,但在内容校正过程中不可避免地会扭曲图像边界。因此,边界处的扭曲分布会使视觉感知网络产生混淆并导致性能下降。一种直接的方法是将校正后的图像裁剪为矩形[15],然而,这会丢弃有信息的内容并违背广角镜头的初衷。
2.2 课程学习
课程学习技术已在机器学习中得到广泛应用。Elman等人提供了一个课程学习的概念框架,强调从低水平开始逐步学习到更具挑战性的情况的价值。Bengio等人首次将课程学习形式化为一种在训练过程中逐步提高数据样本复杂性的策略。随后,大多数研究人员遵循这一范式,并将课程学习应用于众多领域。特别是在计算机视觉中,课程学习已被研究用于启发图像分类、目标检测和语义分割等方面的学习网络。
在这项工作中,我们将课程学习应用于一个新任务。通过基于变换的自由度将矩形化校正分解为三个级别,所提出的课程可以启发我们的网络以从简单到复杂的顺序学习具有挑战性的变形,从而促进训练的更快收敛。
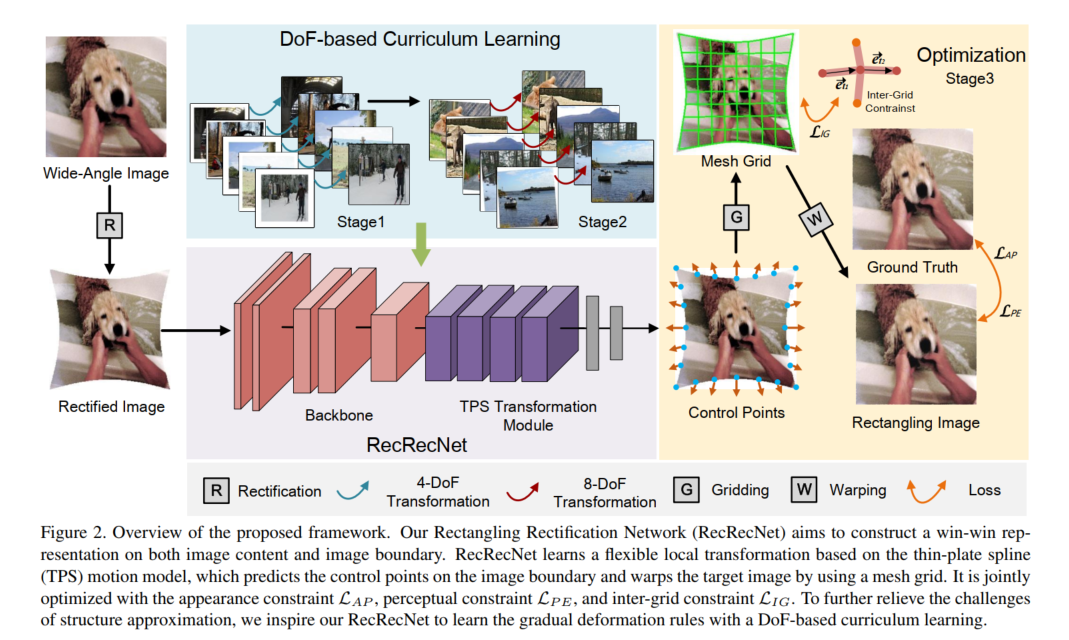
3、方法
3.1 问题表述
给定一个具有变形边界的校正后广角图像
I
R
e
c
∈
R
h
×
w
×
3
I_{Rec} \in \mathbb{R}^{h×w×3}
IRec∈Rh×w×3,我们的矩形校正网络(RecRecNet)旨在构建一个在图像内容和图像边界上的双赢表示,生成一个矩形校正图像
I
R
e
c
2
∈
R
h
×
w
×
3
I_{Rec^{2}} \in \mathbb{R}^{h×w×3}
IRec2∈Rh×w×3。图2展示了所提出框架的概述。更具体地说,矩形化模块以
I
R
e
c
I_{Rec}
IRec为输入,并基于薄板样条(TPS)运动模型学习一个灵活的局部变换
T
T
T。与先前的TPS工作相比,我们的方法旨在构建非线性和非刚性的矩形化变换。在弯曲图像边界上准确定位控制点是最大的挑战。通过外观约束和网格间约束,我们可以以端到端无监督的方式学习具有较少畸变的控制点。为了进一步缓解结构逼近的挑战,我们启发网络通过基于自由度的课程学习来学习渐进变形规则。
一般的多项式相机模型广泛用于近似广角图像的径向畸变。我们将镜头的投影方式与其畸变参数
K
=
[
k
1
,
k
2
,
k
3
,
⋯
]
K = [k_{1}, k_{2}, k_{3}, \cdots]
K=[k1,k2,k3,⋯]之间的关系表述如下:
r
(
θ
)
=
∑
i
=
1
N
k
i
θ
2
i
−
1
,
N
=
1
,
2
,
3
,
⋯
r(\theta)=\sum_{i = 1}^{N}k_{i}\theta^{2i - 1}, N = 1,2,3,\cdots
r(θ)=i=1∑Nkiθ2i−1,N=1,2,3,⋯
其中
r
r
r是主点与图像中像素之间的距离,
θ
\theta
θ表示光轴与入射光线之间的角度。这种投影会产生凸起的非直线图像,因此拍摄的图像会遭受严重的几何畸变。假设广角图像和校正图像中一个像素的坐标分别为
p
=
(
x
,
y
)
p=(x,y)
p=(x,y)和
p
r
e
c
=
(
x
r
e
c
,
y
r
e
c
)
p_{rec}=(x_{rec},y_{rec})
prec=(xrec,yrec),则校正解决方案可描述如下:
p
d
=
R
(
p
r
e
c
,
K
)
=
(
u
0
v
0
)
+
r
(
θ
)
p
r
e
c
∥
p
r
e
c
∥
2
