




论文地址:https://arxiv.org/abs/2311.03839
介绍
大型语言模型(LLM),如 ChatGPT,为语言建模和生成人类水平的文本输出带来了质的飞跃。
这些模型在庞大的文本库中进行训练,有效地建立了高度复杂和准确的语言概率模型。
另一方面,使用这些语言是智人最重要的特征之一,了解人类认知能力与这些语言特征之间的相互关系一直被认为是一个非常重要的研究领域。
再加上在现有的研究中,LLMs 表现出了与人类相似的记忆特征,因此本文作者认为 “LLMs 可以作为一个非常有用的工具,用于这方面的研究”。
在此背景下,本文介绍了为研究人类记忆特征与 LLM 之间的相似性而进行的各种实验,并证明了人类特有的现象,如先验效应、致死效应和通过重复巩固记忆等,也出现在 LLM 中。
概述
虽然人类的记忆看似简单,但实际上具有非常特殊的性质,许多认知心理学家对其进行了长达一个多世纪的研究。
这些记忆特性的典型表现是首要效应和复现效应,即在记忆单词表时,位于单词表开头或结尾的单词更容易被回忆起来。
此外,还发现了人类特有的其他各种记忆特征,例如,记忆会在一定时间间隔内通过重复而得到加强。
本文论证了 LLMs 可以成为研究这种人类特有记忆特征的非常有用的工具,并利用 LLMs 实际进行了各种实验。
实验装置
认知心理学中的标准记忆测试技术包括给参与者提供一份按顺序排列的单词表,要求他们记住自己在单词表中的位置,然后测试他们回忆的准确性。
另一方面,这些方法很难适用于 LLM,因此本文转而设计了一种文本结构来探索特定的记忆特征。
实验过程如下图所示。(本文所有实验均使用开源模型 GPT-J)。

在这个实验中,GPT-J 不是记忆单词列表,而是向其展示有关任何姓名标识的人的事实列表。
然后在 GPT-J 中添加以下查询

如果输出概率最高的名词与事实列表中给特定人(此处为保罗)的名词相匹配,那么答案就被认为是正确的。
本文通过改变需要记忆的事实列表的长度、类别和插入文字,进行了各种实验,并对出现的记忆特征进行了研究。
实验结果
首要效应、重复效应
为了研究上述优先效应和致死效应是否会出现在 LLM 中,我们将特定 X 在事实列表中的位置作为函数来计算召回准确率。
下图显示了人类和 GPT-J 记忆实验对 20 个事实列表的回忆准确率。
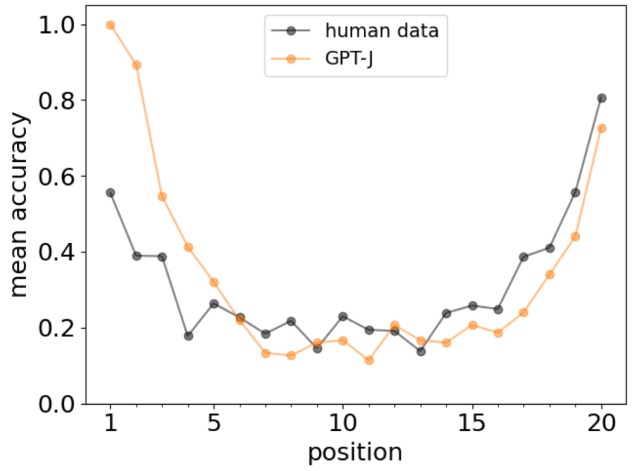
该图中的 U 型曲线是主要效应和致死效应的特有现象,结果证实了主要效应和致死效应在LLM 中的出现与在人类中一样。
其他信息
在人类记忆测试中发现的另一个特点是,插入有关某个单词的附加信息会提高回忆起该单词的可能性,即使查询不包含附加信息。
为了检验本文中的 LLM 是否也出现了类似的现象,我们在列表的某些位置(第 5、10 和 15 位)插入了以下附加信息。

下图显示了基线与插入附加信息后 GPT-J 召回准确率的比较。
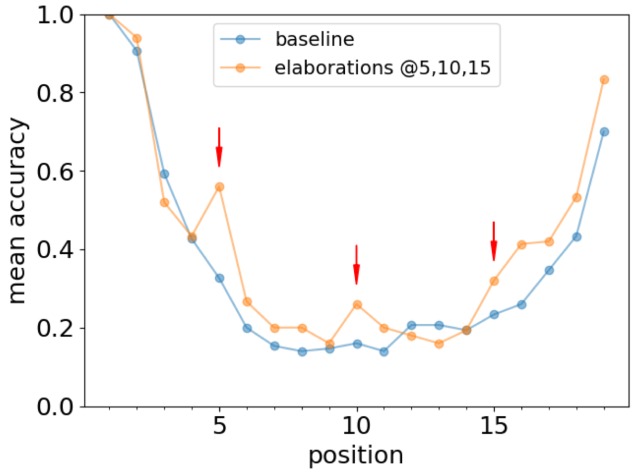
该图清楚地表明,插入附加信息可提高召回准确率。
通过重复强化记忆
很明显,通过重复可以加深对给定材料的记忆,在这方面,法律硕士也可能有类似的表现。
就人类记忆而言,心理学家艾宾浩斯(Ebbinghaus)指出,“在最初记忆要学习的材料(=艾宾浩斯的遗忘曲线)后有一定的时间间隔时,记忆效果最好”。
具体做法是,在上述提供给 GPT-J 的事实清单文本之前插入一个重复句(=要记忆的事实清单),这样要记忆的信息就会在文本中重复出现。
与正常基线的对比实验结果如下图所示。
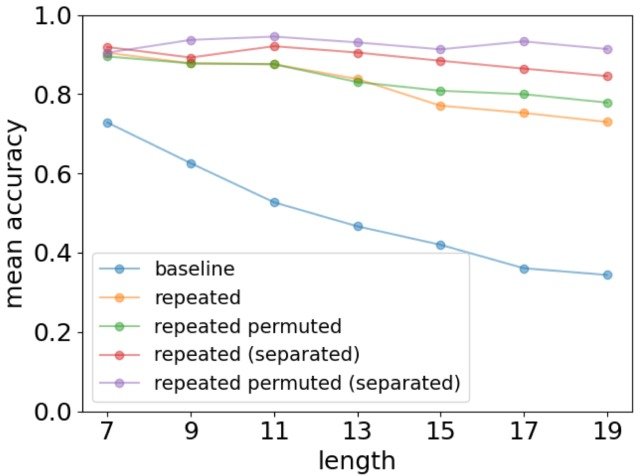
如图所示,LLM(=repeated),即需要记忆的信息在文本中重复出现,与基线相比,记忆准确率有显著提高。
此外,还发现了一种与人类记忆特征相一致的趋势,即当重复信息的文字与事实列表中的文字距离较远(=分离)时,记忆的准确性就会提高。
总结
结果如何?在这篇文章中,我们介绍了一篇论文,该论文通过各种实验研究了人类记忆特征与 LLM 之间的相似性,并证明了人类特有的现象,如先验效应、致死效应和通过重复巩固记忆也出现在 LLM中。
本文的实验结果证实了人类和 LLMs 记忆特征之间的许多相似之处,这些结果表明 LLMs 是研究人类生物记忆机制的一种非常有用的工具。
关于这个实验的结果,作者 “认为 LLM 的类人记忆特性并不是从 LLM 架构中自动衍生出来的,而是从训练文本数据的统计中学习出来的”,因此我们期待未来有更多的研究来证实这一假设!



















 1405
1405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











