




1. 概述
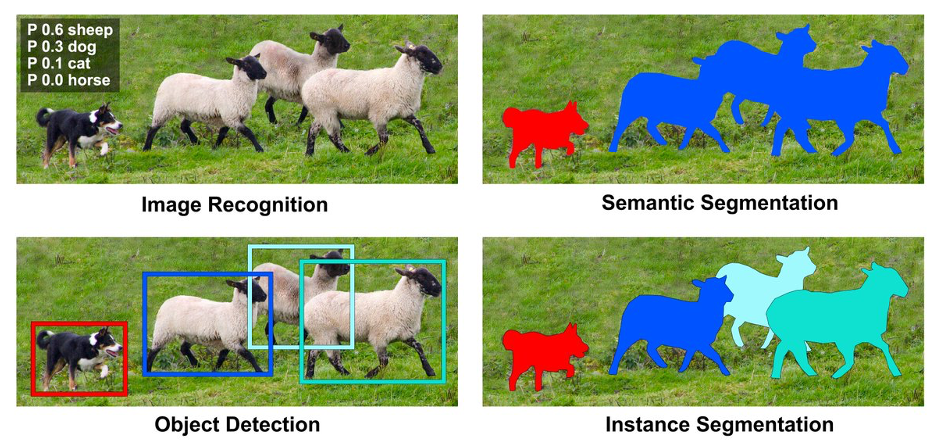
实例分割是一种先进的计算机视觉技术,它不仅能够识别图像中的特定细胞类型,还能精确地定位每个细胞实例的具体位置,并绘制出其边界。这种技术对于医学图像分析尤其重要,因为它可以帮助医生和研究人员更准确地识别和量化图像中的细胞,从而在疾病诊断和科学研究中发挥关键作用。
在这篇文章中,我们将探讨如何使用Ultralytics——一个流行的深度学习推理框架,来微调YOLOv9模型以进行实例分割任务。YOLOv9是一种最新的目标检测模型,以其高速和高准确率而闻名。我们将在自定义的医学数据集上对其进行微调,这意味着我们将使用特定于医学领域的图像来训练模型,以便它能够更好地理解和识别医学图像中的细节。
2.实例分割
实例分割是通过为图像中每个像素分配到特定类别的同时,为每一个单独的对象像素赋予一个独一无二的标识符,从而实现对个体对象的精确区分。与之相对的语义分割,虽然也对图像内每个像素进行类别划分,但并不区分同一类别内不同对象间的差异,即同一类别内的所有像素会被赋予相同的标签。
实例分割的这种能力使其在需要精细区分对象轮廓、考量对象间空间分布以及识别个体对象身份的场景中显得尤为重要。因此,实例分割技术实际上是对象检测(确定对象类别)与像素级分类(精细区分对象个体)的结合体,为计算机视觉领域提供了更为丰富和细致的图像解析手段。
3. YOLOv9实例分割
对于像YOLO和SSD这样的轻量级模型,在前向传递过程中存在信息降级的风险。因为,信息丢失主要是由于它们架构中使用的下采样操作引起的。
这些模型通过池化和步幅卷积迅速减小空间维度,将输入图像压缩成紧凑的特征表示。虽然这有助于增加接受域并减少计算成本,但它导致了对检测小的和密集堆积的对象至关重要的细粒度细节的丢失。
为了解决这个问题,YOLOv9利用广义高效层聚合网络(GELAN)实现了优越的参数利用和计算效率。YOLOv9主要专注于使用可编程梯度信息(PGI)和可逆函数解决深度神经网络中的信息丢失问题。
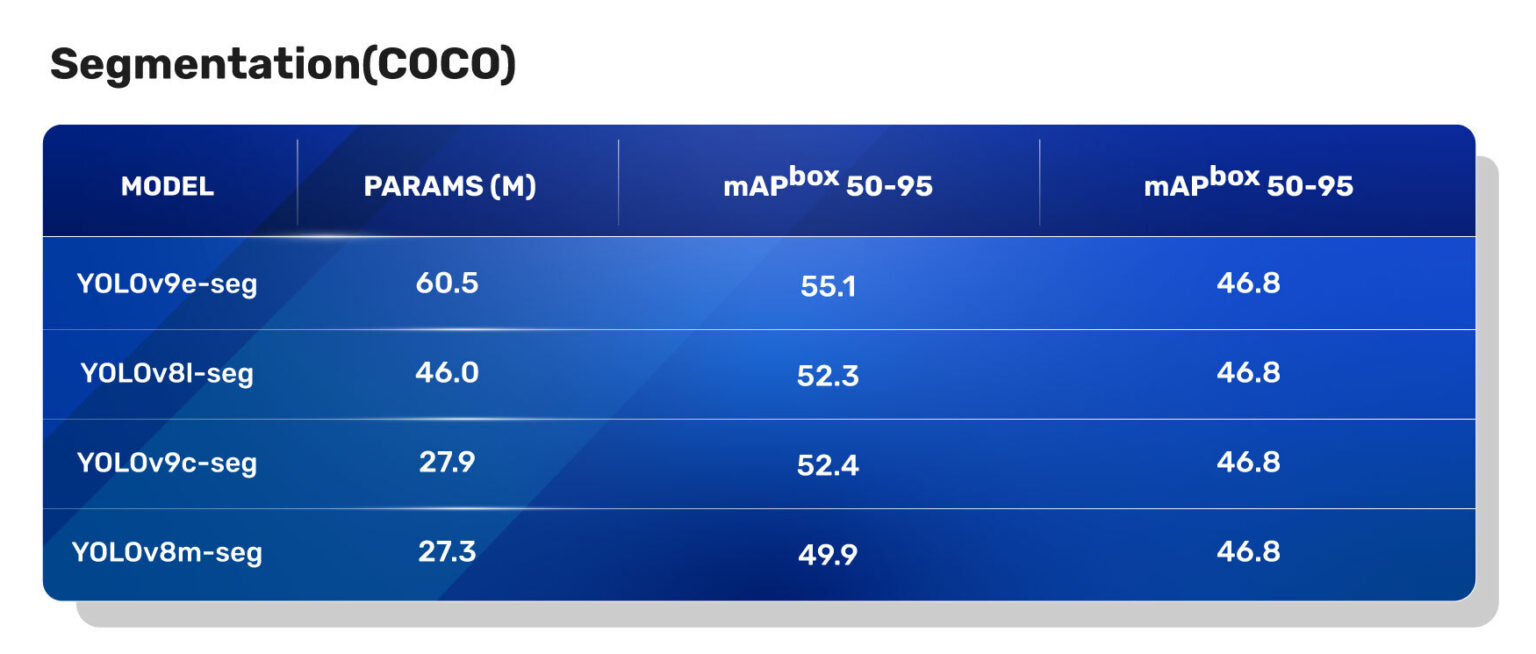
从这个表格中,很明显YOLOv9实例分割模型在COCO分割任务上的mAP有了显著的改进,与YOLOv8分割模型相比。
4. Nuclei数据集
Nuclei实例分割数据集:可视化
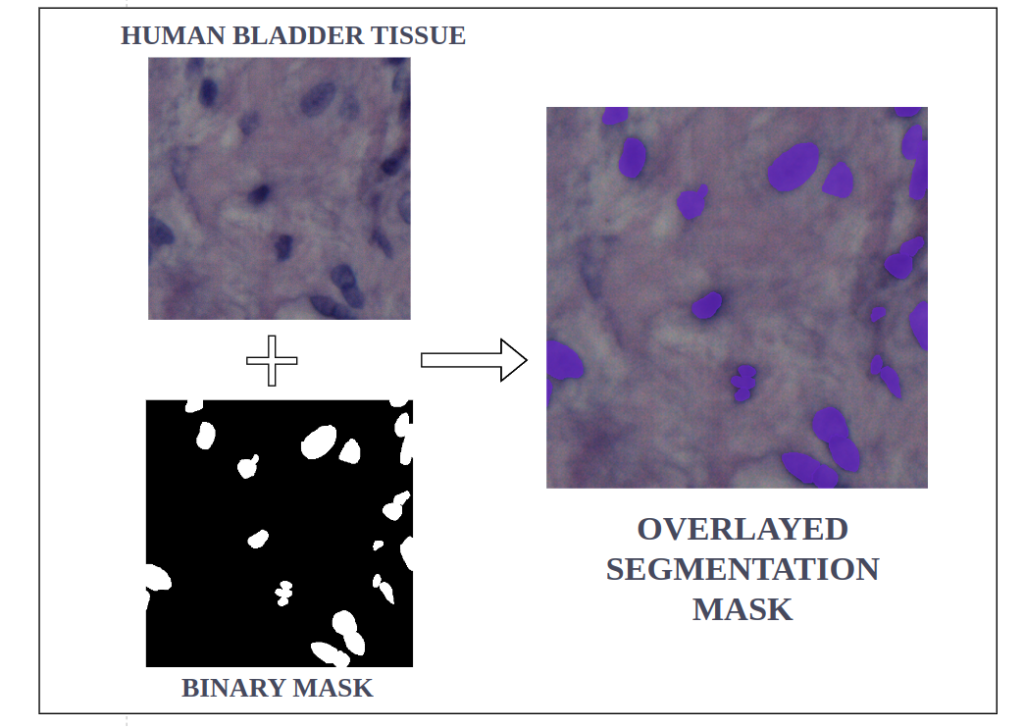
在提升模型对于不同成像技术泛化能力的过程中,医学领域的专业知识扮演着一个至关重要的角色。这种能力的提升得益于精心策划的高质量标注数据集,以及在模型训练和评估阶段专家的悉心指导。
基于此,我们将采用一个高水准的医学数据集——NuInsSeg Kaggle数据集。该数据集囊括了来自31种人和小鼠器官的超过30,000个手动分割的细胞核,以及从H&E染色的全幻灯片显微镜图像中提取的665个图像块。
这个数据集涵盖了多样的人和小鼠器官组织,包括但不限于小脑、肾脏、肝脏、胰腺等关键器官。数据集中仅包含一个类别,即Nuclei,共包含665张图像。我们将按照80:20的比例将其划分为训练集和验证集。经过划分,最终得到的训练集包含532张图像,验证集则包含133张图像。为了便于处理,所有图像都被调整为统一的尺寸,即512 x 512像素。
5.模型训练
5. 1 环境安装
YOLOv9实例分割模型已经集成到Ultralytics包中。直接pip安装就可以使用:
conda create --name yolov9 python==3.10
activate yolov9
pip install -q ultralytics pycocotools scikit-learn matplotlib
5.2 数据集处理
数据集转换为YOLO格式所需的格式。pycocotools解析COCO中的注释,scikit-learn将数据集分割为训练和验证。
import os
import copy
import random
import json
import yaml
import glob
import cv2
import numpy as np
import time
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import requests
from zipfile import ZipFile
import argparse
from PIL import Image
import PIL.Image
import shutil
from IPython.display import Image
from sklearn.model_selection import train_test_split
import torch
import torch.utils.data
from torch import nn
import torchvision
from torchvision import transforms as T
from ultralytics import YOLO
from pycocotools import mask as coco_mask
from pycocotools.coco import COCO
设置随机种子:
def set_seeds():
# 固定随机种子
SEED_VALUE = 42
random.seed(SEED_VALUE)
np.random.seed(SEED_VALUE)
torch.manual_seed(SEED_VALUE)
if torch.cuda.is_available():
torch.cuda.manual_seed(SEED_VALUE)
torch.cuda.manual_seed_all(SEED_VALUE)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
set_seeds()
5.2.1 下载数据集
这个函数块用于下载并解压指定目录中的数据集。
def download_and_unzip(url, save_path, extract_dir):
print("Downloading assets...")