p_{d}=\mathcal{R}(p_{rec},\mathcal{K})=\left(\begin{array}{c}u_{0}\\v_{0}\end{array}\right)+\frac{r(\theta)p_{rec}}{\left\|p_{rec}\right\|_{2}}
pd=R(prec,K)=(u0v0)+∥prec∥2r(θ)prec
其中
(
u
0
,
v
0
)
(u_{0},v_{0})
(u0,v0)表示主点。通过上述方程,可以使用双线性插值对广角图像进行校正。通过将广角图像向主中心收缩,所有像素的空间分布被重新排列,从而获得校正后的内容。然而,这种校正方式不可避免地会扭曲图像边界。
3.2 基于TPS变换的矩形化
如式2所示,广角图像的校正是一个非线性和非刚性的映射函数,不能用简单的变换表示。此外,用估计的参数构建一个准确的参数化模型来监督矩形化过程是具有挑战性的。从能量最小化的角度来看,我们可以通过用统一模型最小化变换能量来近似矩形化校正:
ε
=
ε
T
+
λ
ε
d
T
:
(
x
r
e
c
,
y
r
e
c
)
↦
(
x
r
e
c
2
,
y
r
e
c
2
)
\begin{gathered}\varepsilon=\varepsilon_{\mathcal{T}}+\lambda\varepsilon_{d}\\\mathcal{T}:(x_{rec},y_{rec})\mapsto(x_{rec^{2}},y_{rec^{2}})\end{gathered}
ε=εT+λεdT:(xrec,yrec)↦(xrec2,yrec2)
其中
ε
\varepsilon
ε表示期望变换的总能量。
(
x
r
e
c
,
y
r
e
c
)
∈
Ω
S
(x_{rec},y_{rec})\in\Omega_{S}
(xrec,yrec)∈ΩS和
(
x
r
e
c
2
,
y
r
e
c
2
)
∈
Ω
T
(x_{rec^{2}},y_{rec^{2}})\in\Omega_{T}
(xrec2,yrec2)∈ΩT分别表示源
S
S
S域和目标
T
T
T域中的点。
ε
T
\varepsilon_{T}
εT表示数据惩罚能量,
ε
d
\varepsilon_{d}
εd表示畸变能量。上述具有最低总能量的公式是期望的变换,其中超参数
λ
\lambda
λ用于平衡数据惩罚和畸变之间的能量。
特别地,我们提出利用TPS变换
T
′
T'
T′来最小化上述能量函数,这实现了端到端的无监督变形。由于TPS变换是灵活和非线性的,它可以表示更复杂的运动。给定对应图像中的两组控制点,它允许以最小的畸变从一个图像扭曲到另一个图像。假设
q
=
[
q
1
,
q
2
,
⋯
,
q
N
]
q = [q_{1},q_{2},\cdots,q_{N}]
q=[q1,q2,⋯,qN]和
q
′
=
[
q
1
′
,
q
2
′
,
⋯
,
q
N
′
]
q' = [q_{1}',q_{2}',\cdots,q_{N}']
q′=[q1′,q2′,⋯,qN′]是源点和目标点,数据项
ε
T
′
\varepsilon_{T'}
εT′可以通过控制点位移的差
∑
i
=
1
N
∥
T
′
(
q
i
)
−
q
i
′
∥
2
2
\sum_{i = 1}^{N}\left\|T'(q_{i}) - q_{i}'\right\|_{2}^{2}
∑i=1N∥T′(qi)−qi′∥22计算。在对齐控制点后,TPS通过以下方式找到具有最小畸变项
ε
d
\varepsilon_{d}
