 BitNet单比特大模型
BitNet单比特大模型





概述
为了实现高精确度,大规模语言模型变得越来越大,但随着模型越来越大,其部署也面临挑战,人们担心计算量和能耗会增加。本研究提出了权重为 ±1 的单比特变换器,结果表明它能以更少的计算资源和更高的能效实现与传统 16 位模型相同的性能。有趣的是,我们还发现,随着模型大小的增加,它遵循与传统变形器相同的缩放规律。这种创新方法是轻量级、可控的 1 位大规模语言模型的基础。
论文地址:https://arxiv.org/abs/2310.11453
研究背景
对大规模语言模型的巨大规模和模型量化的预期
大规模语言模型的规模在不断扩大,预计未来还会更大。然而,它们的高推理成本和能耗大大增加了使用大规模语言模型的成本。因此,人们开始关注模型量化(参数整数化),将其作为在保持大规模语言模型性能的同时减少模型重量的一种方法,目的是减少内存使用量和计算负荷。
关于模型量化的传统研究。
目前的模型量化大多是在训练后进行的。这既简单又易于应用,因为它不需要对模型训练管道进行任何更改或重新训练。然而,由于在训练过程中没有对量化进行优化,量化可能会导致准确度的显著下降。模型量化的另一种方法是在训练过程中考虑量化。这样可以对模型进行持续学习和微调,这对于大规模语言模型来说至关重要。然而,在训练过程中考虑模型量化的挑战在于优化。这意味着随着模型准确度的降低,其收敛性也会下降。此外,考虑量化的学习是否遵循语言模型的缩放规律也不是一件容易的事。
在此背景下,作者提出了具有量化感知学习机制的 BitNet。该作品还讨论了其学习中的扩展规律。
建议方法
比特网
简单地说,BitNet 就是用单个比特权重表示的比特衬垫层取代传统变压器的衬垫层。BitNet 的简要概述如图 1 所示。除此以外,BitNet 的机制与普通变换器相同。
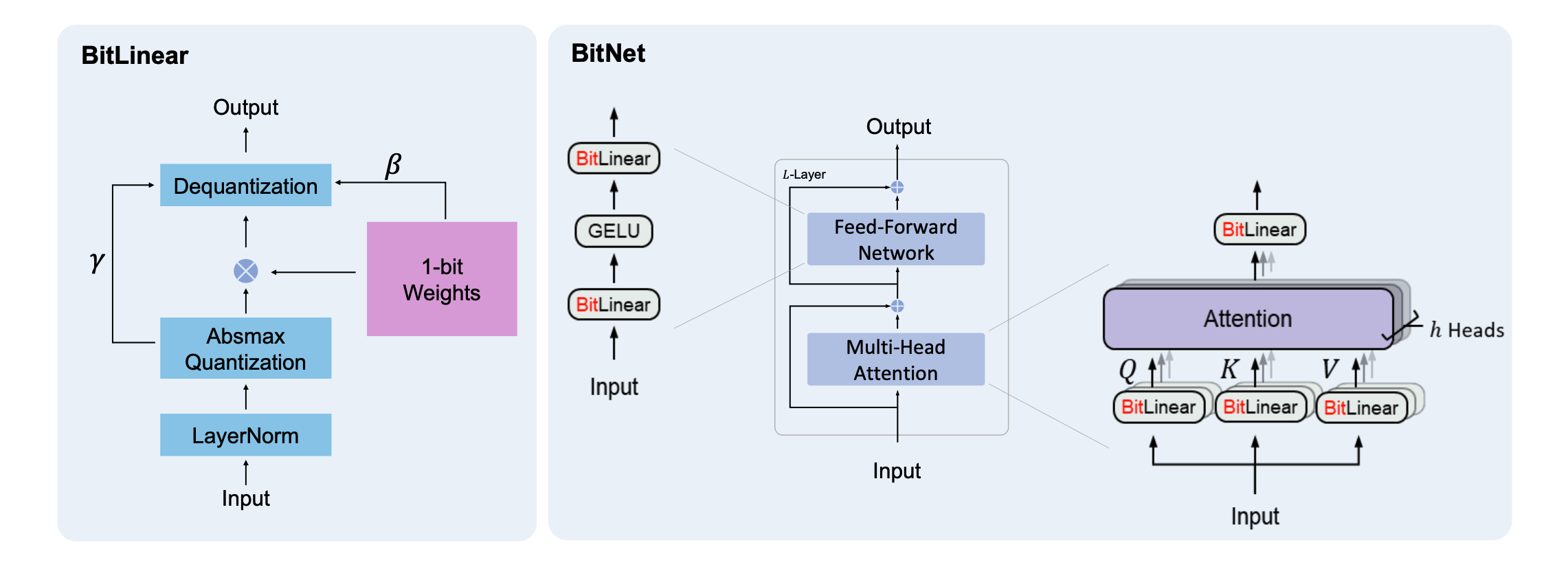
模型培训
本研究为 BitNet 培训引入了几项创新。现简要介绍如下。
吃水估计器(STE)