file = requests.get(url)
open(save_path, "wb").write(file.content)
print("Download completed.")
try:
if save_path.endswith(".zip"):
with ZipFile(save_path, 'r') as zip_ref:
zip_ref.extractall(extract_dir)
print("Extraction Done")
except Exception as e:
print(f"An error occurred: {e}")
DATASET_URL = r"https://www.dropbox.com/scl/fi/u83yuoea9hu7xhhhsgp4d/Nuclei_Instance_Seg.zip?rlkey=7tw3vs4xh7rych4yq1xizd8mh&dl=1"
DATASET_DIR = "Nuclei-Instance-Dataset"
DATASET_ZIP_PATH = os.path.join(os.getcwd(), f"{DATASET_DIR}.zip")
# 如果数据集不存在,则下载并提取。
if not os.path.exists(DATASET_DIR):
os.makedirs(DATASET_DIR, exist_ok=True) # 确保目录存在
download_and_unzip(DATASET_URL, DATASET_ZIP_PATH, DATASET_DIR)
os.remove(DATASET_ZIP_PATH) # 提取后删除zip文件
5.2.2移除不需要的目录
数据集带有多个子目录。然而,对于YOLOv9实例分割微调,只需要原始图像和标记的掩码,并将它们转换为适当的格式。
def prune_subdirectories(base_dir, keep_dirs):
# 在基础目录中迭代每个子目录
for root_dir in os.listdir(base_dir):
root_path = os.path.join(base_dir, root_dir)
if os.path.isdir(root_path):
# List all subdirs inside the current root dir
for sub_dir in os.listdir(root_path):
sub_path = os.path.join(root_path, sub_dir)
# 如果子目录不在保留列表中,则删除它
if os.path.isdir(sub_path) and sub_dir not in keep_dirs:
# print(f"Deleting: {sub_path}")
shutil.rmtree(sub_path)
elif os.path.isdir(sub_path):
# print(f"Keeping: {sub_path}")
pass
base_directory = "./Nuclei-Instance-Dataset"
directories_to_keep = ['tissue images', 'mask binary without border', 'label masks modify']
prune_subdirectories(base_directory, directories_to_keep)
只保留包含子目录名称为‘tissue images’、‘mask binary without border’和‘label masks modify’的目录。
修剪后数据集树将如下所示:
Nuclei-Instance-Dataset
├── human bladder
│ ├── label masks modify
│ └── tissue images
├── human brain
│ ├── label masks modify
│ └── tissue images
├── human cardia
│ ├── label masks modify
│ └── tissue images
├── human cerebellum
│ ├── label masks modify
│ └── tissue images
├── …
│ ├── label masks modify
│ └── tissue images
└── mouse thymus
├── label masks modify
└── tissue images
接下来,把标签二值掩码转换为YOLO txt格式。但要先将标签转换为COCO JSON格式,才能转成YOLO txt格式。
5.2.3 分割函数
get_image_mask_pairs()返回数据集中所有图像mask标签的列表。
def get_image_mask_pairs(data_dir):
image_paths = []
mask_paths = []
for root, _, files in os.walk(data_dir):
if 'tissue images' in root:
for file in files:
if file.endswith('.png'):
image_paths.append(os.path.join(root, file))
mask_paths.append(os.path.join(root.replace('tissue images', 'label masks modify'),
file.replace('.png', '.tif')))
return image_paths, mask_paths
二进制mask标签是表示分割任务中对象注释的常见方式。它们在像素级别有效地编码对象的形状。然而,将这些掩码转换为多边形对于可视化或计算对象属性等任务通常是有益的。mask_to_polygons()展示了从二进制掩码中提取多边形的一种方法。