εd的最优插值变换:
min
∬
R
2
(
(
∂
2
T
′
∂
x
2
)
2
+
2
(
∂
2
T
′
∂
x
∂
y
)
2
+
(
∂
2
T
′
∂
y
2
)
2
)
d
x
d
y
\begin{array}{r}\min\iint_{\mathbb{R}^{2}}\left(\left(\frac{\partial^{2}\mathcal{T}'}{\partial x^{2}}\right)^{2}+2\left(\frac{\partial^{2}\mathcal{T}'}{\partial x\partial y}\right)^{2}\right.\\\left.+\left(\frac{\partial^{2}\mathcal{T}'}{\partial y^{2}}\right)^{2}\right)dxdy\end{array}
min∬R2((∂x2∂2T′)2+2(∂x∂y∂2T′)2+(∂y2∂2T′)2)dxdy
上述方程利用二阶导数来表述每个目标点的畸变偏差,并约束累积的全局最小值。然后我们可以得到一个由控制点参数化的空间变形函数如下:
T
′
(
q
)
=
A
[
q
1
]
+
∑
i
=
1
N
w
i
U
(
∥
q
i
′
−
q
∥
2
)
\mathcal{T}'(q)=A\left[\begin{array}{l}q\\1\end{array}\right]+\sum_{i = 1}^{N}w_{i}U(\left\|q_{i}'-q\right\|_{2})
T′(q)=A[q1]+i=1∑NwiU(∥qi′−q∥2)
其中
q
q
q是位于校正后广角图像上的点。
A
∈
R
2
×
3
A\in\mathbb{R}^{2×3}
A∈R2×3和
w
i
∈
R
2
×
1
w_{i}\in\mathbb{R}^{2×1}
wi∈R2×1是变换参数[5],可以通过最小化式3推导得出。此外,
U
(
r
)
U(r)
U(r)是一个径向基函数,表示控制点对
q
q
q的影响:
U
(
r
)
=
r
2
log
r
2
U(r)=r^{2}\log r^{2}
U(r)=r2logr2。
在RecRecNet中,我们定义 N = ( U + 1 ) × ( V + 1 ) N=(U + 1)\times(V + 1) N=(U+1)×(V+1)个控制点,这些控制点可以连接形成一个网格,网络学习预测校正后广角图像的网格。然后TPS将预测的网格变换到目标矩形图像上的规则网格,其中控制点在图像上均匀分布。
对于网络,我们首先选择ResNet50[18]作为RecRecNet的骨干网络来提取高级语义特征。假设输入校正图像的大小为 W × H W×H W×H,骨干网络的输出特征图大小为 W 16 × H 16 \frac{W}{16}×\frac{H}{16} 16W×16H。然后将这些特征图输入到一个运动头中,以预测校正图像上的 ( U + 1 ) × ( V + 1 ) (U + 1)\times(V + 1) (U+1)×(V+1)个控制点。堆叠4个核大小为3且带有批量归一化的卷积层来聚合高级特征,所有通道维度都设置为512。随后,使用3个全连接层,其单元数量分别为4096、2048、 ( U + 1 ) × ( V + 1 ) × 2 (U + 1)\times(V + 1)\times2 (U+1)×(V+1)×2,来预测所有控制点的坐标。
3.3 基于自由度的课程学习
