




导言
论文地址:https://arxiv.org/pdf/2303.14524.pdf
在当前的大数据时代,当我们搜索或选择产品时,推荐系统被广泛使用。
由于不可能从无数产品组中手动搜索产品,因此需要一个能自动提取和推断用户偏好并据此推荐优质产品的系统。
然而,在模型设计和数据分布偏差方面仍存在各种问题。
例如,缺乏用户友好性,如互动性和可解释性;冷启动问题,降低了对新用户和新项目推荐的准确性;以及跨产品领域推荐的困难。
如今风靡全球的大型语言模型(LLM)有望解决这些问题。
这是因为 LLM 提供了清晰的描述,可以处理跨产品领域的跨领域信息,充分利用其内部掌握的大量信息。
此外,法律硕士还善于与用户互动,这可以改善用户体验。
本文介绍了一种利用上下文学习将 LLM 扩展为推荐系统的方法,无需训练。
算法实现
连接推荐系统和 LLM
传统的推荐系统通过从点击历史和购买历史等用户数据中提取用户偏好来进行推荐。
另一方面,自然语言处理技术显然具有扩展推荐系统的潜力,它可以从评论和 SNS 帖子等基于文本的内容以及文本中的自然回复中提取用户偏好。
在本文中,我们提出了一个基于 ChatGPT 的推荐系统 Chat-REC,该系统可以同时跟踪这两种信息流。
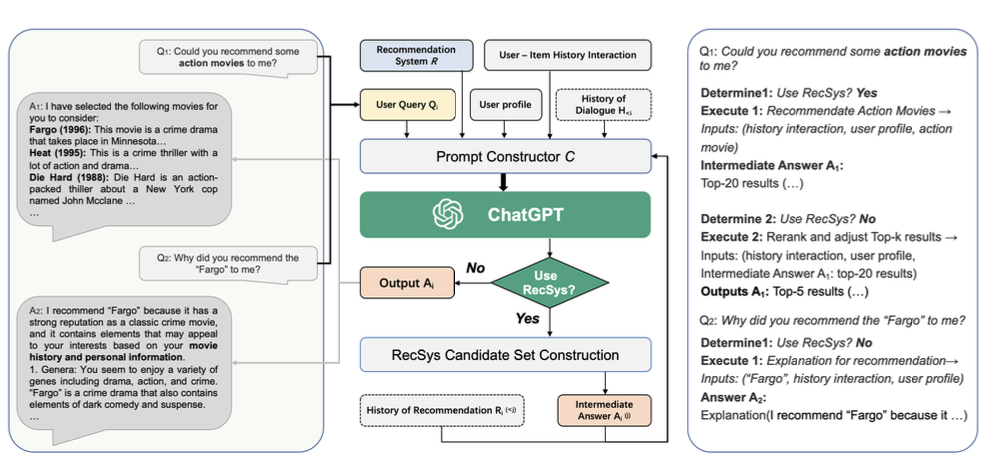
Chat-REC 是用户与商品之间的交互历史(= 用户对商品的反应历史,如点击、购买、评价等)。它与推荐系统 R 相连,推荐系统将用户资料(= 年龄、性别、地点、兴趣等)、用户查询(= 描述请求的输入文本)Q 和对话历史记录 H 作为输入,并推荐候选项目。
提示构建模块 C 汇总输入信息并生成提示。
当判断查询 Q 指定的任务为推荐任务时,调用推荐系统 R 生成一组候选推荐项作为中间答案,输入提示符生成回答文本;当判断该任务不是推荐任务时,ChatGPT 直接进行回答。当确定任务不是推荐任务时,ChatGPT 直接回复。
缩小候选人范围
在传统的推荐系统中,产品会从无数产品中排序,并根据推荐可靠性的评分结果呈现给用户,但当大量产品同时呈现时,用户会不知所措。
在本文中,我们提出了一种利用 LLM 的情境学习能力来缩小候选产品范围的方法。
首先,在提示符中输入用户的个人资料和以往的互动情况,要求 LLM 总结用户的偏好。
一旦通过这种方式获得了产品属性与用户偏好之间关系的知识,就可以接收由推荐系统创建的候选推荐项目集,然后根据用户的偏好对其进行过滤和重新排序,并呈现出更优化的候选项目集。然后,就可以向用户提供一套更加优化的候选项目。
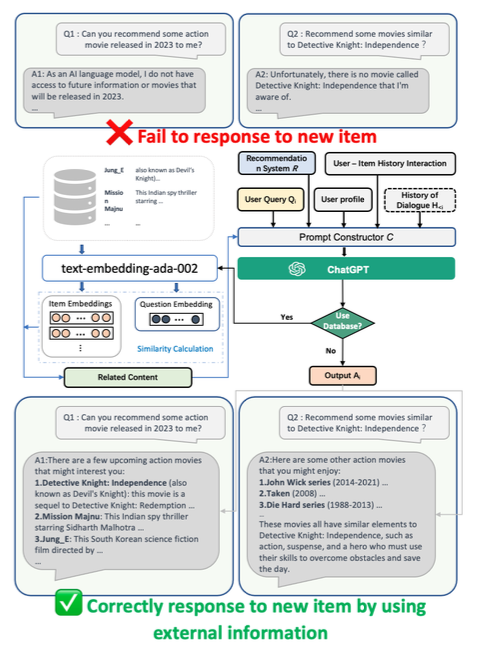
对新项目的回应
LLM 用于训练的数据集有时间限制,通常不包含最新信息。
因此,如果用户要求推荐最新的项目,上述方法就无法应对。
一个可行的解决方案是提前在数据库中存储有关新项目的数据,并在要求推荐最新项目时加以参考。
具体来说,对推荐项目的文本进行编码,将嵌入式表达式存储在数据库中,并根据与请求文本中嵌入式表达式的相似度,将高度相关的项目信息引入提示。
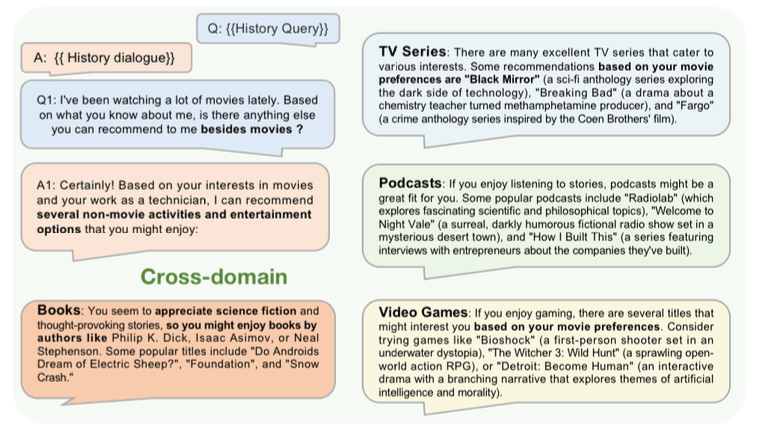
跨产品领域的建议
LLM 是根据互联网上的大量数据进行训练的,被认为是一个具有多种视角的知识库。
因此,就像下面的例子,在推荐一部电影之后,还可以继续推荐其他领域的产品,如书籍或电视节目。
测试与实验
数据集和实验装置
使用 MovieLens 100K 影评数据集。
该数据集包含来自 943 位用户的数据,他们对 1682 部电影进行了 1-5 分的评分。
它包含每个用户的人口统计信息(如年龄、性别、职业)和电影属性(如片名、上映年份、类型)。
本次实验随机抽取了 200 名用户。
精度(Precision)、召回率(Recall)和归一化贴现累积收益(NDCG)指标用于评估推荐的性能,而均方根误差(RMSE)和平均绝对误差(MAE)指标用于评估评估和预测任务的性能。而均方根误差(RMSE)和平均绝对误差(MAE)则用于评估评估和预测任务的性能。
对比
以下四种经典推荐系统模型可供比较
LightFM:一种结合了协同过滤法(一种基于项目与用户关系的推荐方法)和基于内容的方法(一种基于项目信息的推荐方法)的方法。
LightGCN:一种基于图的协同过滤方法。用图卷积网络来近似用户与项目之间的关系。
Item-KNN:基于 KNN 的协同过滤方法。
矩阵因式分解(MF):一种协同过滤方法,可将用户与项目之间的关系压缩到较低维度。
ChatGPT 使用了三种骨干模型:gpt-3.5-turbo、text-davinci-003 和 text-davinci-002。
结果
五大建议
使用以下提示