def mask_to_polygons(mask, epsilon=1.0):
contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
polygons = []
for contour in contours:
if len(contour) > 2:
poly = contour.reshape(-1).tolist()
if len(poly) > 4: # 确保有效的多边形
polygons.append(poly)
return polygons
为了将组织的二进制掩码转换为可以操作的多边形点,我们将采用OpenCV库中的cv2.findContours函数。这个函数能够从二进制掩码中提取出近似的多边形轮廓,确保我们获得一个有效的闭合多边形,其边数超过四条,并且能够精确地围绕掩码的边缘轮廓。
在编写代码以实现这一功能时,我们需要首先读取二进制掩码图像,并使用cv2.findContours函数来定位所有的轮廓。然后,我们将选择合适的轮廓(通常是最外层的轮廓)来表示每个对象,并忽略那些代表同一对象内部结构的子轮廓。这样,我们就能得到一组精确描述每个对象形状的多边形点,为后续的图像分割和分析工作打下坚实的基础。
5.2.4 YOLO注释格式
在YOLO实例分割格式中,注释存储在与每个图像对应的单独.txt文件中,图像文件和注释文件共享相同的基本文件名。
例如,图像human_kidney01.png应该有匹配的注释文件命名为human_kidney01.txt。
.txt文件中的每行对应于在该相关图像文件中找到的单个对象实例。
每行包含有关实例的以下信息:
对象类别索引:指对象类别索引的整数(例如,0代表Nuclei)。
对象边界坐标:这些是围绕对象分割区域的归一化边界坐标,确保注释可以在不同尺寸的图像中进行缩放。
因此,.txt文件中的每行看起来像这样:
…
5.3 数据集准备
process_data实用程序将初始化注释和图像为空列表,所有元数据将附加到这些列表中。此外,图像ID和注释ID的初始值为零。
接下来,同时迭代通过get_image_mask_pairs实用函数获得的image_paths和mask_path列表。对于每张图像,分配一个唯一的image_id,在每次迭代后加1。然后,使用OpenCV读取图像和掩码。cv2.IMREAD_UNCHANGED有助于读取掩码,包括(如果存在)alpha通道。
首先,将每张图像的基本信息(如image_id, width、height、filename等)分配为字典,并将其附加到图像列表中。
def process_data(image_paths, mask_paths, output_images_dir, output_labels_dir):
annotations = []
images = []
image_id = 0
ann_id = 0
for img_path, mask_path in zip(image_paths, mask_paths):
image_id += 1
img = cv2.imread(img_path)
mask = cv2.imread(mask_path, cv2.IMREAD_UNCHANGED)
shutil.copy(img_path, os.path.join(output_images_dir, os.path.basename(img_path)))
# 将图像添加到列表
images.append({
"id": image_id,
"file_name": os.path.basename(img_path),
"height": img.shape[0],
"width": img.shape[1]
})
unique_values = np.unique(mask)
5.3.1 mask到多边形
这里利用np.unique(mask)函数来识别掩码图像中的不同像素值,这一步骤是划定掩码内不同对象的关键。通过这个函数,可以准确地找到图像中所有不重复的像素值,为每个对象的识别奠定基础。
随后,代码通过一个循环遍历这些唯一值,对每个值进行单独处理。在这个过程中,背景值——通常代表图像中的空白或非对象区域——会被忽略,以聚焦于实际的对象像素。
对于每个非背景的唯一值,代码会创建一个新的二进制掩码。在这个二进制掩码中,所有与当前唯一值相对应的像素点会被标记为255(白色),这样的设置使得每个对象实例在图像中清晰可见,同时将它们与背景区分开来。
相对地,所有其他非对象像素则被设置为0(黑色),这一步骤有效地将对象从背景中分离,为后续的多边形提取和对象识别提供了清晰的二进制图像。
一旦形成了突出显示对象的二进制掩码,它就会被传递给mask_to_polygons()函数。该函数的任务是处理这些掩码,并从中提取出一系列的多边形。这些多边形准确地描述了对象的轮廓,为进行实例分割提供了必要的几何信息。
for value in unique_values:
if value == 0: # 忽略背景
continue
object_mask = (mask == value).astype(np.uint8) * 255
polygons = mask_to_polygons(object_mask)
for poly in polygons:
ann_id += 1
annotations.append({
"image_id": image_id,
"category_id": 1, # 只有一个类别:Nuclei
"segmentation": [poly],
})
每个多边形都勾勒出掩码内对象的周长,为准确的实例分割提供必要的数据。现在,迭代地为每个多边形分配一个唯一的ann_id。将分割任务所需的注释信息作为字典附加到注释列表中。
5.3.2 COCO到YOLO格式转换
coco_input = {
"images": images,
"annotations": annotations,
