




前言
大型语言模型(LLM)的核心优势在于其庞大的参数集,这些参数是模型学习语言的基石。参数的丰富性赋予了模型深入理解词汇和短语间复杂关系的能力,使得那些拥有数十亿参数的模型能够创作出多样化的文本,并以充满信息的方式应对开放性问题和挑战。
模型如ChatGPT,基于Transformer架构,精于理解和创造类人语言,对于任何需要深层自然语言处理的应用来说都是宝贵的资产。然而,它们也存在一些局限,例如可能包含过时的信息、难以与外部系统互动、缺乏对上下文的深入理解,有时甚至会产生看似合理实则错误或毫无意义的回答。
为了克服这些限制,将LLM与外部数据源和功能相结合是必要的,但这也可能带来复杂性,并需要广泛的编码和数据处理技能。此外,理解人工智能的概念和复杂算法本身就是一个挑战,这增加了使用LLM开发应用程序的学习曲线。
尽管存在这些挑战,将LLM与其他工具集成,创建出支持LLM的应用程序,有潜力彻底改变我们的数字体验。这些应用程序能够极大提升效率和生产力、简化任务、增强决策能力,并提供定制化的用户体验。
在本文中,我们将深入探讨这些问题,并探索使用Langchain进行即时工程的先进技术。通过清晰的解释、实际示例和分步指导,您将了解到如何利用Langchain的强大功能,以最大限度地发挥GPT-4等最新生成式AI模型的潜力。Langchain是一个尖端的库,它为设计、实现和优化提示提供了极大的便利和灵活性。随着我们深入了解即时工程的原理和实践。
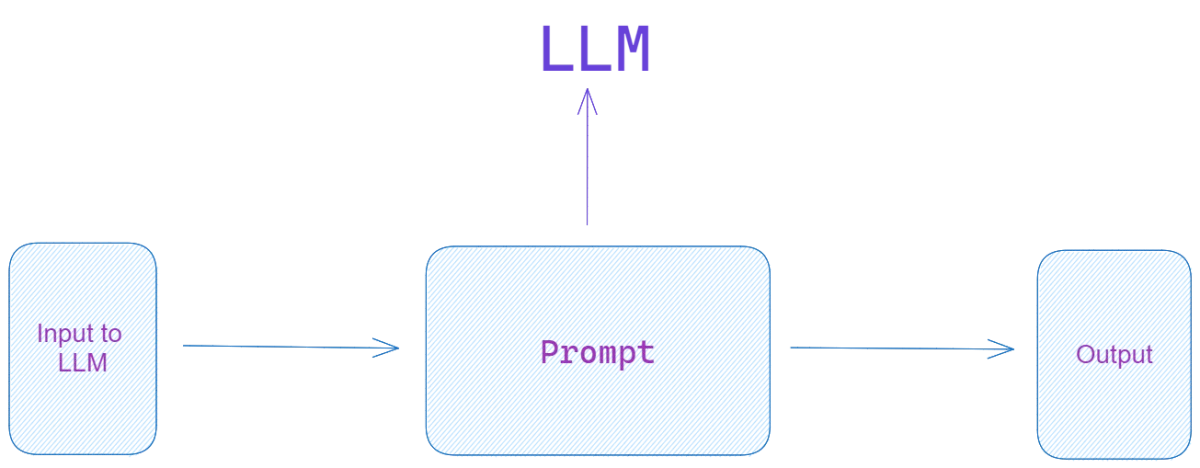
提示
在深入了解提示工程的技术细节之前,有必要了解提示的概念及其意义。
一个 ‘提示’ 是一个标记序列,用作语言模型的输入,指示它生成特定类型的响应。 提示在引导模型的行为方面起着至关重要的作用。 它们可以影响生成文本的质量,并且如果正确制作,可以帮助模型提供富有洞察力、准确且针对特定上下文的结果。
提示工程是设计有效提示的艺术和科学。 目标是从语言模型中得出所需的输出。 通过仔细选择和构建提示,可以引导模型生成更准确和相关的响应。 在实践中,这涉及微调输入短语以适应模型的训练和结构偏差。
提示工程的复杂性包括从简单的技术(例如向模型提供相关关键字)到更高级的方法,包括设计复杂的结构化提示,利用模型的内部机制来发挥其优势。
Langchain提示工具
LangChain,于2022年XNUMX月推出 哈里森蔡斯,已成为其中之一 评价最高的开源框架 将于 2023 年在 GitHub 上发布。它提供了一个简化且标准化的界面,用于将大型语言模型 (LLM) 合并到应用程序中。 它还为快速工程提供了功能丰富的界面,允许开发人员尝试不同的策略并评估其结果。 通过使用Langchain,您可以更有效、更直观地执行快速的工程任务。
