




 本文深入探讨了数据库索引的概念,强调其在减少磁盘I/O和提升查询速度方面的作用。详细介绍了InnoDB存储引擎中的B+树索引结构,包括聚簇索引和二级索引的区别,以及如何通过创建和设计索引来优化查询性能。此外,还讨论了单列索引、多列索引和全文索引的创建方法,以及在实际操作中的增删改查操作对索引的影响。
本文深入探讨了数据库索引的概念,强调其在减少磁盘I/O和提升查询速度方面的作用。详细介绍了InnoDB存储引擎中的B+树索引结构,包括聚簇索引和二级索引的区别,以及如何通过创建和设计索引来优化查询性能。此外,还讨论了单列索引、多列索引和全文索引的创建方法,以及在实际操作中的增删改查操作对索引的影响。
什么是索引? 后端程序员面试必问的问题,下面我们来深度剖析索引!!
定义
创建索引的目的:减少磁盘的I/O
官方定义: 索引是帮助Mysql高效获取数据的数据结构
索引的本质
索引的优缺点:
● 查询速度快,插入更新会变慢
● 减少分组排序数据的查询
● 会出现内存占用
(不同 的存储引擎其 存储的索引大小和数量也不同 )

InnoDB中索引方案
1. 一个简单的索引方案
创建表中的数据是通过行格式进行创建的
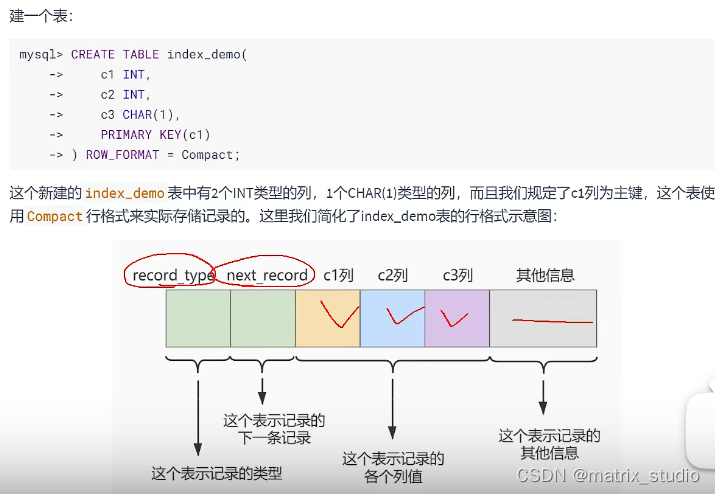
将这些记录放置页中,并从小到大,从左往右存储
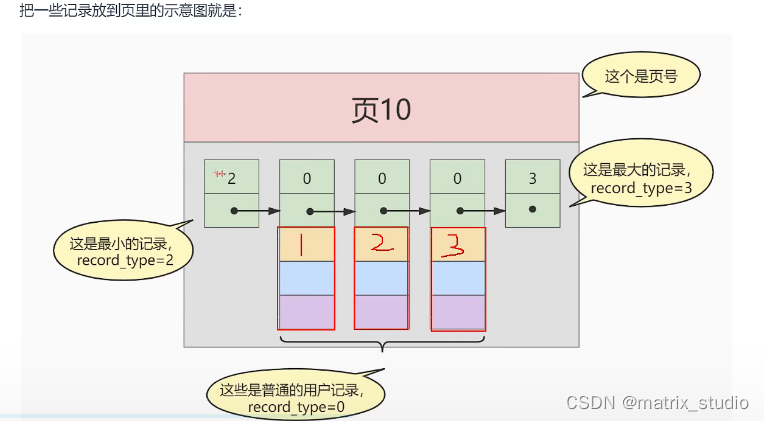
(将所有的数据依据页来分页,再给每个页添加一个目录项,目录项存储的是页中的最小值,通过二分查找的方式,找到对应的目录项,进而在目录项中的页中查找数据)
递归目录页的设计思想
记录目录项的目录页:(只存储主键值和对应的页号)
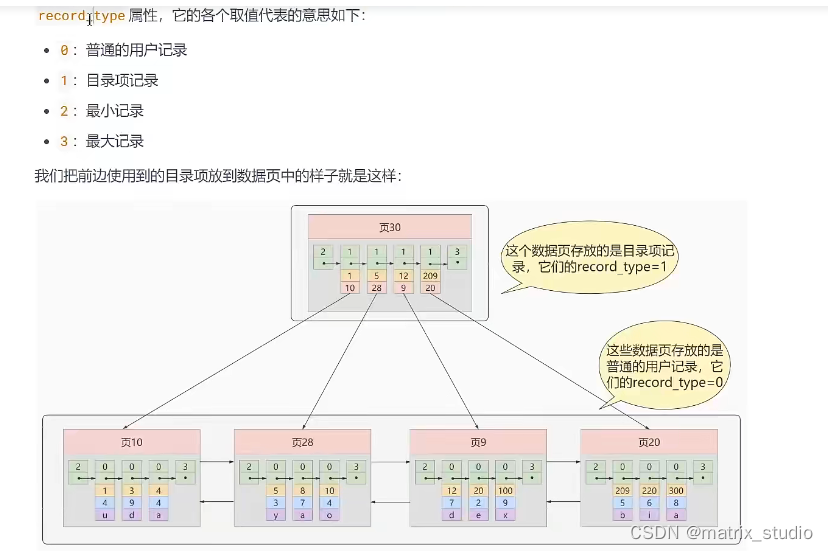
(只需要两次IO就能够定位到数据的位置)
- 只要是当前目录项的记录是有限的,我们就只需要重新分配一个新的存储目录,即新的存储页记录的目录项,同时,随着新生成的页目录项越来越多,且页目录对应的页号是随机的,我们就有可以套一层娃,即生成一个更高级的目录项,之前的目录项随之变成子目录
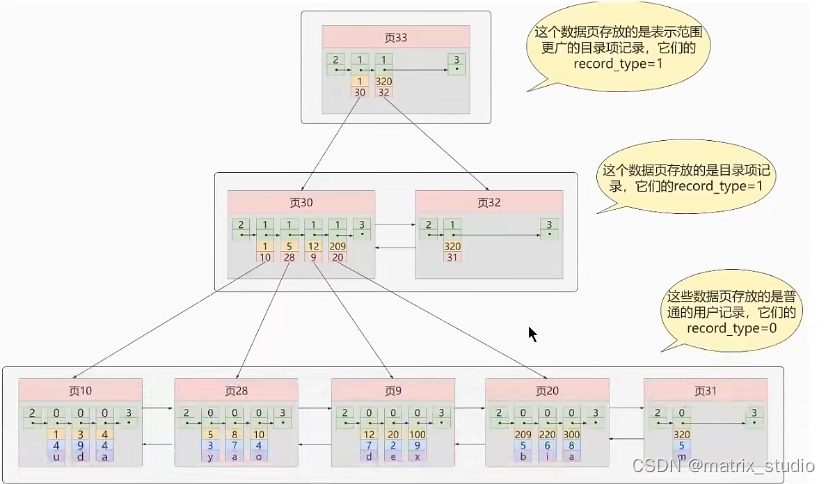
随着数据量的增加,目录层级会继续增加,简化一下我们就可以,大致推出B+树的数据结构
(树的层次越低,IO的次数就更少)
● 默认的数据页大小是16kb
索引的创建和设计原则
MySQL的索引包括
● 普通索引、唯一性索引、全文索引、单列索引、多列索引和空间索引等。
● 从 功能逻辑 上说,索引主要有 4 种,分别是普通索引、唯一索引、主键索引、全文索引。
● 按照 物理实现方式 ,索引可以分为 2 种:聚簇索引和非聚簇索引。 按照 作用字段个数 进行划分,分成单列索引和联合索引。

