




概述
高精度点云异常检测是识别先进加工和精密制造缺陷的黄金标准。尽管该领域在方法上取得了一些进展,但数据集的稀缺和缺乏系统的基准阻碍了其发展。我们引入了 Real3D-AD,这是一个具有挑战性的高精度点云异常检测数据集,旨在解决该领域的局限性。Real3D-AD 包含 1254 个高分辨率 3D 物品(每个物品的点数从四万到数百万不等),是迄今为止用于高精度 3D 工业异常检测的最大数据集。在点云分辨率(0.0010mm - 0.0015mm)、360 度覆盖和完美原型方面,Real3D-AD 超越了现有的 3D 异常检测数据集。此外,我们为 Real3D-AD 提供了一个全面的基准,揭示了高精度点云异常检测缺乏基线方法的问题。为了解决这个问题,我们提出了 Reg3D-AD,这是一种基于配准的 3D 异常检测方法,结合了一个新的特征记忆库,可保留局部和全局表示。在 Real3D-AD 数据集上进行的大量实验突出了 Reg3D-AD 的有效性。为了便于重现和获取,我们在网站 https://github.com/M-3LAB/Real3D-AD 上提供了 Real3D-AD 数据集、基准源代码和 Reg3D-AD。
论文:Real3D-AD: A Dataset of Point Cloud Anomaly Detection
1. 引言
1.1 Real3D-AD 的动机:3D > 2.5D
非常有必要提出一个高分辨率点云异常检测数据集,以填补学术界和工业界之间的差距,将点云异常检测能力应用到工厂生产中。点云异常检测在现实世界的生产线中广泛应用。然而,学术界发布的 3D 异常检测数据集是 RGBD(2.5D),这不符合工业制造的需求。先进的加工和精密制造要求在整个检测过程中无盲点。但是,由于 RGBD 数据集是通过单视图扫描获得的,所以存在盲点。缺乏真实的点云异常检测数据集阻碍了 3D 异常检测的进一步发展。因此,提出一个满足工业制造需求的点云异常检测数据集至关重要且迫在眉睫。
1.2 当前 3D-AD 数据集的局限性和 Real3D-AD 的优势
为了解决这个问题,我们提出了一个大规模、高分辨率的 3D 异常检测数据集 Real3D-AD,以支持 3D 异常检测方法的研究和开发。虽然已经提出了两个 3D 异常检测数据集(MVTec 3D-AD [20]和 Eyescandies [3]),但仍然存在一些局限性:
- MVTec 3D-AD 的精度不足以满足高精度点云异常检测的要求。具体来说,MVTec 3D-AD 每个对象提供的点云数量有限,为 4147 个,点精度为 0.11mm。与 MVTec 3D-AD 相比,Real3D-AD 每个对象的点云数量要多得多,估计为 130 万个,大约是其 100 倍。此外,Real3D-AD 的点精度高达 0.010mm,比 MVTec 3D-AD 先进 10 倍。
- 如果采用 RGBD 相机收集 3D 数据,如 MVTec 3D 和 Eyescandies,3D 异常检测数据集存在盲点。仅依靠单视图进行检测时,识别缺陷可能具有挑战性。Real3D-AD 是使用高分辨率激光扫描收集的,非常适合全方位检测产品缺陷,如图 1 所示。

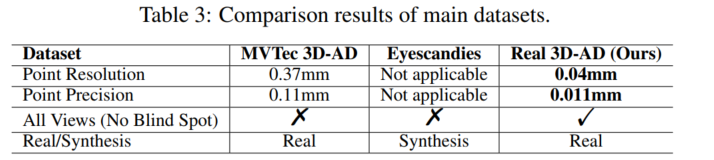
- 模拟数据集(Eyescandies)难以扩展到现实场景。由于真实产品的商业隐私,很难收集真实世界产品的 CAD 模型。因此,大多数研究人员采用模拟软件,如 Blender 框架 [9]。然而,合成纹理和异常细节都不能高保真地实现。Real3D-AD 从实际应用中收集产品,并通过高分辨率 3D 扫描仪获得出色的原型。因此,如表 3 所示,我们可以得出结论,Real3D-AD 相对于先前的 3D 异常检测数据集工作有三个关键特征:高精度、无盲点和逼真的高精度原型。
1.3 基准和基线
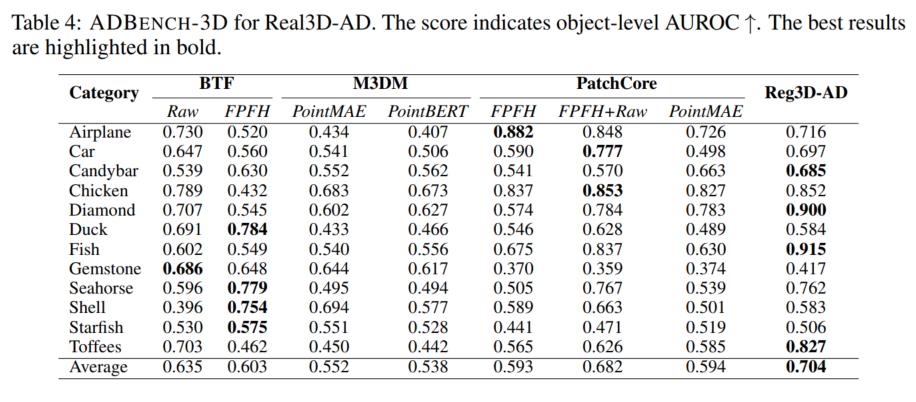
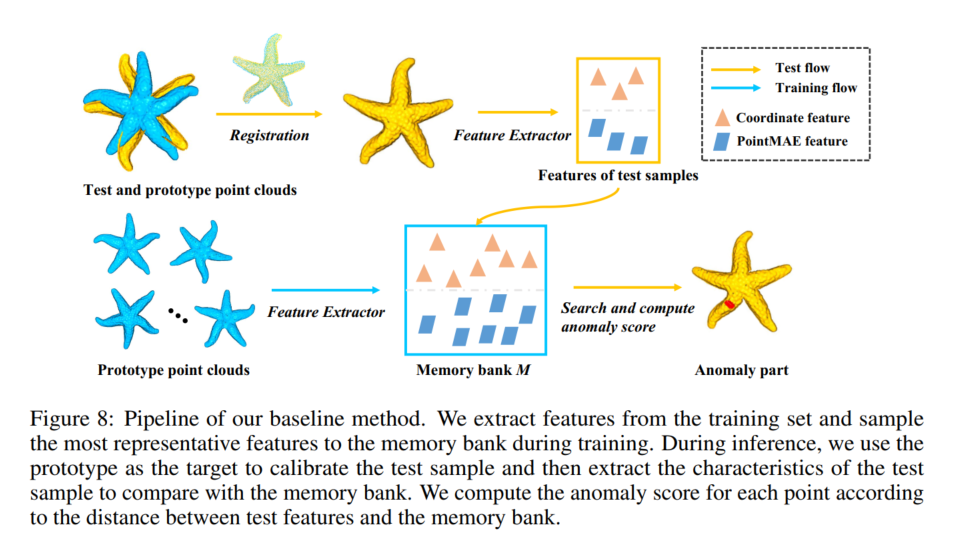