BitNet 包含几个不可微函数。因此,在梯度计算过程中,可以绕过这些函数,避免直接微分这些函数。这种方法在本研究中称为 STE。
混合精密践踏
BitNet 中的权重是量化的,但为了确保 BitNet 训练的稳定性和准确性,需要准备高精度变量来计算梯度和管理优化状态,并用这些变量来更新参数。在此过程中,会使用潜在权重进行计算。不过,这些潜在权重在前向传递过程中被二值化,不会在推理过程中使用。
混合精密践踏
训练 BitNet 所面临的一些挑战是,潜在权重的微小更新往往不会对单个比特变量产生任何影响。这就导致根据单比特权重计算的梯度和更新出现偏差。为解决这一难题,作者总结出最简单、最好的方法是提高学习率和加速优化。作者的实验证实,通过提高学习率,BitNet 在收敛性方面具有优势,而 FP16 类型的普通变换器即使在学习率相同的情况下,也会在学习开始时出现发散。这表明 BitNet 的学习效率高且稳定性强。
实验结果
计算效率
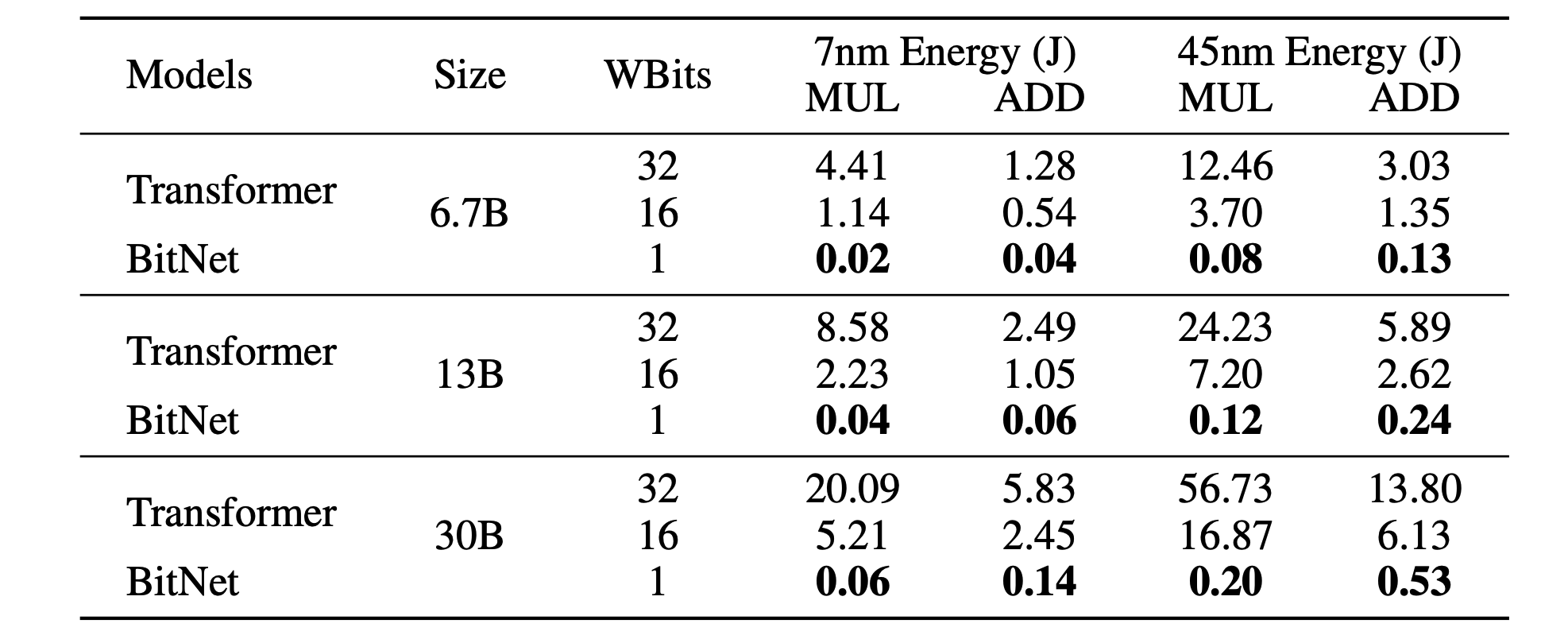
表 1 显示了普通 Transformer 和 BitNet 在能量方面的计算效率比较。结果表明,无论模型大小如何,BitNet 的效率都远远高于普通 Transformer。
考虑损失的比例规则
图 2 显示了 BitNet 和普通变压器的缩放规律随模型尺寸增大而变化的情况。重要的是,结果显示 BitNet 和普通变压器一样,随着模型尺寸的增大,根据缩放规律显示的损耗较小。此外,当模型大小或能耗保持不变时,将 BitNet 与普通变压器进行比较,可以发现 BitNet 的损耗更小。这表明,就能耗和模型大小而言,BitNet 比普通的 Trasformer 更为高效。另一个值得注意的重要方面是,BitNet 和普通变换器之间的误差随着模型大小的增加而减小。
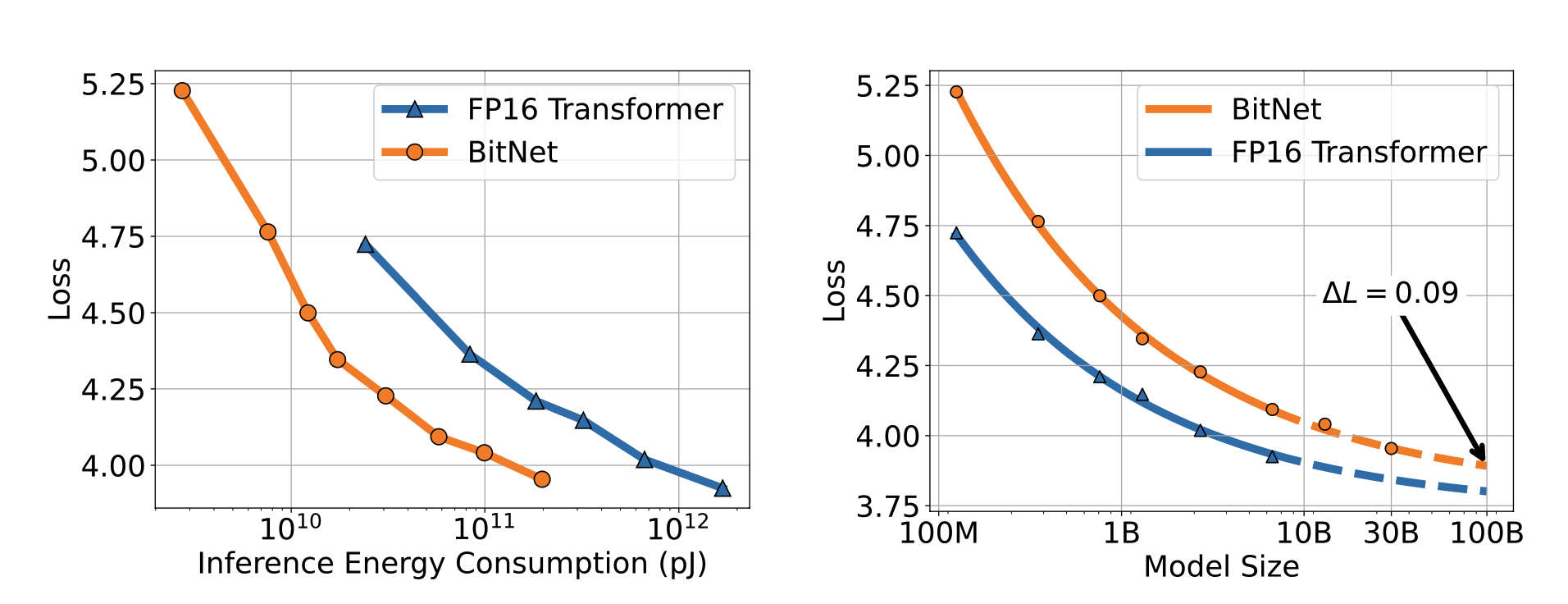
图 2:随着模型大小的增加,罗斯的缩放曲线可视化。
调查缩放定律的准确性