langflow 作为一个用户界面,用于将 LangChain 组件编排成可执行流程图,从而实现快速原型设计和实验。
LangChain填补了大众人工智能发展的关键空白。 它支持一系列 NLP 应用程序(例如虚拟助手、内容生成器、问答系统等)来解决一系列现实问题。
LangChain 不是一个独立的模型或提供者,而是简化了与不同模型的交互,将 LLM 应用程序的功能扩展到简单 API 调用的限制之外。
LangChain架构
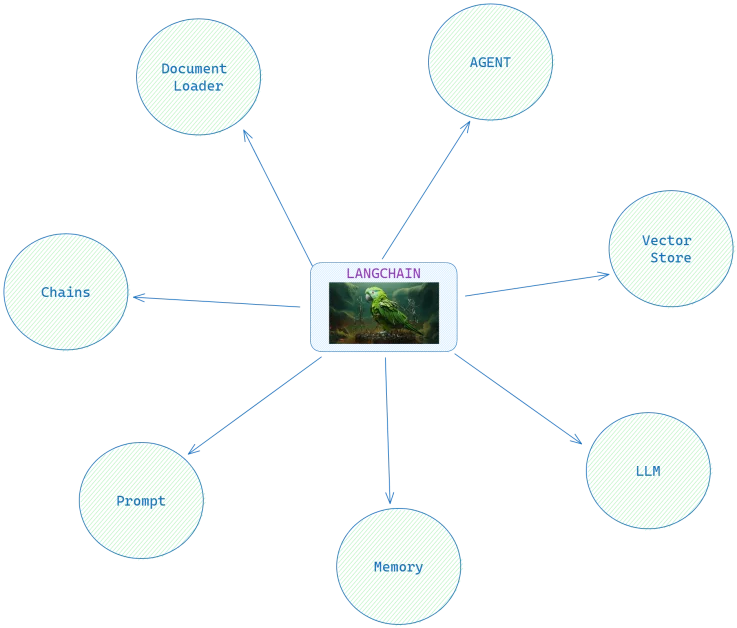
LangChain的主要组件包括模型I/O、提示模板、内存、代理和链。
模型输入/输出
LangChain 通过使用称为模型 I/O 的标准化接口来封装各种语言模型,从而促进与各种语言模型的无缝连接。 这有助于轻松进行模型切换,以实现优化或更好的性能。 LangChain支持多种语言模型提供者,包括 OpenAI, HuggingFace, Azure, Fireworks。
提示模板
这些用于通过提供简洁的说明或示例来管理和优化与LLM的互动。 优化提示可增强模型性能,其灵活性对输入过程有显着贡献。
提示模板的简单示例:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(input_variables=["subject"],
template="What are the recent advancements in the field of {subject}?")
print(prompt.format(subject="Natural Language Processing"))
随着复杂性的提高,我们在 LangChain 中遇到了更复杂的模式,例如理性和行动(ReAct)模式。 ReAct 是操作执行的重要模式,其中代理将任务分配给适当的工具,为其自定义输入,并解析其输出以完成任务。 下面的 Python 示例展示了 ReAct 模式。 它演示了浪链中的提示是如何构造的,使用一系列的想法和行动来推理问题并产生最终答案:
PREFIX = """Answer the following question using the given tools:"""
FORMAT_INSTRUCTIONS = """Follow this format:
Question: {input_question}
Thought: your initial thought on the question
Action: your chosen action from [{tool_names}]
Action Input: your input for the action
Observation: the action's outcome"""
SUFFIX = """Start!