如前所述,我们提出利用TPS变换通过一组控制点灵活地近似从校正图像到矩形化结果的运动。为了进一步缓解这种变换的挑战,我们用课程学习策略启发RecRecNet。
3.3.1 图像变换表述
图像变换包含不同的元素,如平移、缩放、旋转、剪切等。这些元素的任何组合都可以形成具有自由度(DoF)的新变换。一般来说,自由度是完全描述系统位移或变形位置的独立位移的集合。在二维图像上有一些经典的变换:平移变换(2自由度)、欧几里得/刚性变换(平移 + 旋转,3自由度)、相似变换(平移 + 旋转 + 缩放,4自由度)、仿射变换(平移 + 旋转 + 缩放 + 剪切,6自由度)和投影变换(平移、旋转、缩放各2个,以及无穷远线,8自由度)。
校正后广角图像与其矩形化图像之间的图像变换从未被研究和表述过。与畸变校正相比,由于图像边界更为重要,矩形化变换似乎是一种不对称的逆扭曲。为了直观地理解这种变换,我们可视化了校正后广角图像与其矩形化图像之间的像素位移场。具体来说,我们利用最先进的光流估计网络RAFT[44]来展示运动差异,并将其命名为矩形化流(校正图像 - 矩形化图像)。如图3所示,与校正流(广角图像 - 校正图像)相比,我们有以下观察结果:(1)矩形化流和校正流都呈现径向空间分布,其中四个主要方向朝着或背离四个图像角扩散。(2)矩形化流对于每个样本都有一个不固定的径向中心,这由图像的内容和布局决定。相反,校正流有一个相对固定的径向中心,这与广角图像中径向畸变之前的几何形状有关。
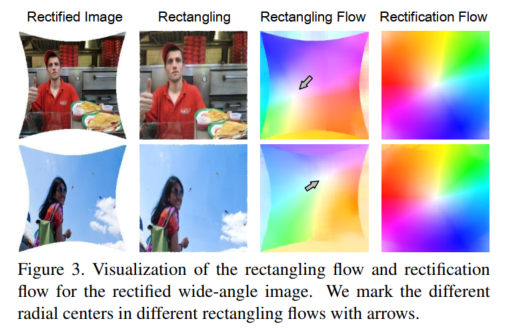
因此,我们可以得出结论,图像内容高度决定了矩形化流的分布。用经典的图像变换及其组合来表示这种变换是困难的。然而,这种非线性和非刚性变换可以局部地分解为不同的变换元素,如平移、缩放和剪切。启发网络学习一些基本变换并逐渐过渡到更具挑战性的情况将是有意义的。
3.3.2 课程选择
为了为矩形化任务选择有效的课程,我们应该遵循两个原则:第一,课程中的所有阶段都与目标有密切相关的知识。第二,课程中的阶段本质上提供了从简单到复杂的顺序。为此,我们设计了一种基于自由度的课程来启发RecRecNet,其中我们将设计的变换的自由度从相似变换(4自由度)增加到单应变换(8自由度),最终到矩形化变换。
我们认为所提出的课程有以下优点:(1)如3.3.1节所述,自由度直接表示图像变换的难度。随着自由度的增加,变换显示出更复杂的全局映射和多样的运动。因此,RecRecNet可以学习渐进变形规则。(2)对于局部几何形状,即图像边界的形状,我们的课程显示出从直线、斜线到曲线的渐进转变。这种设计可以提高TPS变换中控制点的定位能力,并使RecRecNet具有边界感知能力。更多细节和实验将在4.4节中展示。
3.4 训练损失
外观损失:我们在像素级别约束矩形化图像 I R e c 2 I_{Rec^{2}} IRec2接近真实值 I G T I_{GT} IGT。外观损失 L A P L_{AP} LAP可以通过 I R e c 2 I_{Rec^{2}} IRec2和 I G T I_{GT} IGT的 c 1 c_{1} c1范数差来计算。
感知损失:我们在高级语义感知中最小化
I
R
e
c
2
I_{Rec^{2}}
IRec2和
I
G
T
I_{GT}
IGT的
c
2
c_{2}
c2距离,以保证矩形化结果在感知上自然:
L
P
E
=
1
W
i
,
j
H
i
,
j
∑
x
=
1
W
i
,
j
∑
y
=