"categories": [{"id": 1, "name": "Nuclei"}]
}
地将COCO注释转换为YOLOv9实例分割格式。
# 将COCO-like字典转换为YOLO格式
for img_info in coco_input["images"]:
img_id = img_info["id"]
img_ann = [ann for ann in coco_input["annotations"] if ann["image_id"] == img_id]
img_w, img_h = img_info["width"], img_info["height"]
if img_ann:
with open(os.path.join(output_labels_dir, os.path.splitext(img_info["file_name"])[0] + '.txt'), 'w') as file_object:
for ann in img_ann:
current_category = ann['category_id'] - 1
polygon = ann['segmentation'][0]
normalized_polygon = [format(coord / img_w if i % 2 == 0 else coord / img_h, '.6f') for i, coord in enumerate(polygon)]
file_object.write(f"{current_category} " + " ".join(normalized_polygon) + "\n")
这样,对于每张图像,创建一个对应的.txt注释文件,提取category_id,并在循环中提取当前对象实例的polygon。然后将多边形相对于当前图像尺寸进行归一化。因此,为输出标签目录中的所有图像创建一组.txt文件,这些文件将在微调期间使用。
5.4 准备 data.yaml
将在**data.yaml**文件中转储所需的数据集,以适应任何YOLO模型的训练似集。此文件包含训练、验证和测试图像目录的路径,以及数据集中类别的names和类别数量。
def create_yaml(output_yaml_path, train_images_dir, val_images_dir, nc=1):
# 假设所有类别相同,且只有一个类别,'Nuclei'
names = ['Nuclei']
# 创建一个包含所需内容的字典
yaml_data = {
'names': names,
'nc': nc, # 类别数量
'train': train_images_dir,
'val': val_images_dir,
'test': ' '
}
# 将字典写入YAML文件
with open(output_yaml_path, 'w') as file:
yaml.dump(yaml_data, file, default_flow_style=False)
数据集目录应具有以下树状结构:
yolov9_1024_dataset
├── train
│ ├── images
│ │ ├── human_kidney01.png
│ │ └── ...
│ └── labels
│ ├── human_kidney01.txt
│ └── ...
└── val
├── images
│ ├── human_kidney01.png
│ └── ...
└── labels
├── human_kidney01.txt
└── ...
现在,yolo_dataset_preparation()函数定义了所有路径,然后调用所需的一组实用函数。简单来说,这个函数负责从原始二进制掩码中提取多边形并将其转换为YOLO格式。最后,它为YOLOv9实例分割微调创建一个data.yaml文件。
def yolo_dataset_preparation():
data_dir = 'Nuclei-Instance-Dataset'
output_dir = 'yolov9e_1024_dataset'
# 定义训练和验证的图像和标签的路径
train_images_dir = os.path.join(output_dir, 'train', 'images')
val_images_dir = os.path.join(output_dir, 'val', 'images')
train_labels_dir = os.path.join(output_dir, 'train', 'labels')
val_labels_dir = os.path.join(output_dir, 'val', 'labels')
# 如果输出目录不存在,则创建它们
os.makedirs(train_images_dir, exist_ok=True)
os.makedirs(val_images_dir, exist_ok=True)
os.makedirs(train_labels_dir, exist_ok=True)
os.makedirs(val_labels_dir, exist_ok=True)
# 获取图像和掩码路径
image_paths, mask_paths = get_image_mask_pairs(data_dir)
# 将数据分割为训练和验证
train_img_paths, val_img_paths, train_mask_paths, val_mask_paths = train_test_split(image_paths, mask_paths, test_size=0.2, random_state=42)
# 以YOLO格式处理并保存训练和验证数据
process_data(train_img_paths, train_mask_paths, train_images_dir, train_labels_dir)
process_data(val_img_paths, val_mask_paths, val_images_dir, val_labels_dir)