为了加速开发通用高精度点云异常检测方法的研究工作,我们构建了一个全面且结构化的大规模基准,称为 ADBENCH-3D。此外,我们开发了一种基于配准的基线方法,符合高分辨率 3D 异常检测的先决条件。由于实际限制,每个类别的可用训练数据集数量有限(小于或等于 4 个),因为为每个类别创建高精度原型是一个耗时的过程(每个类别最多需要两天)。ADBENCH-3D 的配置与 3D 领域的当代无监督异常检测任务不同。第 4.1 节提供了设置的全面描述。具体来说,训练示例有限(≤ 4),测试样本仅从一侧扫描。这样做的动机是模拟现实世界的应用:生产线上的扫描位置是固定的,一个位置只能扫描产品一侧的结果。此外,为了便于在社区内进行精确的性能比较并保证可重复性,ADBENCH-3D 框架包含一个全面的端到端管道,包括数据预处理、3D-AD 算法、评估脚本、指标和可视化工具包。ADBENCH-3D 包含一组 8 种基本的 3D 异常检测方法,这些方法已在 Real3D-AD 数据集上实现和测试。此外,表 4 中的结果表明,大多数当前的 3D-AD 技术在 Real3D-AD 中无法获得令人满意的性能,其对象级 AUROC 分数低于 50%就证明了这一点。因此,我们提出了一种基于配准的 3D-AD 方法(Reg3D-AD),作为一种通用解决方案,以满足 Real3D-AD 数据集的要求。Reg3D-AD 模型引入了一个新的特征记忆库,如图 8 所示,旨在保留局部和全局特征。在推理过程中,测试对象与训练原型对齐,并提取其局部和全局特征。通过评估测试对象特征与训练原型之间的距离来识别缺陷。因此,Real3D-AD 和 ADBENCH-3D 朝着统一 3D 异常检测研究中的分散努力迈出了一步,并为更深入地理解 3D 异常检测模型铺平了道路。
本文的主要贡献如下:
- 创建了有史以来第一个高分辨率 3D 异常检测数据集(Real3D-AD),使得设计高分辨率 3D 异常检测算法并将其公开应用成为可能。Real3D-AD 具有三个主要属性,使其与先前的 3D 异常检测数据集研究区分开来。这些属性包括高精度、无盲点和逼真的高精度原型。
- ADBENCH-3D 提供的端到端管道包括数据准备、数据分割、评估指标和脚本以及可视化工具包。ADBENCH-3D 进行了大规模的系统评估(在 Real3D-AD 上评估 8 种主要算法)。
- 提出了一种通用的基于配准的 3D 异常检测方法(Reg3D-AD)。通过在 Real3D-AD 数据集上进行的全面实验证明了 Reg3D-AD 的有效性,其性能明显优于次优方法。
2. 相关工作
2.1 3D-AD 数据集
2D 异常检测(2D-AD)的数据集很丰富,其历史可以追溯到 2007 年 [29]。有超过 20 个不同的 2D-AD 数据集 [11, 25, 17, 31]。众多的 2D-AD 数据集催生了许多相关工作。一些研究从图像重建 [35, 8]、特征蒸馏 [12, 4, 27] 和特征比较 [22] 等角度进行研究。还有一些研究专注于特定场景,如少样本异常检测 [30, 36, 7] 和噪声异常检测 [16]。相比之下,3D 异常检测(3D-AD)的数据集数量相当有限。第一个 3D-AD 数据集于 2021 年推出,目前只有两个 3D-AD 数据集,即 MVTec 3D-AD 数据集 [20] 和 Eyecandies 数据集 [3]。MVTec 3D-AD [20] 是一个专为 3D 点云异常检测设计的新数据集,也是唯一的点云 AD 数据集。它包含 2656 对图像作为训练集,294 对图像作为验证集,249 对正常图像和 948 对异常图像组成测试集。该数据集共有 41 种不同类型的异常,异常区域总数为 1148 个。每对图像由 RGB 图像和表示每个像素空间坐标的 tiff 图像组成。图像分辨率从 400×400 到 900×900 不等。Eyecandies 数据集 [3] 是一个在受控环境中渲染的包含十种不同类别糖果的新型合成数据集。它由 13250 对正常样本和 2250 对异常样本组成。每个深度图像对应六个不同光照条件下的 RGB 图像。MVTec 3D-AD 和 Eyecandies 都是 RGBD 数据集,仅限于单视图信息。为了进一步探索空间信息在 AD 任务中的价值,我们提出了 Real3D-AD 数据集,它将对象信息扩展到 3D 空间。Real3D-AD 训练集中的原型包含来自各个视图的全面对象信息。测试集也包括对象的多视图信息,从而可以更广泛地探索 3D 信息在 AD 任务中的价值。
2.2 3D-AD 方法