1
H
i
,
j
∥
ϕ
i
,
j
(
I
R
e
c
2
x
,
y
)
−
ϕ
i
,
j
(
I
G
T
x
,
y
)
∥
2
\mathcal{L}_{PE}=\frac{1}{W_{i,j}H_{i,j}}\sum_{x = 1}^{W_{i,j}}\sum_{y = 1}^{H_{i,j}}\left\|\phi_{i,j}(I_{Rec^{2}}^{x,y})-\phi_{i,j}(I_{GT}^{x,y})\right\|_{2}
LPE=Wi,jHi,j1x=1∑Wi,jy=1∑Hi,j
ϕi,j(IRec2x,y)−ϕi,j(IGTx,y)
2
其中,在从VGG19网络的第
i
i
i个最大池化层之前的第3个卷积(激活后)得到的特征图
ϕ
i
,
j
\phi_{i,j}
ϕi,j上最小化矩形化校正图像和真实值的差异。
网格间损失:为了避免矩形化后内容失真,预测的网格不应有太大变形。因此,我们设计了一个网格间项
L
I
G
L_{IG}
LIG来约束预测网格的形状,这促使相邻网格一致变换。连续变形网格
e
⃗
t
1
,
e
⃗
t
2
\vec{e}_{t1},\vec{e}_{t2}
et1,et2的边缘被监督为共线,如下所示:
L
I
G
=
1
M
∑
{
e
⃗
t
1
,
e
⃗
t
2
}
∈
m
s
(
1
−
⟨
e
⃗
t
1
,
e
⃗
t
2
⟩
∥
e
⃗
t
1
∥
⋅
∥
e
⃗
t
2
∥
)
\mathcal{L}_{IG}=\frac{1}{M}\sum_{\{\vec{e}_{t1},\vec{e}_{t2}\}\in m_{s}}(1-\frac{\langle\vec{e}_{t1},\vec{e}_{t2}\rangle}{\|\vec{e}_{t1}\|\cdot\|\vec{e}_{t2}\|})
LIG=M1{et1,et2}∈ms∑(1−∥et1∥⋅∥et2∥⟨et1,et2⟩)
其中(M)是网格(m_{s})中连续两条边的元组数量。当最大化上述余弦表示(即值等于1)时,相应的两条边共线,此时损失最小且图像内容一致。
总体训练损失可通过下式获得:
L
=
λ
A
P
L
A
P
+
λ
P
E
L
P
E
+
λ
I
G
L
I
G
\mathcal{L}=\lambda_{AP}\mathcal{L}_{AP}+\lambda_{PE}\mathcal{L}_{PE}+\lambda_{IG}\mathcal{L}_{IG}
L=λAPLAP+λPELPE+λIGLIG
其中
λ
A
P
\lambda_{AP}
λAP、
λ
P
E
\lambda_{PE}
λPE和
λ
I
G
\lambda_{IG}
λIG是平衡外观损失、感知损失和网格间损失的权重,经验上分别设置为
1
1
1、
1
e
−
4
1e^{-4}
1e−4和1。
4、实验
4.1 实现细节
数据集建立:遵循现有方法,我们首先使用基于公式(1)的四阶多项式模型合成广角图像。然后根据公式(2)对广角图像进行畸变校正。由于非线性和非刚性特性,为校正后的图像形成准确的变换模型进行矩形化是困难的。我们注意到计算机图形学中有一个经典的全景图像矩形化工作由He等人完成。它通过优化具有保线网格变形的能量函数使拼接图像规则化。因此,我们对校正后的图像执行相同的能量函数以适应我们的任务。然而,He等人[16]中保线结构的能力受限于线检测。因此,一些矩形化图像有不可忽略的畸变。为了克服这个问题,我们仔细筛选所有结果并重复选择过程三次,从30,000张源图像中得到5,160个训练数据,从2,000张源图像中得到500个测试数据。每次手动操作大约需要10秒。关于数据集的更多细节在补充材料中报告。我们希望发布数据集以促进相关领域的发展。