图 3 显示了 BitNet 和 Transformer 在精度方面的比较。结果表明,BitNet 的精确度更高,说明其效率更高。
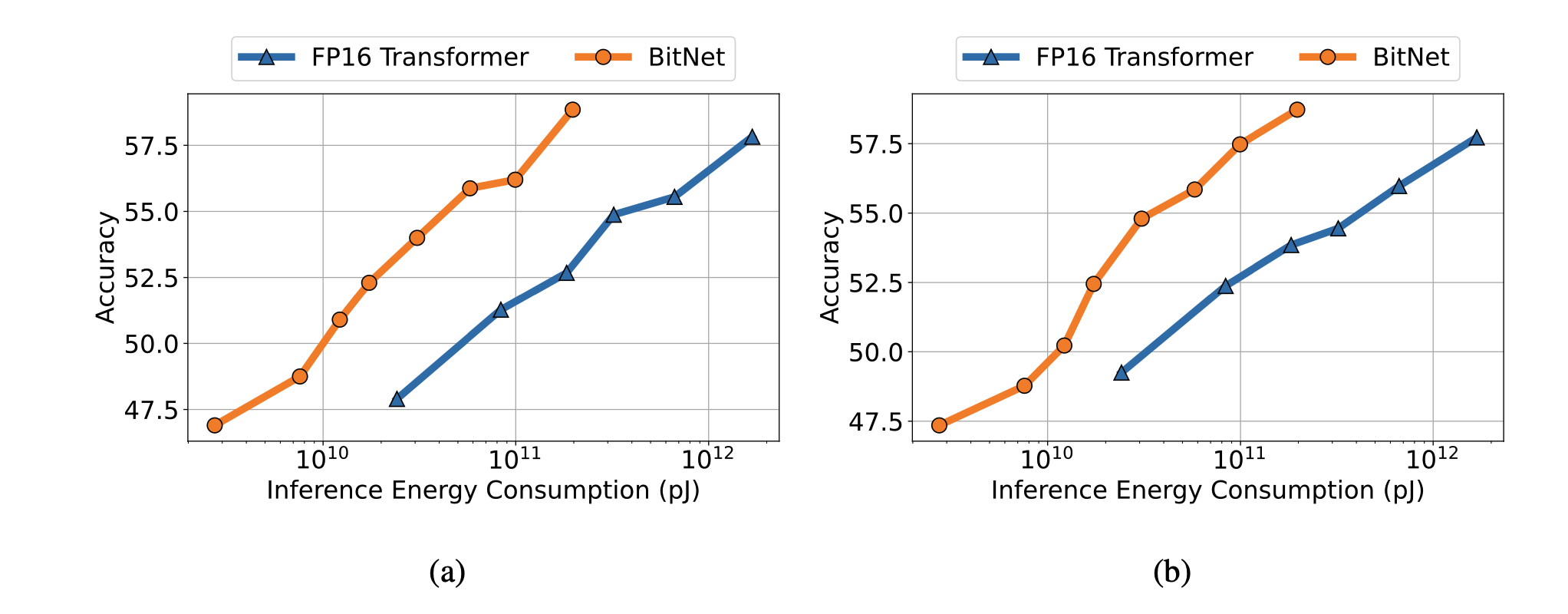
图 3:随着模型大小的增加,准确率的缩放曲线可视化。(a)和(b)分别显示了零次拍摄和四次拍摄任务的验证结果。
验证学习的稳定性
图 4(a) 显示了 BitNet 和 Transformer 的学习稳定性对比。这一结果表明,与普通 Transformer 相比,BitNet 的学习稳定性很高。图 4(b) 还显示了 BitNet 在不同学习率下的学习历史。这一结果证实了 BitNet 的高稳定性和高效性,无论学习率如何,它都能保持稳定。
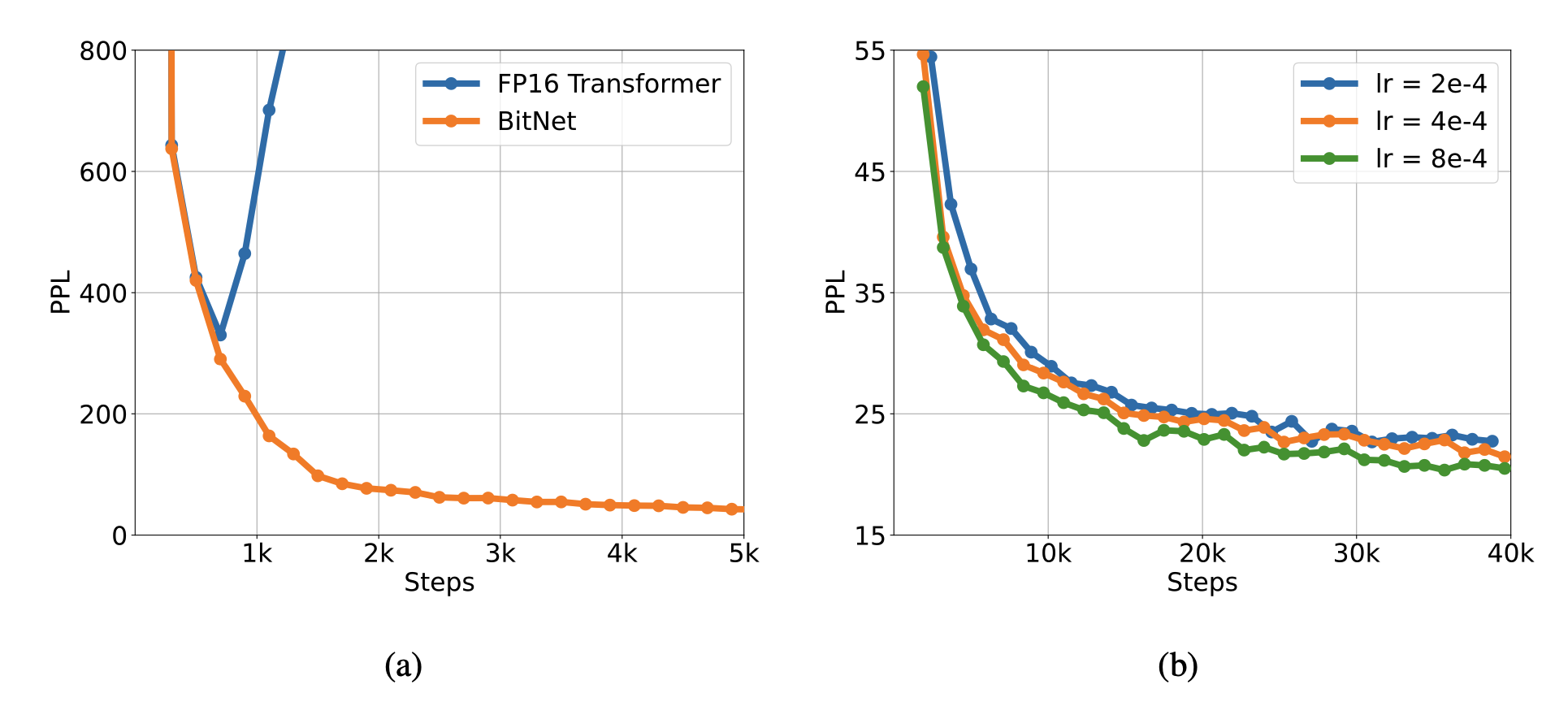
图 4.(a) BitNet 和 Transformer 在学习稳定性方面的比较。(b) BitNet 在几种学习率下的学习历史。