Question: {input}
Thought:{agent_scratchpad}"""
内存
内存是 LangChain 中的一个关键概念,它使LLM和工具能够随着时间的推移保留信息。 这种有状态行为通过存储先前的响应、用户交互、环境状态和代理的目标来提高LangChain应用程序的性能。 ConversationBufferMemory 和 ConversationBufferWindowMemory 策略分别帮助跟踪对话的完整部分或最近部分。 对于更复杂的方法,ConversationKGMemory 策略允许将对话编码为知识图,该知识图可以反馈到提示中或用于预测响应,而无需调用 LLM。
代理
代理通过执行操作和任务与世界交互。 在LangChain中,代理结合了工具和链来执行任务。 它可以建立与外界的信息检索连接,以扩充LLM知识,从而克服其固有的局限性。 他们可以根据情况决定将计算传递给计算器或 Python 解释器。
代理配备了子组件:
- 工具:这些是功能组件。
- 工具包:工具集合。
- 代理执行人:这是允许在工具之间进行选择的执行机制。
LangChain中的代理也遵循零样本ReAct模式,其中决策仅基于工具的描述。 该机制可以通过内存进行扩展,以便考虑完整的对话历史记录。 借助 ReAct,您可以提示LLM在思想/行动/观察循环中做出响应,而不是要求LLM自动完成您的文本。
Chains
Chains,顾名思义,是允许 LangChain 库无缝处理语言模型输入和输出的操作序列。 LangChain 的这些组成部分基本上是由链接组成的,这些链接可以是其他链,也可以是提示、语言模型或实用程序等原语。
将链条想象为工厂中的传送带。 这条带上的每一步都代表一个特定的操作,可以调用语言模型,将 Python 函数应用于文本,甚至以特定方式提示模型。
LangChain将其链分为三种类型:实用链、通用链和组合文档链。 我们将深入讨论实用链和通用链。
- 实用链 专门设计用于从语言模型中提取狭义任务的精确答案。 例如,让我们看一下 LLMMathChain。 该实用程序链使语言模型能够执行数学计算。 它接受自然语言的问题,语言模型反过来生成一个 Python 代码片段,然后执行该代码片段以产生答案。
- 通用链另一方面,作为其他链的构建块,但不能直接独立使用。 这些链(例如 LLMChain)是基础链,通常与其他链结合来完成复杂的任务。 例如,LLMChain 经常用于查询语言模型对象,方法是根据提供的提示模板格式化输入,然后将其传递到语言模型。
使用 Langchain
可以利用 Docker、Conda、Pip 和 Poetry 等流行工具来设置 LangChain。 这些方法的相关安装文件可以在 LangChain 存储库中找到: https://github.com/benman1/generative_ai_with_langchain. 这包括一个 Dockerfile , requirements.txt , pyproject.toml, langchain_ai.yml 。
第1步:设置Langchain
首先,需要安装 Langchain 软件包。 我们使用的是Windows操作系统。 在终端中运行以下命令来安装它:
pip install langchain
第二步:导入Langchain及其他必要模块
接下来,导入 Langchain 以及其他必要的模块。 在这里,我们还导入了 Transformers 库,该库广泛用于 NLP 任务。
import langchain
from transformers import AutoModelWithLMHead, AutoTokenizer
第 3 步:加载预训练模型
OpenAI
OpenAI 模型可以方便地与LangChain库或OpenAI Python客户端库对接。 值得注意的是,OpenAI 为文本嵌入模型提供了 Embedding 类。 两个关键的 LLM 模型是 GPT-3.5 和 GPT-4,主要区别在于Token长度。 每种型号的定价可以在 OpenAI 的网站上找到。 虽然还有更多 复杂型号,如 GPT-4-32K 具有更高的Token接受度,它们通过 API 的可用性是 并不总是有保证.
访问这些模型需要 OpenAI API 密钥。 这可以通过在 OpenAI 平台上创建帐户、设置计费信息并生成新密钥来完成。
import os
os.environ["OPENAI_API_KEY"] = 'your-openai-token'
成功创建密钥后,可以将其设置为环境变量 (OPENAI_API_KEY) 或在 OpenAI 调用的类实例化期间将其作为参数传递。
使用一个 LangChain 脚本来展示与 OpenAI 模型的交互:
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
# The LLM takes a prompt as an input and outputs a completion
prompt = "who is the president of the United States of America?"
completion = llm(prompt)
在此示例中,代理被初始化以执行计算。 该代理接受一个输入(一个简单的加法任务),使用提供的 OpenAI 模型对其进行处理并返回结果。
huggingface
huggingface 是一个 免费使用 Transformers Python 库,与 PyTorch、TensorFlow 和 JAX 兼容,并包含以下模型的实现 BERT, T5等等。
Hugging Face 还提供 Hugging Face Hub,这是一个用于托管代码存储库、机器学习模型、数据集和 Web 应用程序的平台。
要将 Hugging Face 用作模型的提供者,需要一个帐户和 API 密钥(可以从其网站获取)。 该令牌可以在您的环境中以 HUGGINGFACEHUB_API_TOKEN 的形式提供。
以下 Python 代码片段,它利用了 Google 开发的开源模型,即 Flan-T5-XXL 模型:
from langchain.llms import HuggingFaceHub
llm = HuggingFaceHub(model_kwargs={"temperature": 0.5, "max_length": 64},repo_id="google/flan-t5-xxl")
prompt = "In which country is Tokyo?"