实验配置:我们使用Adam[23]以初始值为(10^{-4})的指数衰减学习率训练RecRecNet。批次大小设置为16,总轮数设置为260。特别地,RecRecNet根据提出的基于自由度的课程进行3个阶段的训练。4 - DoF课程、8 - DoF课程和最终矩形化课程的训练轮数经验上分别划分为30、50和180。
4.2 矩形化校正结果
RecRecNet是首次尝试对校正后的广角图像进行矩形化。我们将我们的方法与经典的图像矩形化工作He等人[16]和最先进的校正图像外绘工作[28]进行比较。在第一次比较(图4)中,我们根据图像特征将测试数据集分为复杂场景和简单场景。我们还展示了直接丢弃变形边界周围内容的裁剪结果,这在以前的工作中很常见。实验结果表明,虽然RecRecNet是基于He等人[16]的筛选标签进行训练的,但它可以学习到更高的性能上限并推广到更多样化的场景。相比之下,由于保线规则,He等人[16]无法对布局复杂或背景单调的场景进行矩形化。在第二次比较(图5)中,我们可以观察到ROP[28]通过外推图像内容使校正图像的变形边界规则化。但生成的结果通常是虚构的并且扭曲了原始语义特征,在边界附近出现语义断裂的不良情况。我们的RecRecNet在不引入新的模糊内容的情况下,使用灵活的TPS变换为校正图像构建了双赢的表示,显示出与矩形化标签最接近的外观。此外,图6显示RecRecNet可以极大地帮助下游视觉任务。


| 度量 | 裁剪 | 填充 | ROP [28] | He [16] | 我们的方法 |
|---|---|---|---|---|---|
| PSNR↑ | 11.51 | 12.07 | 13.90 | 15.36 | 18.68 |
| SSIM↑ | 0.1907 | 0.2775 | 0.3516 | 0.4211 | 0.5450 |
| AP→ | 21.8 | 23.9 | 30.8 | 34.7 | 41.3 |
| mloU→ | 18.6 | 20.1 | 26.1 | 30.2 | 37.8 |
此外,我们从两个方面基于定量评估比较了不同的方法。对于矩形化结果,选择峰值信噪比(PSNR)和结构相似性(SSIM)来衡量图像质量。对于视觉任务,我们利用平均精度(AP)和平均交并比(mIoU)来评估视觉模型[17]的检测和分割性能。比较结果列于表1中,其中我们使用镜像填充作为填充方法来简单填充变形边界之外的空白区域。正如我们所观察到的,评估结果显示RecRecNet在低级视觉重建和高级语义恢复方面都具有优越性。
4.3 为什么变形边界会使感知变形
虽然我们的任务是对校正后的图像进行矩形化,但我们仍然对视觉感知模型性能下降背后的原因感到好奇。在这部分中,我们对这种效应进行了深入分析。首先,我们阐述了感知模型的两个典型失败案例:错误感知和缺失感知。具体来说,我们关注Mask R - CNN[17]的检测性能,并在图6和图7中可视化了一些样本。我们可以观察到模型无法检测到物体,尤其是位于边界附近的物体。通过校正变形的边界,感知性能出人意料地得到了恢复。