与传统的训练后模型量化进行比较
图 5 总结了 BitNet 和几种基线的精度比较。结果证实,与其他量化方法相比,BitNet 显示出很高的精确度。
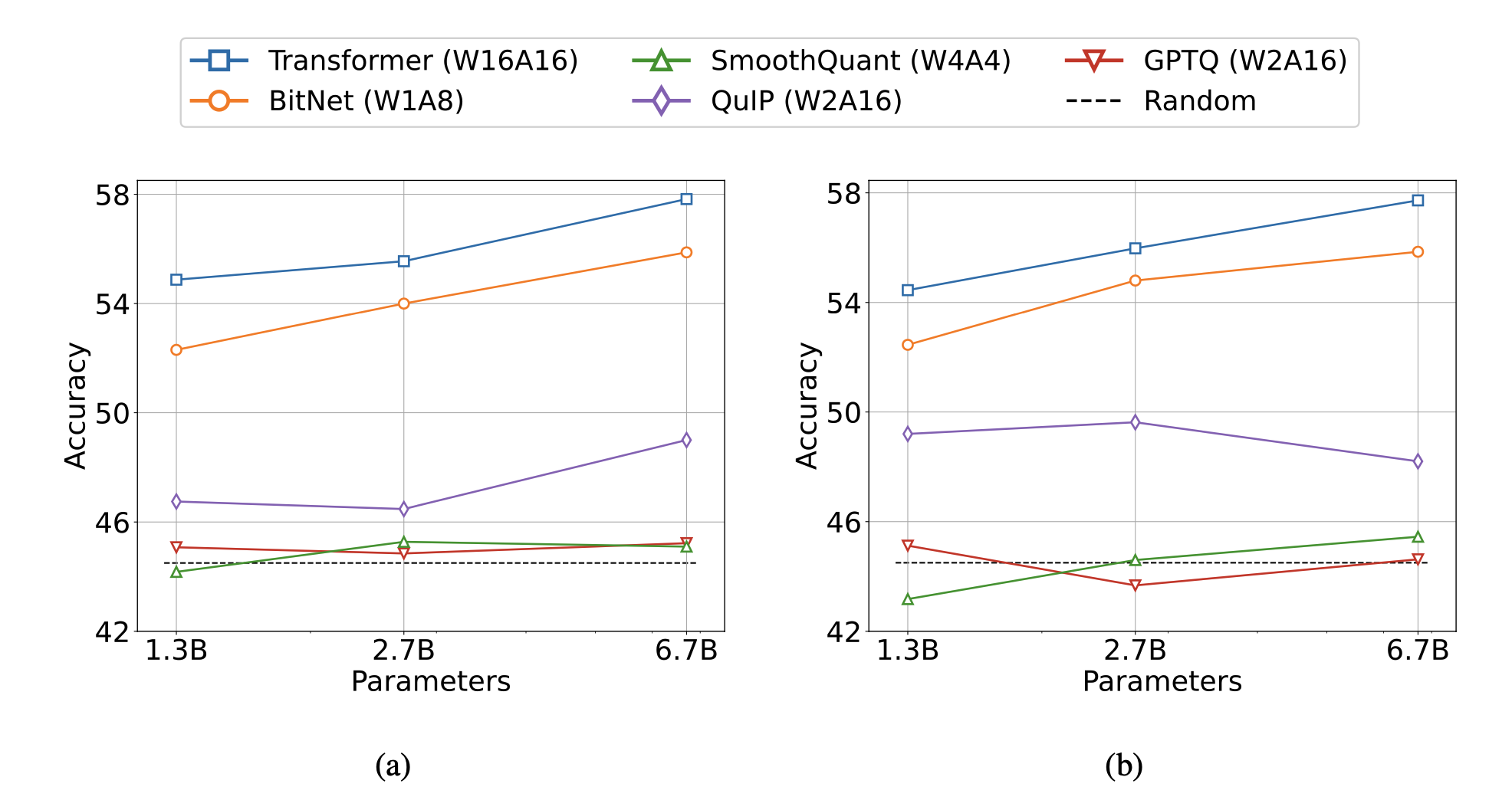
总结
本研究提出了一种基于单比特变换器的大规模语言模型。研究还全面比较了 BitNet 与传统量化方法和普通 Transformer,并讨论了它们之间的差异。结果表明,BitNet 可以实现比传统量化方法更高的效率和准确性。此外,其结果与普通 Transformer 的准确性不相上下,令人惊讶。未来,随着大规模语言模型变得更加庞大,研究模型量化方法的重要性预计会增加,而 BitNet 被认为有潜力成为这一领域的领导者。从这个意义上讲,我们期待着进一步讨论该模型的通用性和应用限制。



















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