最近,在 2D-AD 领域出现了许多高质量的论文 [33, 37, 32, 26]。MVTec 3D-AD 的发布也引发了人们对 3D-AD 异常检测方法的兴趣 [15, 23, 5, 28, 8]。然而,与 2D 异常检测相比,仍需要更多关于 3D 的研究。一些方法仅使用深度信息来去除背景噪声,这限制了深度信息的使用。同时,在不影响性能的情况下结合 RGB 和深度信息仍然是一个挑战。Bergmann 等人 [1] 提出了一种基于师生模型的点云特征提取网络。在训练过程中,学生网络和教师网络保持一致的特征,并在测试时利用提取特征的差异来定位异常。Horwitz 等人 [15] 将手工制作的 3D 描述符与经典的 AD 方法 KNN 框架相结合。虽然这两种方法都有效,但它们的性能较差。AST [23] 在 MVTec 3D-AD 中表现良好,但仅使用深度信息去除背景。AST 仍然使用 2D-AD 方法来检测异常,忽略了对象的深度信息。M3DM [28] 分别从点云和 RGB 图像中提取特征并将它们融合以做出更好的决策。这种方法优于 BTF,但严重依赖预训练的大型模型和内存库。CPMF [6] 也使用 KNN 范式。然而,它从不同角度将点云投影到二维图像中,显著降低了特征提取的复杂性和计算成本,并融合所得信息进行检测。总之,现有的 3D-AD 模型要么性能较差,要么严重依赖预训练模型和内存库。目前,缺乏使用点云信息的异常检测方法,该领域可用的研究数据集只有带有深度信息的 MVTec 3D-AD 和人工合成的 Eyescandies [3] 数据集。为了引起人们对该领域的关注和研究,我们引入了 Real3D-AD 数据集。
3. Real3D-AD 数据集
3.1 数据收集
我们概述了生成 Real3D-AD 数据集的流程,包括高分辨率扫描仪的描述、原型的构建、异常的生成以及该过程所需劳动力和时间的评估。
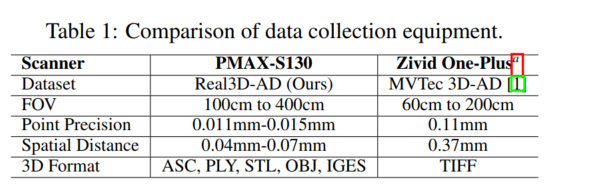
3.1.1 高分辨率高精度 3D 扫描仪描述
为了获得精确的 3D 异常检测数据,我们使用了一种名为 PMAX-S130 的高分辨率双目 3D 扫描仪,如图 2 所示。PMAX-S130 光学系统由一对低畸变镜头、一个高亮度 LED 和一个蓝光滤镜组成。蓝光扫描仪的镜头滤镜只允许特定波长的蓝光通过。由于蓝光在自然和人工照明中的浓度相对较低,该滤镜有效地过滤了大部分蓝光。然而,使用发蓝光的光源在这种情况下可能会带来独特的障碍。图像传感器可以通过镜头光圈收集光线。因此,环境光的影响大大降低。该设备能够在车间环境中常见的复杂照明条件下进行扫描操作。上述目标是通过采用高亮度 LED 冷光源实现的。这种方法延长了设备的使用寿命,减少了热量排放,同时确保了一致的扫描精度。此外,通过集成一个低畸变镜头提高了设备的扫描精度。表 1 中的数据表明,PMAX-S130 比 MVTec 3D-AD 使用的 Zivid 相机性能更好,特别是在点精度方面。Real3D-AD 的每个点云的点精度和空间距离比 MVTec 3D-AD 分别高 10 倍和 4.28 倍。因此,Real3D-AD 为增强高精度点云异常检测的理解提供了途径。
3.1.2 原型构建
原型构建过程如图 3 所示。首先,静止的物体在转盘完成 360°旋转时进行扫描,使扫描仪能够捕捉物体各个面的图像。随后,将物体翻转,并重复旋转和扫描过程。在对前后扫描结果进行手动校准后,算法对拼接过程进行精确校准。如果结果中有间隙,则重复扫描拼接过程,直到生成点云。

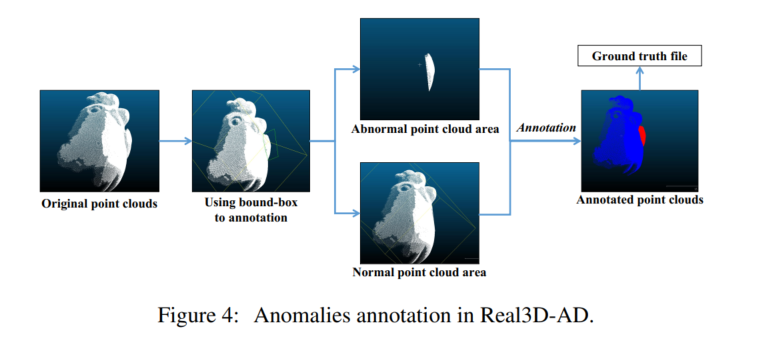
3.1.3 异常类型和标注
点云的异常可分为两类:不完整性和冗余。我们使用 CloudCompare(2016)[10] 来标注点云数据。标注过程如图 4 所示。第一步是将 pcd 文件导入 CloudCompare 软件,并修改视角和点云文件大小。然后,将异常和非异常区域分离,并为每个点云分配相应的标签。最终结果以文本文件呈现。

3.1.4 劳动力和时间消耗
收集和标注3D数据集的过程需要大量劳动力。每个原型构建需要一个三人团队花费 1.2 天完成。第一个人负责进行扫描,第二个人负责手动校准,第三个人主要负责标注任务。为了生成异常,需要一个四人团队来完成任务。第一个人关注点云异常的不足,第二个人负责点云异常的多余部分,第三个人主要负责标注异常。每个异常样本需要 5 小时完成。由于工作量巨大,Real3D-AD 数据集需要一个七人团队花费四个月的时间完成。
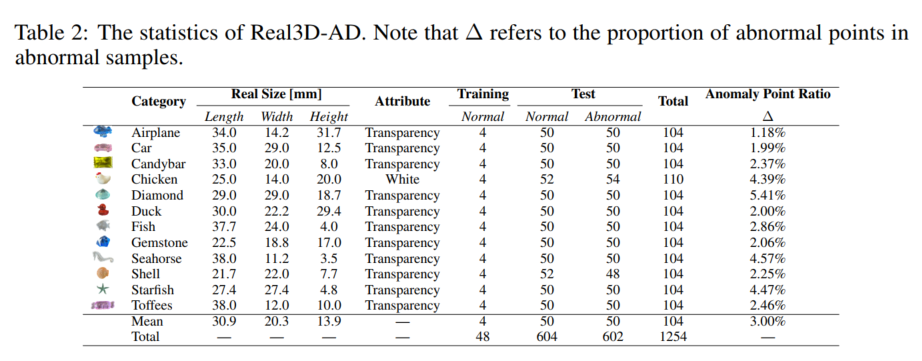
3.2 数据统计
Real3D-AD 数据集的统计信息如表 2 所示。该表包括数据集类别、训练原型数量、测试数据集中正常和异常样本数量、测试中异常点的平均比例。Real3D-AD 总共包含 1254 个样本,分布在 12 个不同的类别中。每个特定类别的训练集仅包含四个样本,类似于 2D 异常检测中的少样本场景。这些类别包括但不限于飞机、糖果棒、鸡、钻石、鸭、鱼、宝石、海马、贝壳、海星和太妃糖。所有这些类别都是来自生产线的玩具。表 2 中的数据表明,低异常点比例给异常检测带来了挑战。该类别中的大多数属性与透明度有关,这表明 Real3D-AD 数据集非常适合点云异常检测任务。