# 假设create_yaml函数在其他地方定义,并为YAML文件设置适当的路径
output_yaml_path = os.path.join(output_dir, 'data.yaml')
train_path = os.path.join('train', 'images')
val_path = os.path.join('val', 'images')
create_yaml(output_yaml_path, train_path, val_path)
yolo_dataset_preparation()
5.5 YOLOv9实例分割模型设置
Ultralytics包中有两种YOLOv9实例分割模型。
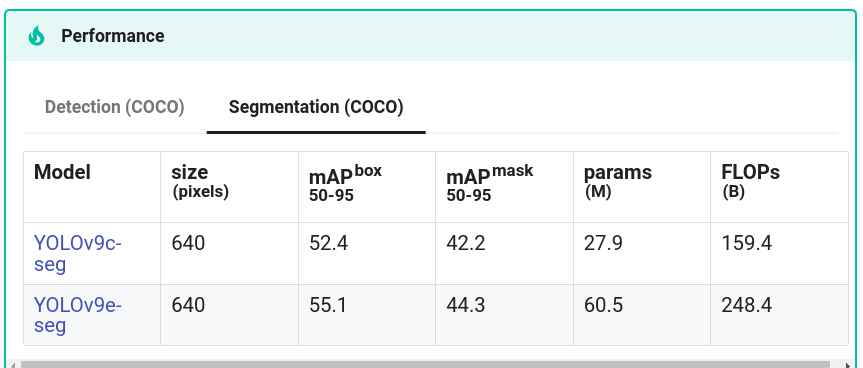
接下来,将微调YOLOv9e-seg和YOLOv9c-seg,并将其与等效参数大小的YOLOv8l-seg和YOLOv8m-seg模型进行比较,分别针对不同的图像尺寸。
# 实例
model = YOLO("yolov9e-seg.yaml") # 从YAML构建模型
model = YOLO("yolov9e-seg.pt") # 从预训练模型传输权重
在这个里,将使用在COCO数据集上预训练的YOLOv9e-seg模型权重,所有层都未冻结。
然而,也可以尝试,
- YOLOv9实例分割: 部分冻结层的微调 ——
- 冻结模型的主干层,这些层负责可生成的特征提取,并且只解冻专门用于分割的YOLOv9-seg头部层。
- YOLOv9实例分割: 迁移学习 ——
- 完全冻结预训练的YOLOv9e-seg模型,并且只训练特定于数据集的最终头部层,以进行分割任务。
下面的代码片段读取data.yaml并获取训练数据集的类别数量。
with open("yolov9e_1024_dataset/data.yaml",'r') as stream:
num_classes = str(yaml.safe_load(stream)['nc'])
5.6 模型训练
# 定义项目 -> 所有结果的目标目录
project = "yolov9e_1024_dataset/results"
# 定义这次特定训练的子目录
name = "70_epochs-"
ABS_PATH = os.getcwd()
模型70个周期左右,并将训练日志保存到指定的项目目录中。
# 训练模型
results = model.train(
data = os.path.join(ABS_PATH, "yolov9e_1024_dataset/data.yaml"),
project = project,
name = name,
epochs = 70,
patience = 0 , # 设置patience=0以禁用提前停止,
batch = 3,
imgsz=1024
)
这里将采用model.train()方法将模型置于训练模式。针对我们的YOLOv9e-seg模型,我们将设定批量大小为3,同时将图像尺寸调整为1024像素,这样的参数配置旨在确保模型能够适应于GPU的内存限制。
注意:在训练过程中,如果遇到CUDA内存不足(OOM,即Out of Memory)的错误提示,建议通过减小批量大小或者降低图像的尺寸来释放GPU内存,从而有效地利用可用的硬件资源。
此外,为了最大化模型在准确性或损失最小化方面的性能表现,我们将patience参数设置为0,这一设置将关闭提前停止功能。提前停止是一种常用的技术,用于在模型验证性能不再提升时终止训练过程,以避免过拟合。然而,在此处,我们选择禁用这一功能,以便让模型完成全部的训练周期,确保充分的训练效果。
通过这些步骤,我们可以确保YOLOv9e-seg模型在进行实例分割任务时,能够获得最佳的训练效果,从而在图像中精确地识别和定位各个对象。这种精细的调整对于实现高效的目标检测和图像分割至关重要,特别是在处理复杂场景或高分辨率图像时。
5.7 训练配置
硬件配置
- 高端配置: NVIDIA RTX 4090 GPU(24 GB VRAM)和 AMD Ryzen 7532 32核128线程 CPU,这种配置适合进行大规模的并行计算和处理复杂的模型训练任务。
- Colab 免费服务器:使用 Intel Xeon® @2.00GHz 的 CPU,单核2线程,对于免费的在线平台来说,已经提供了不错的计算能力。但与高端硬件相比,它在处理大规模并行任务时可能会有性能限制。
Colab T4 GPU 优化建议 - 批量大小:由于 T4 GPU 的内存和计算能力有限,建议将批量大小减小到 4,以避免内存溢出和提高训练稳定性。
- 图像尺寸:将图像尺寸减小到 640x640,可以减少计算负担,加快训练速度。
训练监控 - Ultralytics 训练日志:这些日志可以提供关于训练过程中所发生事件的详细信息,包括数据增强、混合精度训练(AMP)和优化器配置等。
- 自动增强:自动应用的数据增强技术可以提高模型的泛化能力。
- AMP:自动混合精度训练可以提高训练速度并减少内存使用,同时保持模型性能。
- 优化器配置:监控优化器的行为可以帮助理解模型是否收敛以及是否需要调整学习率等超参数。
5.7 训练总结
还可以使用tensorboard实时监控日志,并观察微调的持续进行。
load_ext tensorboard
tensorboard --logdir yolov9e_1024_dataset/results/70_epochs-
让我们来看看保存在“yolov9e_1024_dataset/results/70_epochs-/results.png”的results.png。Ultralytics训练总结和results.png给出了模型微调的整体概念。
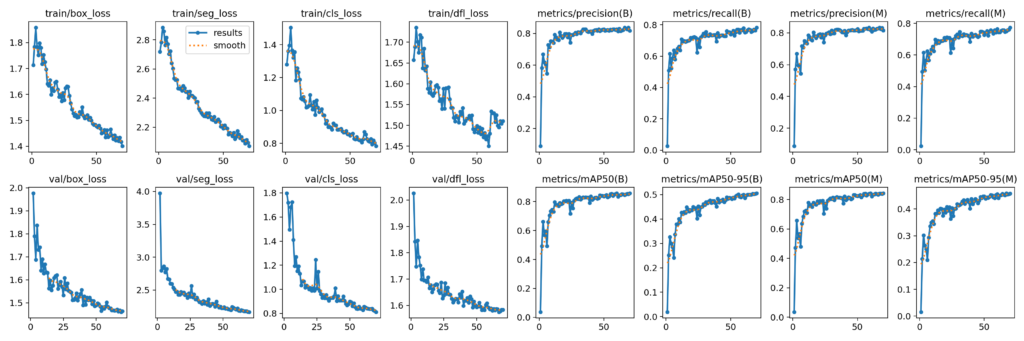 图4: YOLOv9e-seg模型的微调结果
图4: YOLOv9e-seg模型的微调结果