在实验中,我们发现变形的边界会在特征图上引入新的特征,这(i)形成新的语义(导致错误感知)或(ii)导致原始特征的盲点(导致缺失感知)。特别是在图7中,我们展示了具有ResNet101骨干网络的Mask R - CNN从浅层到深层的特征图。在最外层边界和变形边界分别可以观察到明显的线伪影和曲线伪影。特别是,线伪影本质上是由零填充产生的。当卷积核在零填充的边界处提取特征时,零值和原始内容之间的急剧过渡会被错误地识别为边缘。类似地,这种边缘效应也可以由校正图像的变形边界引起。随着卷积层的增加,这种效应逐渐扩大并在特征图上构建新的特征。
对于错误感知的情况,网络错误地将边界及其周围区域识别为冲浪板。由于边缘效应在浅层特征图上引入了新的特征,并在深层特征图中形成了新的语义。更多结果在补充材料中报告。此外,变形的边界不仅存在于校正后的图像中,也存在于其他研究领域,如图像扭曲、图像拼接和卷帘快门校正。因此,边缘扩展效应可以在特征图上引入新的特征,并进一步影响下游感知性能。
4.4 消融研究
控制点:如表2和图8所示,实验表明更多的控制点可以促进RecRecNet对变形边界的结构逼近和定位能力。在所有评估指标上,(9×9)的大小取得了最佳性能。

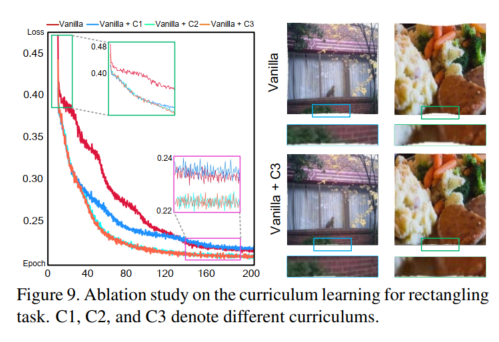
课程学习:我们将没有课程的RecRecNet定义为Vanilla,并将具有不同课程的RecRecNet定义为:2 - DoF - 4 - DoF为Vanilla + C1,2 - DoF - 8 - DoF为Vanilla + C2,4 - DoF - 8 - DoF为Vanilla + C3。在图9(左)中,训练损失曲线表明课程学习可以为训练提供更好的初始点,并在矩形化任务上更快收敛。Vanilla训练大约需要多40个轮次才能收敛到与课程设置相似的训练性能,并且容易在验证数据上过拟合。此外,合理设计课程(如Vanilla + C3)有助于提高RecRecNet的边界感知能力,增强结构恢复性能,如图9(右)所示。


4.5 跨域评估
为了评估泛化能力,我们从最先进的校正方法收集了300个校正后的广角图像结果。它们的结果来自各种类型的数据集和真实世界的广角镜头,如Rokinon 8mm Cine Lens、Opteka 6.5mm Lens和GoPro。这些镜头通常用于获取全景图像。图10显示RecRecNet在仅使用一种相机模型的合成图像数据集进行训练的情况下,可以很好地推广到其他领域和不同的校正结构。我们还展示了一些比较结果,如图11所示,在以前的方法中可以观察到语义断裂和物体扭曲的情况。
结论
在这项工作中,我们考虑了广角图像的一种新的矩形化校正任务。虽然在以前的文献中从未研究过,但我们证明了普遍存在的校正后广角图像的变形边界会显著影响视觉感知模型。为了解决这个问题,我们提出为校正后的广角图像构建一种双赢的表示,并设计了一种新颖的RecRecNet。配备灵活的TPS变换运动模型,RecRecNet可以以无监督的端到端方式构建从变形边界到直线边界的局部变形。此外,我们启发RecRecNet通过基于自由度的课程学习来学习渐进变形规则,这可以缓解非线性和非刚性变换的复杂性。此外,我们提供了详细的分析来解释为什么变形的图像边界会使当前的视觉感知变形。在未来的工作中,我们计划扩展到一个通用的范式,用于校正任何变形图像,并进一步研究图像边界和视觉感知性能之间的关系。此外,将我们的矩形化算法嵌入到视觉模型训练的在线数据增强中也将是有趣的。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