此外,箱线图表示了 Real3D-AD 数据集中所有样本的数据点分布,如图 6 所示。从图 6 中可以得出两个推断。点云内不同物品类别之间的点数变异性观察到的差异显示出显著的不同。具体来说,**训练样本提供了 3D 对象的完整原型,而测试样本仅从一侧扫描。**因此,训练样本的数量远多于测试样本。其次,可以观察到在每个测试集中,正常样本和异常样本之间的点值差异相对较小。
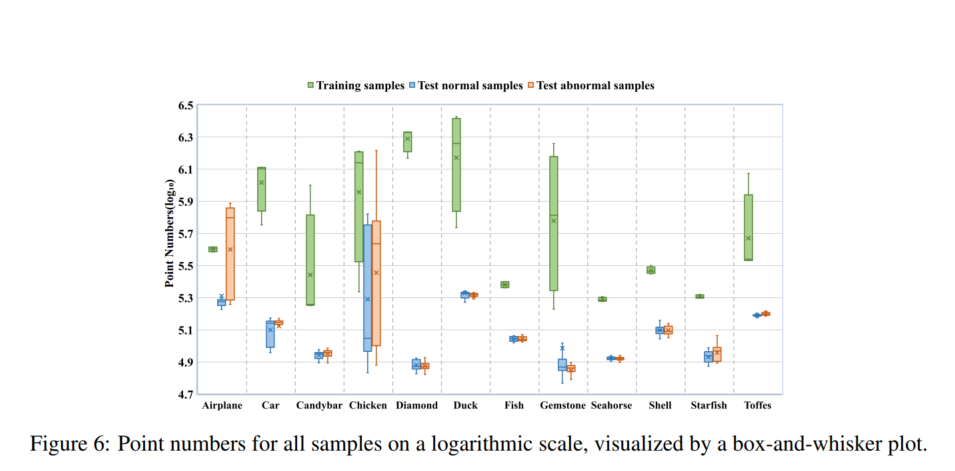
3.3 Real3D-AD 与其他数据集
表 3 中的结果表明,Real3D-AD 与 MVTec 3D-AD [20] 和 Eyescandies [3] 相比具有优越的性能,特别是在点分辨率、点精度、无盲点和数据集真实性方面。Real3D-AD 的点分辨率和精度分别为 0.04mm 和 0.011mm,分别比 MVTec 3D-AD 高 4.2分别比 MVTec 3D - AD 高 4.28 倍和 9 倍。此外,Real3D - AD 系统受益于多视图扫描,消除了任何潜在的盲点,从而提高了其异常检测能力。因此,Real3D - AD 被认为更适合在点云异常检测中实现高精度,并能满足工业制造要求。
4. 基准和基线
4.1 问题定义和挑战
- 问题定义:ADBENCH - 3D 设置可以正式表述如下。给定一组训练示例 T = { t i } i = 1 N T = \{t_{i}\}_{i = 1}^{N} T={ti}i=1N,其中 { t 1 , t 2 , ⋯ , t N } \{t_{1}, t_{2}, \cdots, t_{N}\} {t1,t2,⋯,tN} 是训练原型。在 Real3D - AD 中,每个类别的原型数量是有限的( ≤ 4 \leq4 ≤4)。此外, T n T_{n} Tn 属于某个类别 c j ∈ C c_{j} \in C cj∈C,其中 C C C 表示所有类别的集合。在测试时,给定来自目标类别 c j c_{j} cj 的正常或异常样本,AD 模型应预测测试 3D 对象是否异常,如果预测结果为异常,则定位异常区域。
- 训练和测试样本可视化:图 7 展示了训练原型和测试数据集。蓝色框中标注为 (a)-(d) 的图像代表原型。**训练原型经过 360°扫描,确保不存在视野受限的区域。**橙色框中 (e)-(h) 的图像代表测试样本。为了模拟现实世界的条件,测试样本仅从一侧扫描。因为我们希望遵循现实世界的应用:生产线中的工人或质量检测设备随机检查产品的一侧,通过将扫描数据与原型匹配来识别缺陷。

- 挑战:存在以下三个挑战。(1) 每个类别的训练数据集仅包含正常原型,即没有对象或点级别的注释。(2) 训练集的正常原型数量很少。在 ADBENCH - 3D 的设置中,训练原型少于四个。(3) 测试集和训练集样本之间存在不可避免的差异,需要解决。
4.2 ADBENCH - 3D
- 指标:我们使用专为 3D 异常检测设计的指标进行标准化评估,包括受试者工作特征曲线下面积(AUROC)和精确率 - 召回率曲线下面积(AUPR/AP)。指标的详细信息在补充材料中介绍。
- 方法:如第 2 节所述,3D 异常检测方法主要关注 RGBD 异常检测,而不是点异常检测任务。因此,我们采用 BTF [15] 和 M3DM [28] 作为我们的基准方法。我们为提出的 Real3D - AD 数据集构建了一个系统的基准 ADBENCH - 3D,如表 4 所示。在表 4 中,BTF(Raw) 表示我们仅将坐标特征(xyz)纳入 BTF 管道。BTF(FPFH) 表示我们将快速点特征直方图(FPFH)[24] 纳入 BTF 管道。M3DM(PointMAE) 表示 M3DM 使用 PointMAE [19] 作为点云特征提取器并忽略 RGB 分支。M3DM(PointBERT) 表示 M3DM 使用 PointBert [34] 作为点云特征提取器并忽略 RGB 分支。PatchCore + FPFH 表示我们用 FPFH 特征提取器替换 ResNet [14] 并将其合并到 PathCore [21] 中。PatchCore + FPFH + Raw 表示我们使用 FPFH 和每个点云特征的坐标,并将它们注入 PatchCore 管道。PatchCore + PointMAE 表示我们采用 PointMAE 特征提取器并将特征合并到 PatchCore 架构中。