对于在**imgsz=1024下训练了70个周期的YOLOv9e-seg实例分割,我们实现了大约0.506的验证box mAP50-95和大约0.457的验证seg mAP50-95**。
6. YOLOv9实例分割推理
加载最佳模型权重,让我们对一些组织样本进行推理。
inference_model = YOLO('yolov9e_1024_dataset/results/70_epochs-/weights/best.pt')
%matplotlib inline
inference_img_path = "yolov9e_1024_dataset/val/images/human_spleen_13.png"
inference_result = inference_model.predict(inference_img_path, conf=0.7, save=True, imgsz=1024)
print(inference_result)
print("Boxes: \n", inference_result[0].boxes)
print("Masks: \n", inference_result[0].masks)
inference_result_array = inference_result[0].plot() # Ultralytics plot function.
plt.figure(figsize=(9, 9))
plt.imshow(inference_result_array)
plt.show()
 图5: YOLOv9e-seg 在人类肝脏组织上的推理
图5: YOLOv9e-seg 在人类肝脏组织上的推理
我们可以观察到,在上述结果中,我们的微调YOLOv9e-seg模型在置信度阈值为0.7时,几乎能够捕获所有实例,只剩下3到4个角落实例未被检测到。
所有的推理都在(512,512)图像尺寸和conf=0.7下完成,其中图像大小自动调整为模型的训练配置。在Ultralytics中,默认的imgsz是640x640。
因此,当我们使用imgsz=1024训练的YOLOv9e-seg模型进行推理时,我们的输入图像自动调整为1024。前向传递期间的输入尺寸看起来像(1,3,1024,1024),其中批量大小=1,通道尺寸=3。
inference_result是一个字典,其键和值如下:
-
boxes:一个dtype=float32的对象,表示检测到的边界框实例。这些框具有以下主要属性:cls:一个张量,显示所有检测到的对象的类别名称。conf:一个张量,显示模型检测到这些对象实例的置信度。边界框格式(xywh, xywhn, xyxy, xyxyn):一个张量,具有推理图像中实例的归一化坐标位置。
-
keypoints:无(对于实例分割任务)。 -
masks:一个表示检测到的掩码实例的对象。掩码具有以下主要属性:xy:一个dtype=float32的数组,具有每个掩码的多边形点位置。
-
names:模型训练的数据集上的类别映射。
6.1 YOLOv9实例分割自定义绘图函数
可以直接使用Utralytics的**plot()**函数以方便使用。然而,提取掩码、框和类名并执行自定义绘图在直观上更有益。因此,让我们通过使用inference_result字典来查看自定义绘图。
我们将通过置信度超过0.5的thresholded_indices过滤检测。从输出中,为所有预测的实例提取掩码和框属性。
def get_outputs(image, model, threshold=0.5):
# print("Image shape",image.shape)
outputs = model.predict(image, imgsz=1024, conf=threshold)
print("Outputs", outputs)
scores = outputs[0].boxes.conf.detach().cpu().numpy()
thresholded_indices = [idx for idx, score in enumerate(scores) if score > threshold]
print(f"Total detections: {len(scores)}, Passed threshold: {len(thresholded_indices)}")
if len(thresholded_indices) > 0:
masks = [outputs[0].masks.xy[idx] for idx in thresholded_indices]
boxes = outputs[0].boxes.xyxy.detach().cpu().numpy()[thresholded_indices]
boxes = [[(int(box[0]), int(box[1])), (int(box[2]), int(box[3]))] for box in boxes]
labels = [outputs[0].names[int(outputs[0].boxes.cls[idx])] for idx in thresholded_indices]
else:
masks, boxes, labels = [], [], []
return masks, boxes, labels
6.1.1 绘制分割图
draw_segmentation_map()函数使用cv2.fillPoly()和cv2.addWeighted()将提取的预测掩码和边界框叠加到输入图像上。
def draw_segmentation_map(image, masks, boxes, labels):
alpha = 1.0
beta = 0.5 # 分割图的透明度
gamma = 0 # 每次求和时添加的标量
image = np.array(image) # 将原始PIL图像转换为NumPy格式
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # 从RGB转换为OpenCV BGR格式