completion = llm(prompt)
print(completion)
该脚本以问题作为输入并返回答案,展示模型的知识和预测能力。
第 4 步:基本工程
首先,我们将生成一个简单的提示并查看模型如何响应。
prompt = 'Translate the following English text to French: "{0}"'
input_text = 'Hello, how are you?'
input_ids = tokenizer.encode(prompt.format(input_text), return_tensors='pt')
generated_ids = model.generate(input_ids, max_length=100, temperature=0.9)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
在上面的代码片段中,我们提供了将英语文本翻译成法语的提示。 然后,语言模型尝试根据提示翻译给定的文本。
第 5 步:高级提示工程
虽然上述方法效果很好,但它没有充分利用即时工程的力量。 让我们通过引入一些更复杂的提示结构来改进它。
prompt = 'As a highly proficient French translator, translate the following English text to French: "{0}"'
input_text = 'Hello, how are you?'
input_ids = tokenizer.encode(prompt.format(input_text), return_tensors='pt')
generated_ids = model.generate(input_ids, max_length=100, temperature=0.9)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
在此代码片段中,我们修改提示以表明翻译是由“高度熟练的法语翻译人员”完成的。 提示的变化可以改进翻译,因为模型现在假设了专家的角色。
与Langchain一起构建学术文献问答系统
我们将使用LangChain构建一个学术文献问答系统,可以回答有关最近发表的学术论文的问题。
首先,为了设置我们的环境,我们安装必要的依赖项。
pip install langchain arxiv openai transformers faiss-cpu
安装完成后,我们创建一个新的 Python 笔记本并导入必要的库:
from langchain.llms import OpenAI
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.docstore.document import Document
import arxiv
我们问答系统的核心是能够获取与某个领域相关的相关学术论文,这里我们考虑自然语言处理(NLP),使用arXiv学术数据库。 为了执行此操作,我们定义一个函数 get_arxiv_data(max_results=10)。 该函数从 arXiv 收集最新的 NLP 论文摘要,并将其封装到 LangChain Document 对象中,以摘要作为内容,以唯一的条目 id 作为来源。
我们将使用 arXiv API 来获取与 NLP 相关的最新论文:
def get_arxiv_data(max_results=10):
search = arxiv.Search(
query="NLP",
max_results=max_results,
sort_by=arxiv.SortCriterion.SubmittedDate,
)
documents = []
for result in search.results():
documents.append(Document(
page_content=result.summary,
metadata={"source": result.entry_id},
))
return documents
该函数从 arXiv 检索最新 NLP 论文的摘要,并将其转换为 LangChain Document 对象。 我们使用论文的摘要及其唯一的条目 ID(论文的 URL)分别作为内容和来源。
def print_answer(question):
print(
chain(
{
"input_documents": sources,
"question": question,
},
return_only_outputs=True,
)["output_text"]
)
让我们定义我们的语料库并设置 LangChain:
sources = get_arxiv_data(2)
chain = load_qa_with_sources_chain(OpenAI(temperature=0))
我们的学术问答系统现已准备就绪,我们可以通过提出问题来测试它:
print_answer("What are the recent advancements in NLP?")
输出将是您问题的答案,并引用提取信息的来源。 例如:
Recent advancements in NLP include Retriever-augmented instruction-following models and a novel computational framework for solving alternating current optimal power flow (ACOPF) problems using graphics processing units (GPUs).