- 工具包:为了补充 ADBENCH - 3D,我们发布了一个全面的工具包作为高精度点云异常检测的起始代码,它实现了以下 8 种核心方法:(1) 数据预处理,(2) 评估脚本和指标,以及 (3) 可视化工具包。
4.3 Reg3D - AD
受 PatchCore [22] 的启发,我们开发了一种通用的基于配准的点云异常检测方法(Reg3D - AD),如图 8 所示,它极大地满足了 Real3D - AD 的需求。Reg3D - AD 利用双特征表示方法来保留训练原型的局部和全局特征。所考虑的数据集中存在两种不同的特征。第一个特征是每个点云的坐标值,即
x
−
x -
x−、
y
−
y -
y− 和
z
−
z -
z− 值。第二个特征是 PointMAE 特征,它表征了整个训练原型。坐标值封装了单个点的定位属性,而 PointMAE 模型优先获得训练原型的全面表示。训练阶段旨在建立一个从所有正常原型派生的邻域敏感特征库,用作记忆库。在将新功能纳入记忆库之前,我们实施 Coreset 采样技术来保持记忆库的大小。
-
异常分数计算:在计算异常分数之前,需要通过 RANSAC 算法 [2] 对测试 3D 对象进行配准。配准完成后,如果至少有一个点云异常,则将测试 3D 对象预测为异常,并通过点级特征和全局特征的平均分数计算点级异常分割。具体来说,对于测试对象 x t e s t x^{test} xtest,使用局部特征库 M l M^{l} Ml 和全局特征库 M g M^{g} Mg,对象级异常分数 s s s 是局部特征异常分数 s l s^{l} sl 和全局特征异常分数 s g s^{g} sg 的平均值。局部特征异常分数是测试 3D 对象的点级特征 P ( x t e s t ) P(x^{test}) P(xtest) 与其在 M l M^{l} Ml 中的最近邻 m l ∗ m^{l*} ml∗ 之间的最大分数 s l s s^{l s} sls:
m t e s t , ∗ = a r g m a x m t e s t ∈ P ( x t e s t ) min m l ∈ M l ∥ m t e s t − m l ∥ 2 , m l ∗ = a r g m i n m l ∈ M l ∥ m t e s t − m l ∥ 2 , ( 1 ) m^{test, *}=\underset{m^{test} \in \mathcal{P}(x^{test})}{arg max} \min _{m^{l} \in \mathcal{M}^{l}}\left\| m^{test}-m^{l}\right\| _{2}, m^{l *}=\underset{m^{l} \in \mathcal{M}^{l}}{arg min}\left\| m^{test}-m^{l}\right\| _{2}, (1) mtest,∗=mtest∈P(xtest)argmaxml∈Mlmin mtest−ml 2,ml∗=ml∈Mlargmin mtest−ml 2,(1)
s l ∗ = ∥ m t e s t , ∗ − m l ∗ ∥ 2 s^{l *}=\left\| m^{test, *}-m^{l *}\right\| _{2} sl∗= mtest,∗−ml∗ 2
为了增强异常检测模型的鲁棒性,PatchCore 采用了一种重要的重新加权方法 [18] 来调整异常分数:
s l = ( 1 − e x p ∥ m t e s t , ∗ − m ∗ ∥ 2 ∑ m ∈ N b ( m ∗ ) e x p ∥ m t e s t , ∗ − m ∥ 2 ) ⋅ s l ∗ , s^{l}=\left(1-\frac{exp \left\| m^{t e s t, *}-m^{*}\right\| _{2}}{\sum_{m \in \mathcal{N}_{b}(m^{*})} exp \left\| m^{t e s t, *}-m\right\| _{2}}\right) \cdot s^{l *}, sl=(1−∑m∈Nb(m∗)exp∥mtest,∗−m∥2exp∥mtest,∗−m∗∥2)⋅sl∗,
其中, N b ( m ∗ ) \mathcal{N}_{b}(m^{*}) Nb(m∗) 表示 M M M 中测试补丁特征 m ∗ m^{*} m∗ 的 b b b 个最近补丁特征。全局特征异常分数 s g s^{g} sg 的计算类似于 s l s^{l} sl,通过全局特征记忆库 M g M^{g} Mg 实现。最后,每个点云的总异常分数 s t = ( s l + s g ) / 2 s^{t}=(s^{l}+s^{g})/2 st=(sl+sg)/2。 -