for mask, box, label in zip(masks, boxes, labels):
color = (0, 255, 0) # 可视化的绿色
segmentation_map = np.zeros_like(image)
if mask is not None and len(mask) > 0:
poly = np.array(mask, dtype=np.int32)
cv2.fillPoly(segmentation_map, [poly], color)
cv2.addWeighted(image, alpha, segmentation_map, beta, gamma, image)
cv2.rectangle(image, box[0], box[1], color=(255, 0, 0), thickness=2) # 边界框的红色
return image
使用cv2.imwrite()在指定目录中保存输出。
fig = plt.figure(figsize=(5, 5), layout="constrained")
image_path = "yolov9e_1024_dataset/val/images/human_placenta_24.png"
image = PIL.Image.open(image_path)
orig_image = image.copy() # 保留原始图像的副本以用于OpenCV函数和应用掩码
masks, boxes, labels = get_outputs(image, inference_model, threshold=0.5)
result = draw_segmentation_map(orig_image, masks, boxes, labels)
save_path = f"./inference/nuclei_instance_out{image_path.split(os.path.sep)[-1].split('.')[0]}.jpg"
cv2.imwrite(save_path, result)
plt.imshow(result)
plt.axis('off')
plt.show()
 图6: 自定义实例分割绘图
图6: 自定义实例分割绘图
6.2 YOLOv9实例分割训练总结
 表2:YOLOv9-seg和YOLOv8-seg在验证box和seg mAP50-95的比较
表2:YOLOv9-seg和YOLOv8-seg在验证box和seg mAP50-95的比较
从表2中,我们观察到YOLOv9 seg和YOLO V8 seg的验证box mAP和seg mAP几乎相同,小数精度有轻微差异。
6.2.比较1:YOLOv9e-seg v/s YOLOv8l-seg with imgsz=1024
让我们绘制两个模型的验证box和seg mAP (50-95)。
 图7: YOLOv9-seg v/s YOLOv8l-seg
图7: YOLOv9-seg v/s YOLOv8l-seg box and mask mAP with img_sz=1024的比较图表。
从上面的图表中,我们观察到对于**imgsz=1024**的训练配置,
- 与YOLOv9e-seg模型相比,YOLOv8l-seg模型的基线mAP相对更高,并且在较少的周期内实现了更高的
mAP。 - 此外,YOLOv8l-seg模型的box mAP和seg mAP略高于YOLOv9e-seg。
现在,让我们对置信度阈值为0.7进行深入比较。
关于真实情况,绿色框是YOLOv9e-seg模型未能检测到对象实例的实例。
同样,黄色框是YOLOv8l-seg模型未检测到的对象实例。
注意:_这里的比较下面的绿色和黄色框不是预测片段的边界框;它们只是装饰。_这些是手动绘制的参考,以便我们理解模型未能捕获与真实情况相关的_差异**。

图8: 人类肾脏 — 真实情况

图9: 未捕获实例w.r.t真实情况
在这张imgsz=1024和conf=0.7的特定图像中,我们可以观察到YOLOv9e-seg错过了24个实例,而YOLOv8l-seg错过了18个实例。
即YOLOv8l-seg在这里表现更好。
6.3 关于真实情况的定量分析
现在,让我们分解两个模型在特定区域(蓝框)的检测差异。
注意:_在下面的比较中,蓝色框不是预测实例的边界框;它们只是装饰。_这些是手动绘制的,以显示与真实情况的差异。

图10: YOLOv9e-seg v/s YOLOv8l-seg的定量检测差异
我们再次观察到YOLOv8l-seg检测到的实例比YOLOv9e-seg多得多。当图像尺寸增加到1024时,YOLOv9e-seg的表现相对较差,但相反,增加图像尺寸使YOLOv8l-seg的表现更好。
比较2:YOLOv9e-seg v/s YOLOv8l-seg with imgsz=640
让我们绘制两个模型的验证box和seg mAP(50-95)。
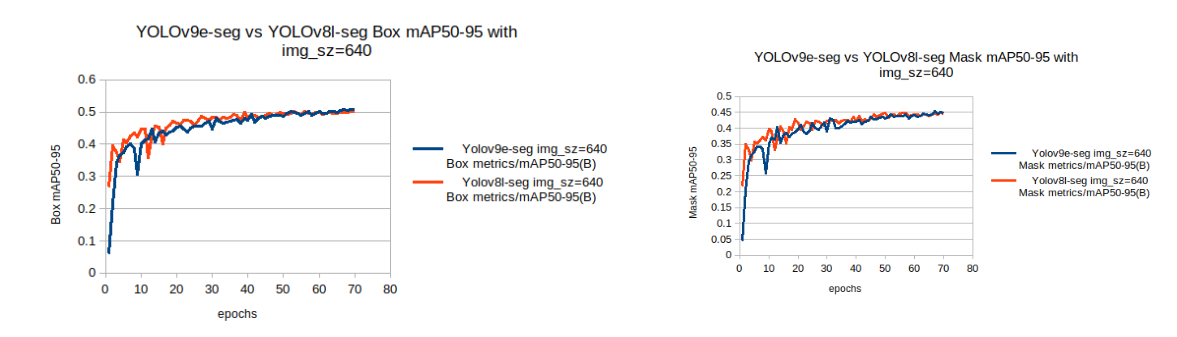
图11:YOLOv9-seg v/s YOLOv8l-seg box and mask mAP with imgsz=640的比较图表。
从上面的图表中,我们观察到对于imgsz=640的训练配置,
-
与YOLOv9e-seg模型相比,YOLOv8l-seg模型的基线mAP相对更高,并且在较少的周期内实现了更高的mAP。
-
这里,在训练结束时,两个模型的验证box mAP和seg mAP几乎相同。
-

图12: 未捕获实例w.r.t真实情况 -
我们可以观察到在这个特定图像中,YOLOv9e-seg (绿色)错过了20个实例,而YOLOv8l-seg (黄色)错过了18个实例,置信度为**
conf=0.7**。 -
即YOLOv8l-seg在这里表现更好,并且有更少的假阴性。
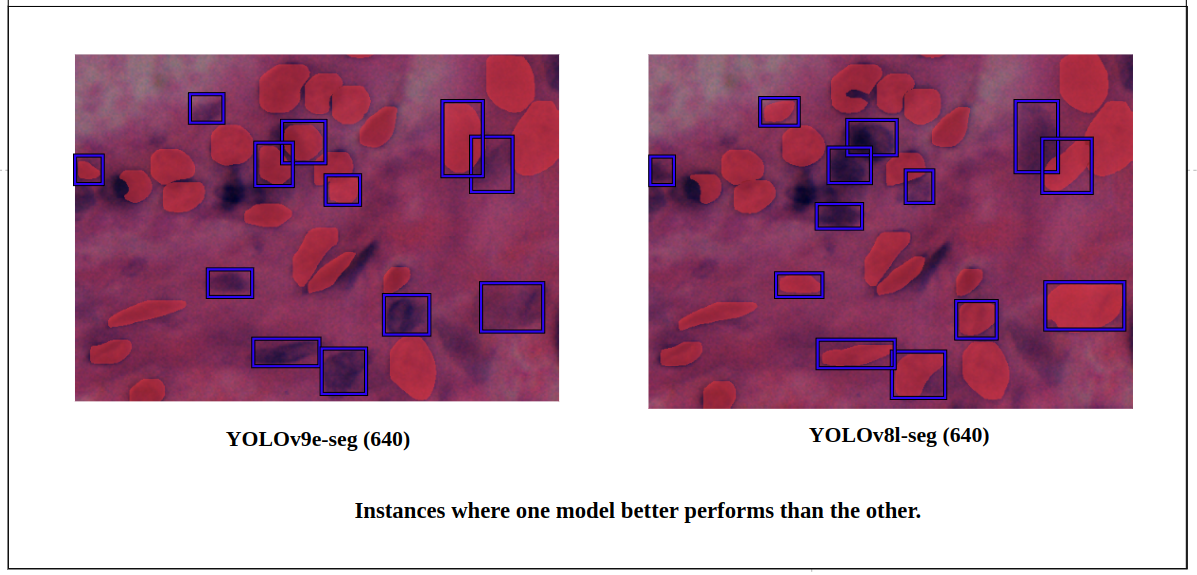