SOURCES: http://arxiv.org/abs/2307.16877v1, http://arxiv.org/abs/2307.16830v1
您可以根据需要轻松切换型号或更改系统。 例如,我们在这里更改为 GPT-4,这最终为我们提供了更好、更详细的响应。
sources = get_arxiv_data(2)
chain = load_qa_with_sources_chain(OpenAI(model_name="gpt-4",temperature=0))
Recent advancements in Natural Language Processing (NLP) include the development of retriever-augmented instruction-following models for information-seeking tasks such as question answering (QA). These models can be adapted to various information domains and tasks without additional fine-tuning. However, they often struggle to stick to the provided knowledge and may hallucinate in their responses. Another advancement is the introduction of a computational framework for solving alternating current optimal power flow (ACOPF) problems using graphics processing units (GPUs). This approach utilizes a single-instruction, multiple-data (SIMD) abstraction of nonlinear programs (NLP) and employs a condensed-space interior-point method (IPM) with an inequality relaxation strategy. This strategy allows for the factorization of the KKT matrix without numerical pivoting, which has previously hampered the parallelization of the IPM algorithm.
SOURCES: http://arxiv.org/abs/2307.16877v1, http://arxiv.org/abs/2307.16830v1
GPT-4 中的令牌可以短至一个字符,也可以长至一个单词。 例如,GPT-4-32K 在一次运行中最多可以处理 32,000 个令牌,而 GPT-4-8K 和 GPT-3.5-turbo 分别支持 8,000 个和 4,000 个令牌。 然而,值得注意的是,与这些模型的每次交互都会产生成本,该成本与处理的令牌数量(无论是输入还是输出)成正比。
在我们的问答系统中,如果一篇学术文献超过了最大令牌限制,系统将无法完整处理它,从而影响响应的质量和完整性。 要解决此问题,可以将文本分解为符合令牌限制的较小部分。
FAISS(Facebook 人工智能相似性搜索) 有助于快速找到与用户查询相关的最相关的文本块。 它创建每个文本块的向量表示,并使用这些向量来识别和检索与给定问题的向量表示最相似的块。
重要的是要记住,即使使用 FAISS 这样的工具,由于标记限制而必须将文本分成更小的块有时会导致上下文丢失,从而影响答案的质量。 因此,在使用这些大型语言模型时,仔细管理和优化令牌使用至关重要。
pip install faiss-cpu langchain CharacterTextSplitter
确保安装了上述库后,运行
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.faiss import FAISS
from langchain.text_splitter import CharacterTextSplitter
documents = get_arxiv_data(max_results=10) # We can now use feed more data
document_chunks = []
splitter = CharacterTextSplitter(separator=" ", chunk_size=1024, chunk_overlap=0)
for document in documents:
for chunk in splitter.split_text(document.page_content):
document_chunks.append(Document(page_content=chunk, metadata=document.metadata))
search_index = FAISS.from_documents(document_chunks, OpenAIEmbeddings())
chain = load_qa_with_sources_chain(OpenAI(temperature=0))
def print_answer(question):
print(
chain(
{
"input_documents": search_index.similarity_search(question, k=4),
"question": question,
},
return_only_outputs=True,
)["output_text"]
)
代码完成后,我们现在就有了一个查询NLP领域最新学术文献的强大工具。
Recent advancements in NLP include the use of deep neural networks (DNNs) for automatic text analysis and natural language processing (NLP) tasks such as spell checking, language detection, entity extraction, author detection, question answering, and other tasks.
SOURCES: http://arxiv.org/abs/2307.10652v1, http://arxiv.org/abs/2307.07002v1, http://arxiv.org/abs/2307.12114v1, h
结论
将大型语言模型 (LLM) 集成到应用程序中加速了多个领域的采用,包括语言翻译、情感分析和信息检索。 快速工程是最大限度发挥这些模型潜力的强大工具,而 Langchain 在简化这一复杂任务方面处于领先地位。 其标准化界面、灵活的提示模板、强大的模型集成以及代理和链的创新使用确保了LLM的最佳表现。
然而,尽管取得了这些进步,但仍有一些提示需要牢记。 当您使用 Langchain 时,必须了解输出的质量在很大程度上取决于提示的措辞。 尝试不同的提示样式和结构可以产生更好的结果。 另外,请记住,虽然 Langchain 支持多种语言模型,但每种语言模型都有其优点和缺点。 为您的特定任务选择合适的产品至关重要。 最后,重要的是要记住,使用这些模型需要考虑成本,因为令牌处理直接影响交互成本。
正如分步指南中所演示的,Langchain 可以为强大的应用程序提供支持,例如学术文献问答系统。 随着用户社区的不断壮大以及在开源领域的日益突出,Langchain 有望成为充分利用 GPT-4 等 LLM 潜力的关键工具。



















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