ADBENCH - 3D 分析:表 4 中的结果表明,大多数 3D 异常检测算法不符合 Real3D - AD 的要求。回顾第 4.1 节中概述的设置,该设置与少样本异常检测的设置有显著相似之处。这是因为每个类别的训练数据集仅由 4 个原型组成。大多数当代最先进的 3D 异常检测算法并非专门为少样本异常检测任务设计。为了应对这一挑战,必须优化原型数据的利用,并确保获取的点云数据不受空间相对位置的影响。从表 4 中可以清楚地看出,我们的基线方法 Reg3D - AD 在 Real3D - AD 数据集上优于最先进的 3D 异常检测方法。
5.项目部署
5.1 源码与数据
源码地址:https://github.com/M-3LAB/Real3D-AD.git
Real3D-AD数据集(用于训练和评估的数据集,pcd格式)real3d-ad-pcd.zip(谷歌云盘)
real3d-ad-pcd.zip(百度网盘:vrmi)
Real3D-AD数据集(来自相机的原始数据,ply格式),real3d-ad-ply.zip(谷歌云盘)
real3d-ad-ply.zip(百度网盘:vvz1)
数据集统计:
| 索引 | 类别 | 实际尺寸 [mm](长/宽/高) | 透明度 | 训练样本数(正常) | 测试样本数(正常) | 测试样本数(缺陷) | 总样本数 | 训练点数量(最小/最大/平均) | 测试点数量(最小/最大/平均) | 异常比例 Δ |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 飞机 | 34.0/14.2/31.7 | 是 | 4 | 50 | 50 | 104 | 383k/ 413k/ 400k | 168k/ 773k/351k | 1.17% |
| 2 | 汽车 | 35.0/29.0/12.5 | 是 | 4 | 50 | 50 | 104 | 566k/1296k/1097k | 90k/ 149k/131k | 1.98% |
| 3 | 糖果棒 | 33.0/20.0/ 8.0 | 是 | 4 | 50 | 50 | 104 | 339k/1183k/ 553k | 149k/ 180k/157k | 2.36% |
| 4 | 鸡 | 25.0/14.0/20.0 | 否(白色) | 4 | 52 | 54 | 110 | 217k/1631k/1157k | 87k/1645k/356k | 4.46% |
| 5 | 钻石 | 29.0/29.0/18.7 | 是 | 4 | 50 | 50 | 104 | 1477k/2146k/1972k | 66k/ 84k/ 75k | 5.40% |
| 6 | 鸭子 | 30.0/22.2/29.4 | 是 | 4 | 50 | 50 | 104 | 545k/2675k/1750k | 155k/ 784k/216k | 1.99% |
| 7 | 鱼 | 37.7/24.0/ 4.0 | 是 | 4 | 50 | 50 | 104 | 230k/ 251k/ 240k | 104k/ 117k/110k | 2.85% |
| 8 | 宝石 | 22.5/18.8/17.0 | 是 | 4 | 50 | 50 | 104 | 169k/1819k/ 835k | 43k/ 645k/104k | 2.06% |
| 9 | 海马 | 38.0/11.2/ 3.5 | 是 | 4 | 50 | 50 | 104 | 189k/ 203k/ 194k | 74k/ 90k/ 83k | 4.57% |
| 10 | 贝壳 | 21.7/22.0/ 7.7 | 是 | 4 | 52 | 48 | 104 | 280k/ 316k/ 295k | 110k/ 144k/125k | 2.25% |
| 11 | 海星 | 27.4/27.4/ 4.8 | 是 | 4 | 50 | 50 | 104 | 198k/ 209k/ 202k | 74k/ 116k/ 88k | 4.46% |
| 12 | 太妃糖 | 38.0/12.0/10.0 | 是 | 4 | 50 | 50 | 104 | 178k/1001k/ 385k | 78k/ 97k/ 88k | 2.46% |
5.2 数据准备
- 下载real3d-ad-pcd.zip并解压到
./data/目录下
data
├── airplane
├── train
├── 1_prototype.pcd
├── 2_prototype.pcd
...