图13: YOLOv9e-seg v/s YOLOv8l-seg的定量检测差异。
让我们关注组织图像的特定区域。两者表现几乎相同,但YOLOv8l-seg略好,有更多的真阳性。
6.4 比较3:YOLOv9c-seg v/s YOLOv8m-seg with imgsz=640
让我们绘制两个模型的验证box和seg mAP(50-95)。
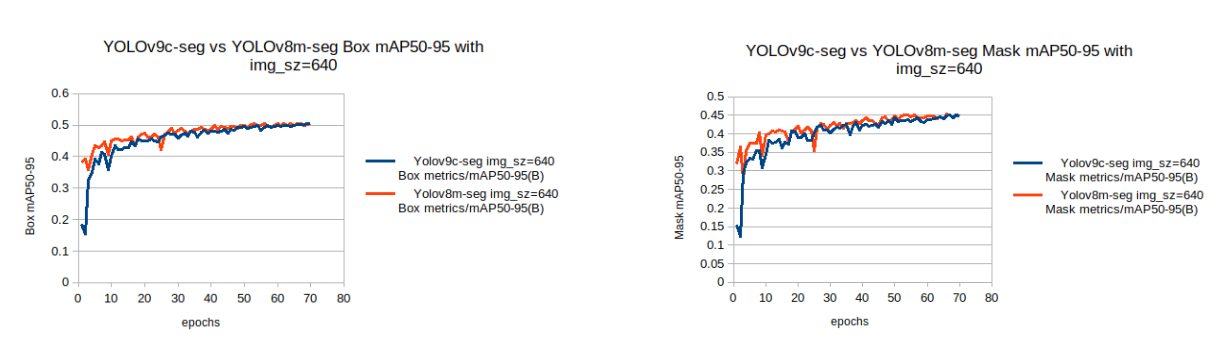
图14: YOLOv9c-seg v/s YOLOv8m-seg val box and mask mAP with imgsz=640的比较图表。
从图表中,我们观察到对于**imgsz=640**的训练配置,
- 与YOLOv9c-seg模型相比,YOLOv8m-seg模型的基线mAP相对更高,并且在较少的周期内实现了更高的mAP。
- 在训练结束时,两个模型的验证mAP几乎相同。
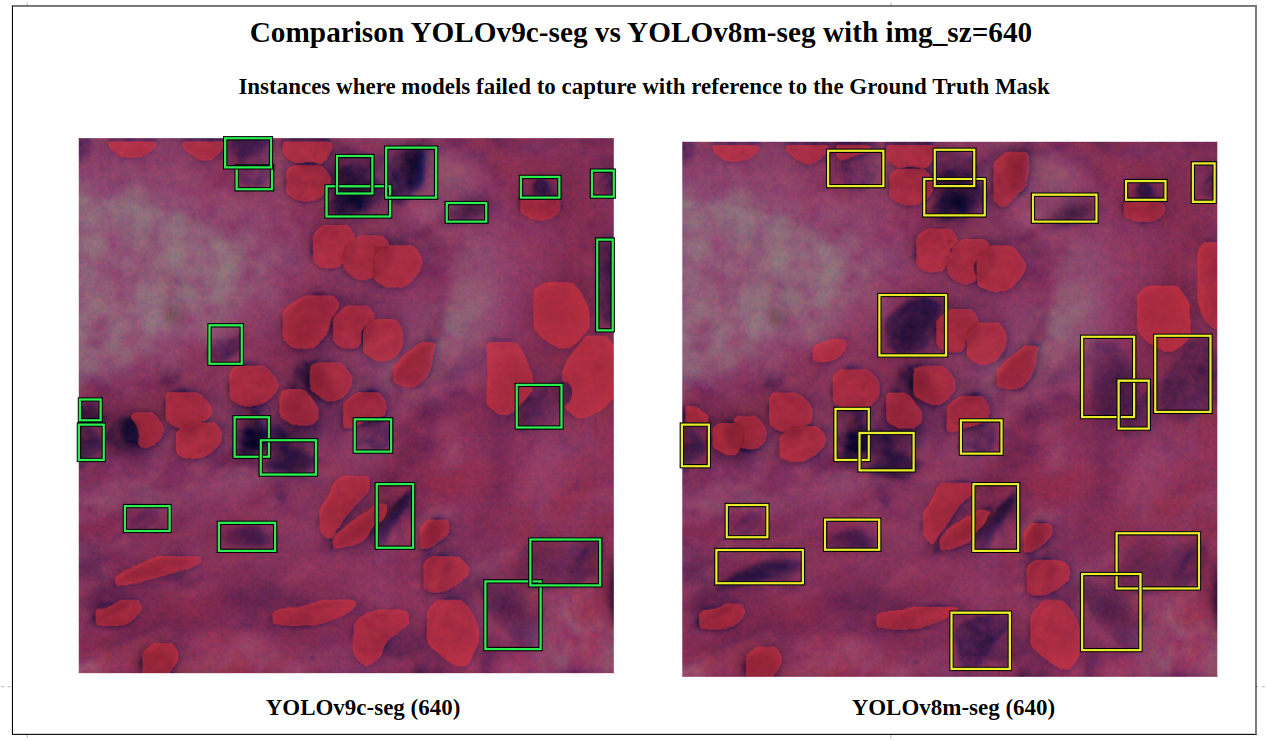
图15: 未捕获实例w.r.t真实情况
我们可以观察到在这个特定图像中,YOLOv9c-seg (绿色)错过了21个实例,而YOLOv8m-seg (黄色)错过了21个实例,置信度为conf=0.7。
现在,让我们分解两个模型在特定区域的现有检测差异。

图16: YOLOv9c-seg v/s YOLOv8m-seg的定量检测差异
在这里,对于这个特定区域,我们观察到YOLOv9c-seg检测到的真阳性实例比YOLOv8m-seg多得多。
6.5 YOLOv9实例分割对多张图像的预测
为了更好地了解所有模型分割掩码的精度,让我们从验证集中推断出大量人类组织图像的预测。在推理期间,要查看没有边界框的预测,传递**boxes=False**参数。我们将可视化我们已经并排实验的两个YOLOv9和YOLOv8模型的所有预测,这些模型具有不同的图像尺寸和置信度阈值设置为0.7,并比较预测的分割掩码。

图17: 人类肾脏组织 — YOLOv9-seg v/s YOLOv8-seg 实例分割
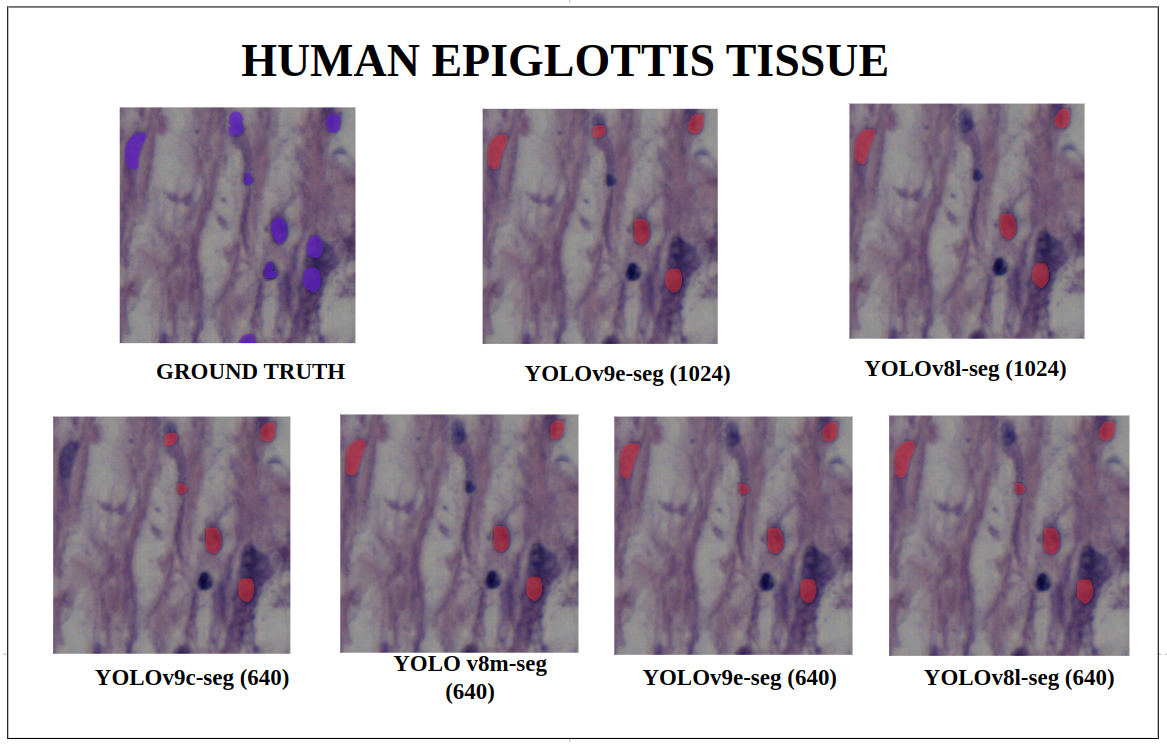
图18: 人类会厌组织 — YOLOv9-seg v/s YOLOv8-seg 实例分割
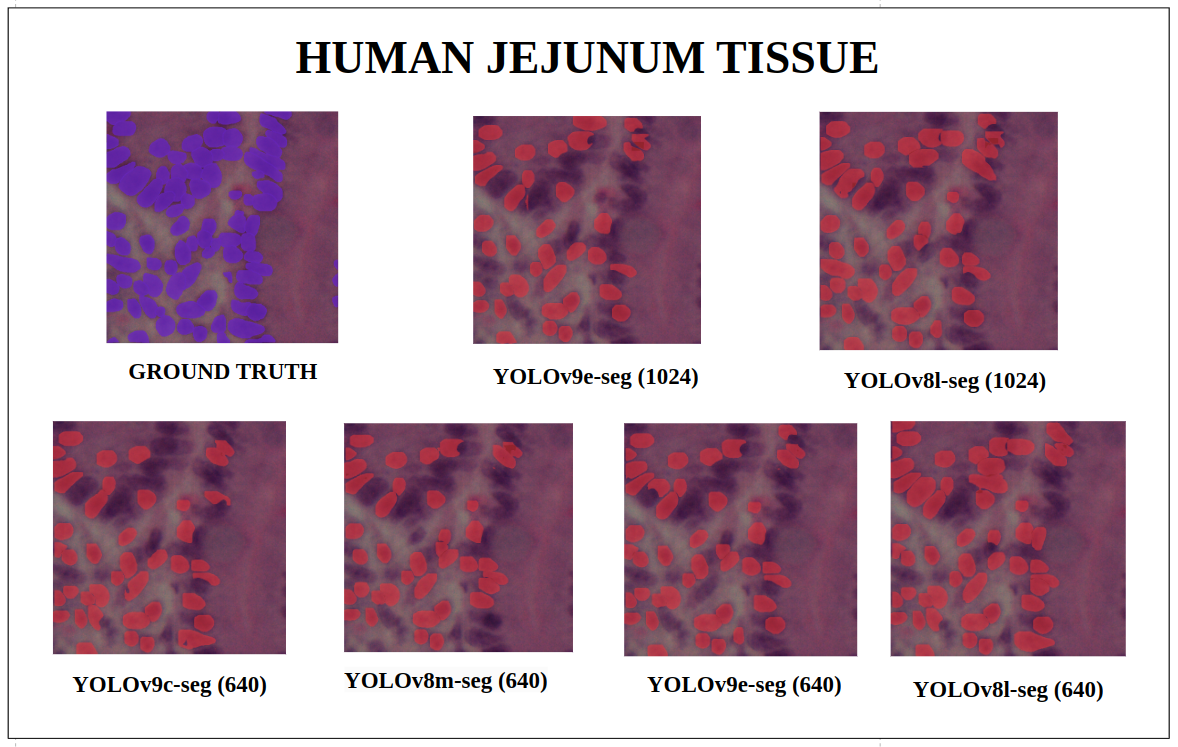
图19: 人类空肠组织 — YOLOv9-seg v/s YOLOv8-seg 实例分割
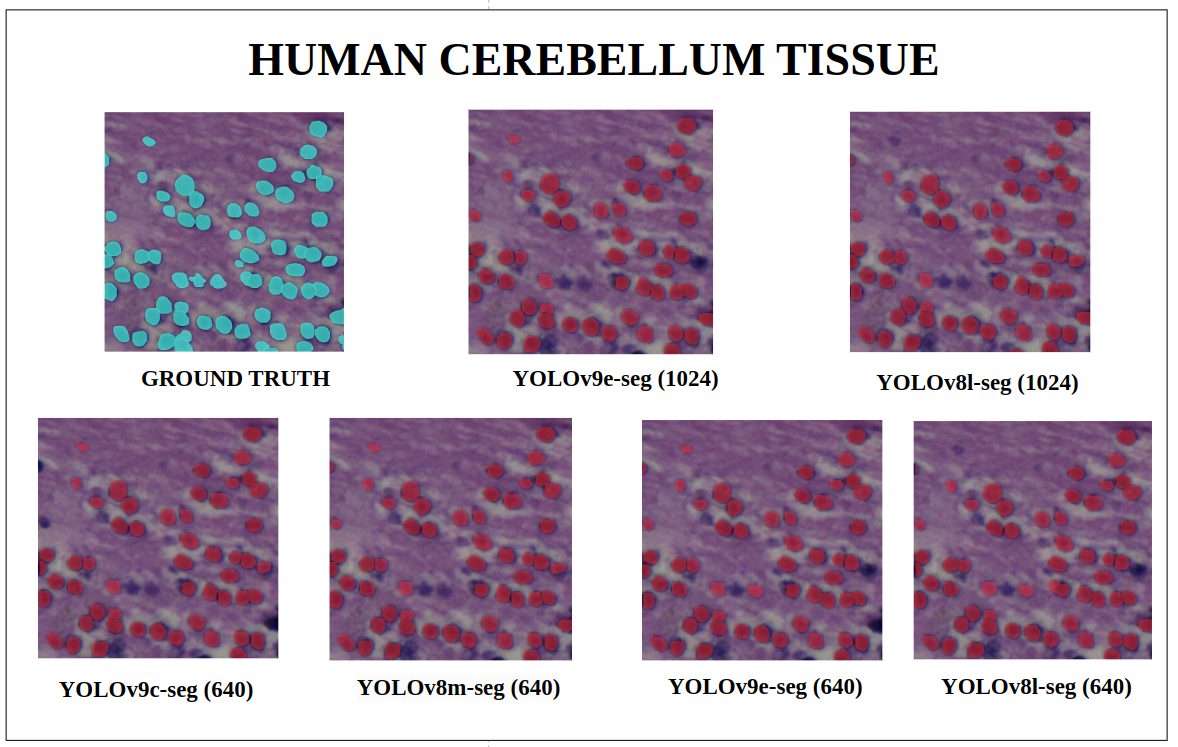
图20: 人类小脑组织 — YOLOv9-seg v/s YOLOv8-seg 实例分割
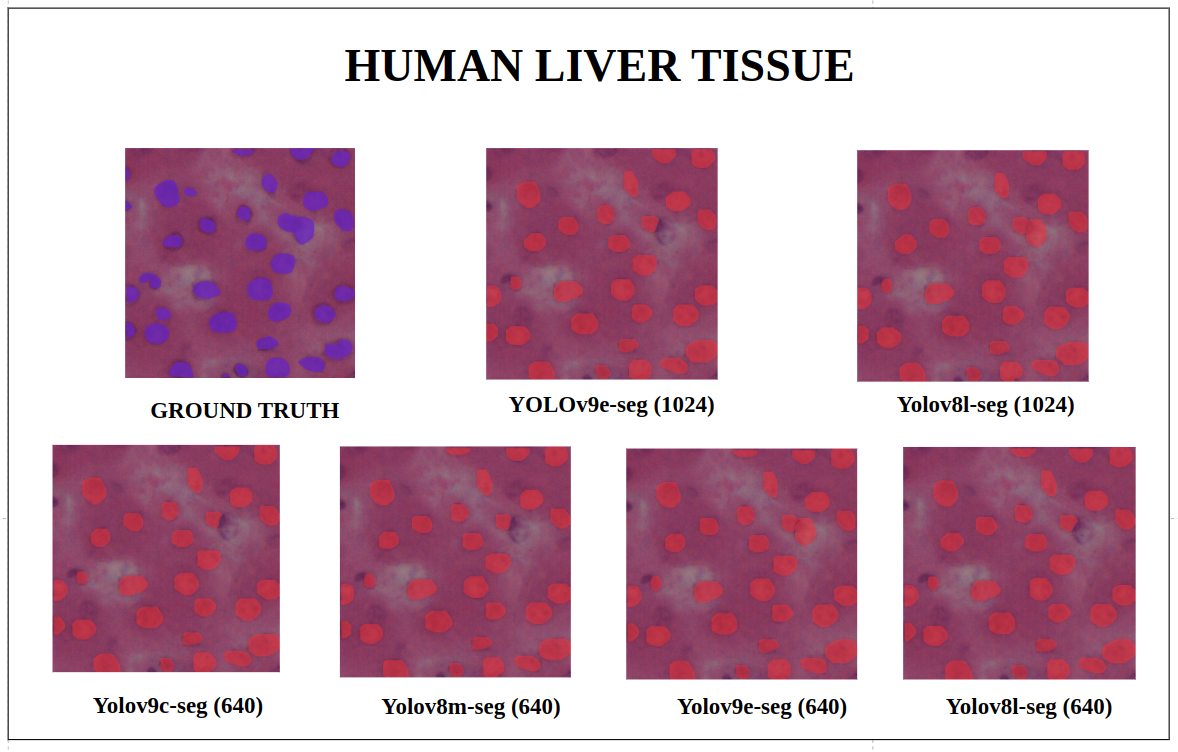
图21: 人类肝脏组织 — YOLOv9-seg v/s YOLOv8-seg 实例分割
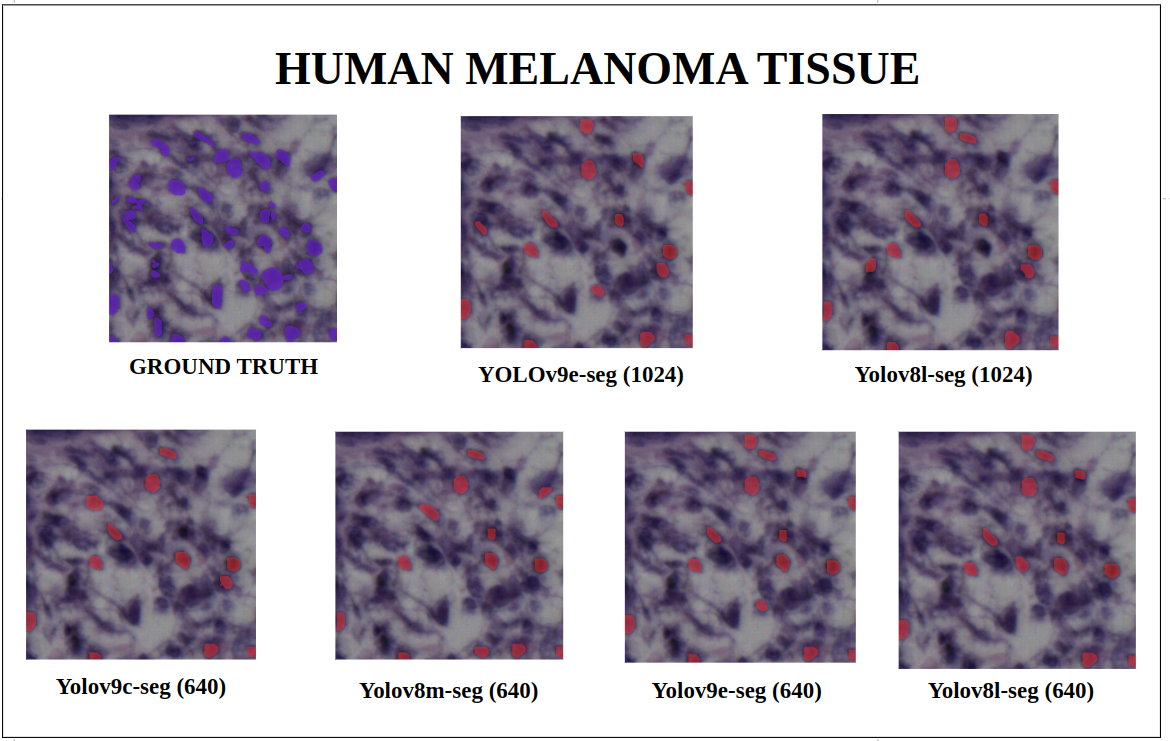
图23: 人类黑色素瘤组织 — YOLOv9-seg v/s YOLOv8-seg 实例分割
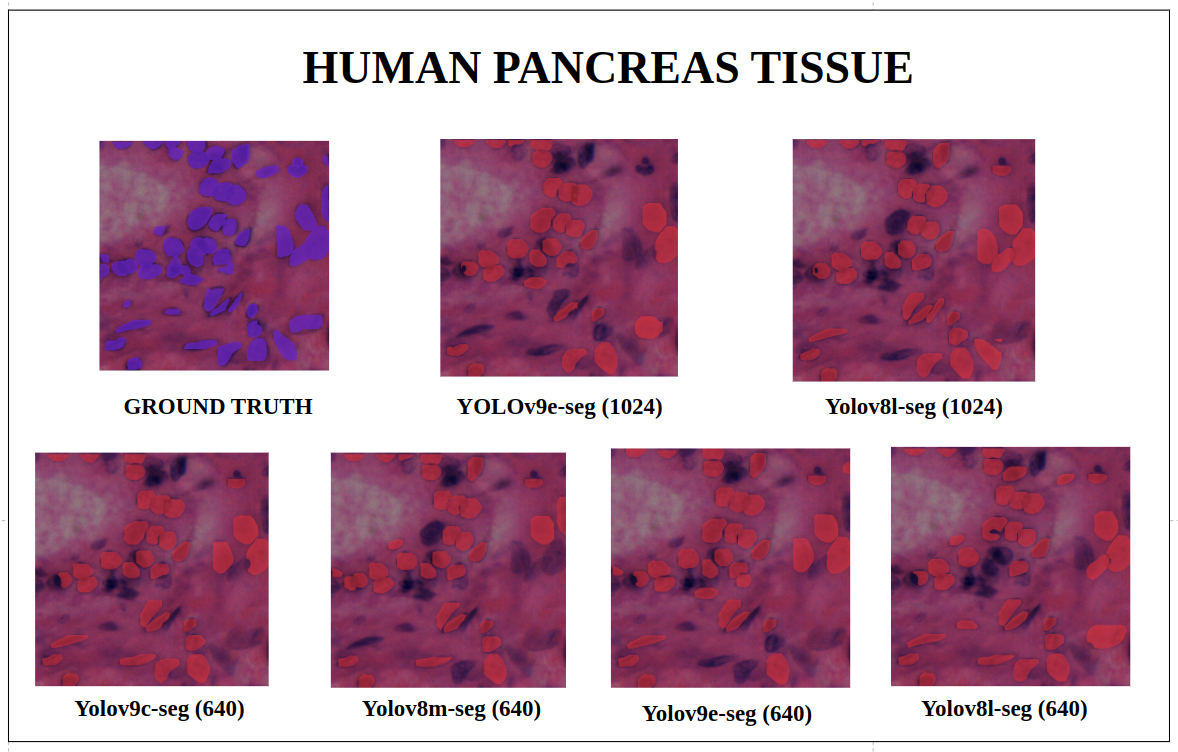
图24: 人类胰腺组织 — YOLOv9-seg v/s YOLOv8-seg 实例分割

图25: 人类膀胱组织 YOLOv9-seg v/s YOLOv8-seg 实例分割
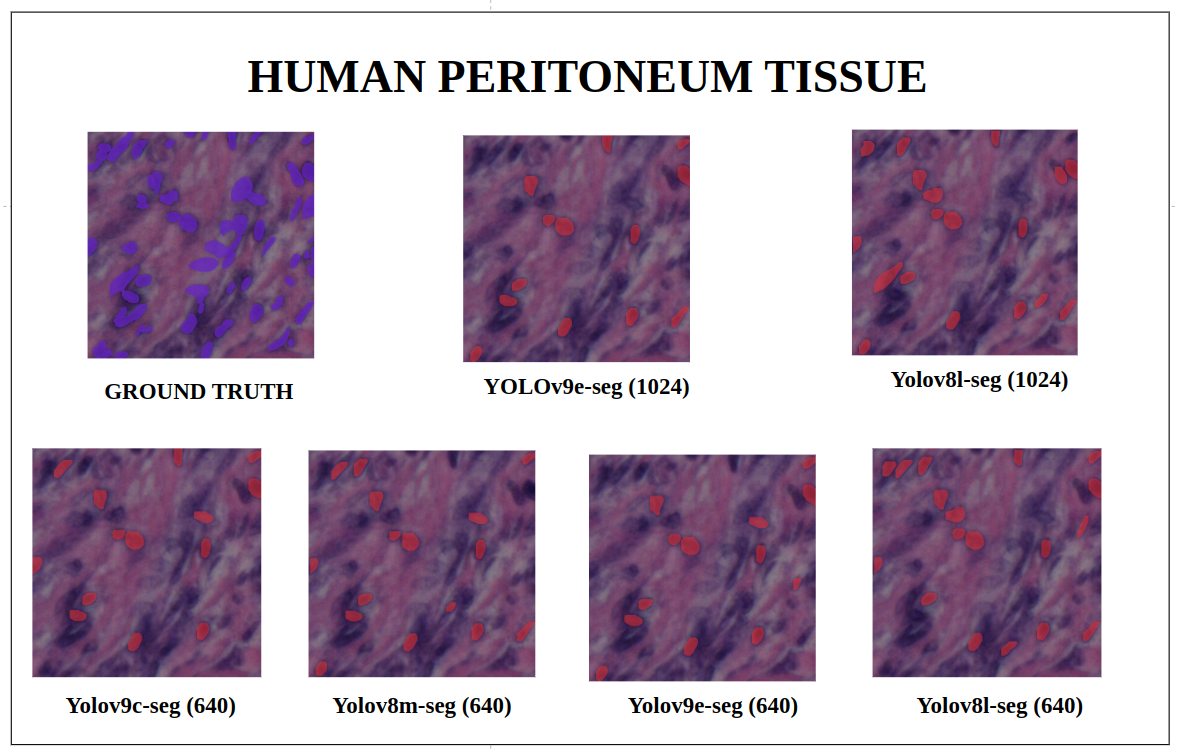
图26:人类腹膜组织 YOLOv9-seg v/s YOLOv8-seg 实例分割
在imgsz=1024和推理conf=0.7的训练配置下,尽管YOLOv8l-seg(46M)的参数比YOLOv9e-seg(60.5 M)少得多,但在许多情况下YOLOv8l-seg表现更好。
另一方面,比较YOLOv9c-seg(27.9M)v/s YOLOv8m-seg(27.3M),在imgsz=1024下,总体而言,两者表现几乎相同。
7. 总结
实例分割任务中对 YOLOv9-seg 和 YOLOv8-seg 模型的微调实验的结果,以及它们在特定数据集上的性能表现:
7.1 实验结果概述
- YOLOv9-seg 和 YOLOv8-seg 的性能:两个模型在实例分割任务上都展现出了良好的定量性能。
- YOLOv8-seg 的优势:尽管参数数量较少,但在某些情况下,YOLOv8-seg 在核细胞实例数据集上的性能略优于 YOLOv9-seg。
- 图像尺寸对性能的影响:当图像尺寸增加到 1024 像素时,YOLOv9e-seg 模型的性能不如参数数量较少的模型,如 YOLOv8l-seg、YOLOv8m-seg 和 YOLOv9c-seg。
7.2 可能的见解和解释
- 模型复杂度与性能:实验结果表明,并非总是模型越大或参数越多,性能就越好。模型的架构和训练过程的优化对于特定任务的性能至关重要。
- 数据集特性:YOLOv8-seg 在核细胞实例数据集上的优势可能归因于该模型对数据集特性的适应性更好,例如,可能与数据集的大小、类别的多样性或分割任务的复杂性有关。
- 图像分辨率:图像尺寸的增加对模型性能有显著影响。较大的图像尺寸可能会增加计算负担,导致需要更多的计算资源和内存。此外,对于某些模型,图像尺寸的增加可能会导致过拟合,因为模型可能开始学习到过多与任务无关的细节。
- 模型选择:在选择模型时,应考虑特定任务的需求和数据集的特性。在某些情况下,较小的模型可能更适合,尤其是在资源有限或需要快速推理的场景中。
7.3 对医学成像的潜在效用
- 精确的对象级洞察力:实例分割提供了精确的、对象级别的洞察力,这对于医学成像中的许多应用至关重要。
- 癌症研究:在癌症研究中,精确的分割可以帮助识别和量化肿瘤的大小和形状,从而有助于疾病的分级和治疗计划的制定。
- 神经生物学和发育生物学:在神经生物学和发育生物学中,实例分割可以帮助研究者追踪和分析细胞或组织的发育过程。



















 944
944




 到【灌水乐园】发言
到【灌水乐园】发言