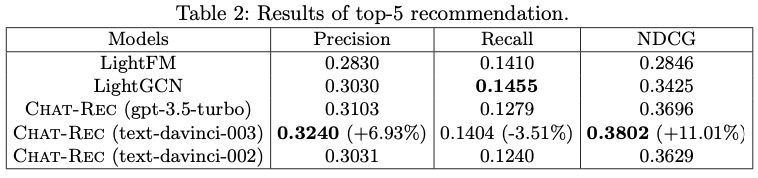
推荐前五名的准确率如下
可以看出,拟议的 Chat-REC 方法在精确度和 NDCG 方面都是最好的,但在 Recall 方面,传统方法优于 Chat-REC。
评级预测
使用以下提示

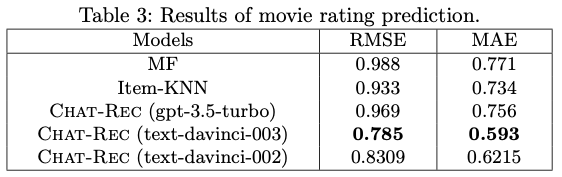
在预测评级值的任务中,结果如下
可以看出,拟议的 Chat-REC 方法性能最佳。
结果表明,LLM 能够仅通过上下文学习提取用户偏好并准确预测评分。
另一方面,可以看出 gpt-3.5-turbo 作为 ChatGPT 的骨干模型时准确性较低。
这可能是由于 gpt-3.5-turbo 强调了与人互动的能力,并对情境中的学习能力进行了权衡,这与其他研究的结果是一致的。
总结
本文提出了一个Chat-REC 模型,通过在提示中输入用户信息和用户-物品交互信息,将 LLM 与推荐系统连接起来,从而实现有效推荐。
在互动性、可解释性和产品领域间推荐方面,LLM 似乎具有提高推荐性能的潜力。
预计推荐系统的性能将得到进一步提高,从而为我们在日常生活中选择产品时提供更流畅、更舒适的用户体验。



















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