├── test
├── 1_bulge.pcd
├── 2_sink.pcd
...
├── gt
├── 1_bulge.txt
├── 2_sink.txt
...
├── car
...
5.3 预训练模型
| 主干网络 | 预训练模型 |
|---|---|
| 点变换器 | Point-MAE |
| 点变换器 | Point-Bert |
- 下载模型将其移动到
./checkpoints/目录下
5.4 环境配置(windows 10)
conda env create -f 3dad.yaml
conda activate 3dad
git clone https://github.com/M-3LAB/Real3D-AD.git
cd Real3D-AD
pip install "git+https://github.com/erikwijmans/Pointnet2_PyTorch.git#egg=pointnet2_ops&subdirectory=pointnet2_ops_lib"
pip install numpy==1.23.5
训练与测试:
sh start.sh
注:基于代码中几处bug,要动手改一下,才能正常运行。
6. 局限性和潜在的负面社会影响
- 局限性:基于我们的工作仍有很大的改进和探索空间。例如,我们的数据来自 3D 扫描仪,仅包含空间信息,这在工业生产中很常见。然而,通过校准和拼接多个 RGBD 图像或使用建模软件渲染,可能获得标准化的 RGB 点云模板。RGB 点云模板可同时应用于 RGB 图像(2D)异常检测和点云(3D)异常检测。此外,我们的数据可以通过控制渲染条件从不同角度生成深度图像,从而从该角度进行异常检测,但这尚未得到探索。此外,虽然我们的基线方法优于现有的异常检测方法,但由于测试点云边缘被截断,它仍然容易出现误检测。因此,期望更先进的模型能更有效地解决这些问题。我们的工作作为全视角点云异常检测的首次尝试,将激发该领域的进一步探索。
- 潜在的负面社会影响:我们的数据是通过扫描工业产品获得的,因此不会存在负面社会影响。
7. 结论
在这项工作中,我们提出了 Real3D - AD 数据集来研究高精度点云异常检测问题,旨在促进先进加工和精密制造中缺陷识别的研究。Real3D - AD 是迄今为止最出色的高精度 3D 工业异常检测数据集,包含 1254 个高分辨率 3D 物品(每个物品至少有一百万个点云),涵盖 12 种具有现实应用的对象。在点云分辨率(0.0010mm - 0.0015mm)、360 度覆盖和完美原型方面,Real3D - AD 优于现有的 3D 异常检测数据集。此外,我们对 Real3D - AD 数据集进行了全面评估,突出了缺乏实现高精度点云异常检测应用的基线方法。我们提出了一种通用的基于配准的 3D 异常检测技术(Reg3D - AD)和 3D 特征耦合单元,可保留局部特征和全局表示。在 Real3D - AD 数据集上的实验表明,Reg3D - AD 的性能明显优于次优方法。
附录A:实验设置
由于GPU内存的限制,我们对基准方法进行了下采样。对于BTF,我们以100:1的比例对训练样本的点进行采样和存储,对于测试样本,则以500:1的比例进行点采样。在计算出每个点的异常分数后,我们使用k近邻(KNN)算法来估计未采样点的异常分数。至于M3DM,我们将点变换器的点组数设置为16384。在基于PatchCore的实验中,我们统一将记忆库的大小设置为10000。
参考文献:
[1] Paul Bergmann and David Sattlegger. Anomaly detection in 3d point clouds using deep geometric descriptors. 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2612–2622, 2022.
[2] Robert C. Bolles and Martin A. Fischler. A ransac-based approach to model fitting and its application to finding cylinders in range data. In International Joint Conference on Artificial Intelligence, 1981.
[3] Luca Bonfiglioli, Marco Toschi, Davide Silvestri, Nicola Fioraio, and Daniele De Gregorio. The eyecandies dataset for unsupervised multimodal anomaly detection and localization. Proceedings of the Asian Conference on Computer Vision, pages 3586–3602, 2022.
[4] Yunkang Cao, Qian Wan, Weiming Shen, and Liang Gao. Informative knowledge distillation for image anomaly segmentation. Knowledge-Based Systems, 248:108846, 2022.
[5] Yunkang Cao, Xiaohao Xu, Zhaoge Liu, and Weiming Shen. Collaborative discrepancy optimization for reliable image anomaly localization. IEEE Transactions on Industrial Informatics, 2023.
[6] Yunkang Cao, Xiaohao Xu, and Weiming Shen. Complementary pseudo multimodal feature for point cloud anomaly detection. arXiv preprint arXiv:2303.13194, 2023.
[7] Yunkang Cao, Xiaohao Xu, Chen Sun, Yuqi Cheng, Zongwei Du, Liang Gao, and Weiming Shen. Segment any anomaly without training via hybrid prompt regularization. arXiv preprint arXiv:2305.10724, 2023.
[8] Ruitao Chen, Guoyang Xie, Jiaqi Liu, Jinbao Wang, Ziqi Luo, Jinfan Wang, and Feng Zheng. Easynet: An easy network for 3d industrial anomaly detection. arXiv preprint arXiv:2307.13925, 2023.
[9] Blender Online Community. Blender - a 3d modelling and rendering package. 2018.
[10] CloudCompare Community. Cloudcompare - a 3d pointcloud and mesh software. 2016.
[11] Yajie Cui, Zhaoxiang Liu, and Shiguo Lian. A survey on unsupervised industrial anomaly detection algorithms. arXiv preprint arXiv:2204.11161, 2022.
[12] Hanqiu Deng and Xingyu Li. Anomaly detection via reverse distillation from one-class embedding. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9737–9746, 2022.
[13] Eleazar Eskin, Andrew O. Arnold, Michael J. Prerau, Leonid Portnoy, and S. Stolfo. A geometric framework for unsupervised anomaly detection. In Applications of Data Mining in Computer Security, 2002.
[14] Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2015.
[15] Eliahu Horwitz and Yedid Hoshen. Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2967–2976, 2023.
[16] Xi Jiang, Jianlin Liu, Jinbao Wang, Qiang Nie, Kai Wu, Yong Liu, Chengjie Wang, and Feng Zheng. Softpatch: Unsupervised anomaly detection with noisy data. Advances in Neural Information Processing Systems, 35:15433–15445, 2022.
[17] Jiaqi Liu, Guoyang Xie, Jingbao Wang, Shangnian Li, Chengjie Wang, Feng Zheng, and Yaochu Jin. Deep industrial image anomaly detection: A survey. arXiv preprint arXiv:2301.11514, 2023.
[18] Tongliang Liu and Dacheng Tao. Classification with noisy labels by importance reweighting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38:447–461, 2014.
[19] Yatian Pang, Wenxiao Wang, Francis E. H. Tay, W. Liu, Yonghong Tian, and Liuliang Yuan. Masked autoencoders for point cloud self-supervised learning. In European Conference on Computer Vision, 2022.
[20] Bergmann Paul, Jin Xin, Sattlegger David, and Steger Carsten. The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization. In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, volume 5: 202-213, 2022.
[21] Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14298–14308, 2021.
[22] Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14318–14328, 2022.
[23] Marco Rudolph, Tom Wehrbein, Bodo Rosenhahn, and Bastian Wandt. Asymmetric student-teacher networks for industrial anomaly detection. 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2591–2601, 2022.
[24] Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. Fast point feature histograms (fpfh) for 3d registration. In 2009 IEEE International Conference on Robotics and Automation, pages 3212–3217, 2009.
[25] Xian Tao, Xinyi Gong, Xin Yu Zhang, Shaohua Yan, and Chandranath Adak. Deep learning for unsupervised anomaly localization in industrial images: A survey. IEEE Transactions on Instrumentation and Measurement, 71:1–21, 2022.
[26] Tran Dinh Tien, Anh Tuan Nguyen, Nguyen Hoang Tran, Ta Duc Huy, Soan Duong, Chanh D Tr Nguyen, and Steven QH Truong. Revisiting reverse distillation for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24511–24520, 2023.
[27] Qian Wan, Yunkang Cao, Liang Gao, Weiming Shen, and Xinyu Li. Position encoding enhanced feature mapping for image anomaly detection. In 2022 IEEE 18th International Conference on Automation Science and Engineering (CASE), pages 876–881. IEEE, 2022.
[28] Yue Wang, Jinlong Peng, Jiangning Zhang, Ran Yi, Yabiao Wang, and Chengjie Wang. Multimodal industrial anomaly detection via hybrid fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8032–8041, 2023.
[29] Matthias Wieler and Tobias Hahn. Weakly supervised learning for industrial optical inspection. In DAGM symposium in, 2007.
[30] Guoyang Xie, Jinbao Wang, Jiaqi Liu, Yaochu Jin, and Feng Zheng. Pushing the limits of few-shot anomaly detection in industry vision: Graphcore. In The Eleventh International Conference on Learning Representations, 2022.
[31] Guoyang Xie, Jinbao Wang, Jiaqi Liu, Jiayi Lyu, Yong Liu, Chengjie Wang, Feng Zheng, and Yaochu Jin. Im-iad: Industrial image anomaly detection benchmark in manufacturing. arXiv preprint arXiv:2301.13359, 2023.
[32] Xincheng Yao, Ruoqi Li, Jing Zhang, Jun Sun, and Chongyang Zhang. Explicit boundary guided semi-push-pull contrastive learning for supervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24490–24499, 2023.
[33] Zhiyuan You, Lei Cui, Yujun Shen, Kai Yang, Xin Lu, Yu Zheng, and Xinyi Le. A unified model for multi-class anomaly detection. arXiv preprint arXiv:2206.03687, 2022.
[34] Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pretraining 3d point cloud transformers with masked point modeling. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19291–19300, 2021.
[35] Vitjan Zavrtanik, Matej Kristan, and Danijel Skoˇcaj. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8330–8339, 2021.
[36] Lingrui Zhang, Shuheng Zhang, Guoyang Xie, Jiaqi Liu, Hua Yan, Jinbao Wang, Feng Zheng, and Yaochu Jin. What makes a good data augmentation for few-shot unsupervised image anomaly detection? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4344–4353, 2023.
[37] Ying Zhao. Omnial: A unified cnn framework for unsupervised anomaly localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3924–3933, 2023.



















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