聚簇索引
(一级索引 ): B+树
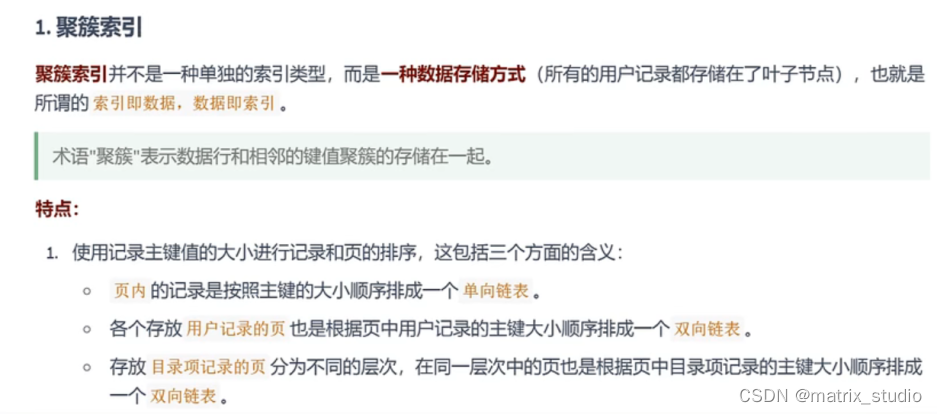
底层的存储方式:根据主键进行页内的记录和排序(数据都在叶子结点上)
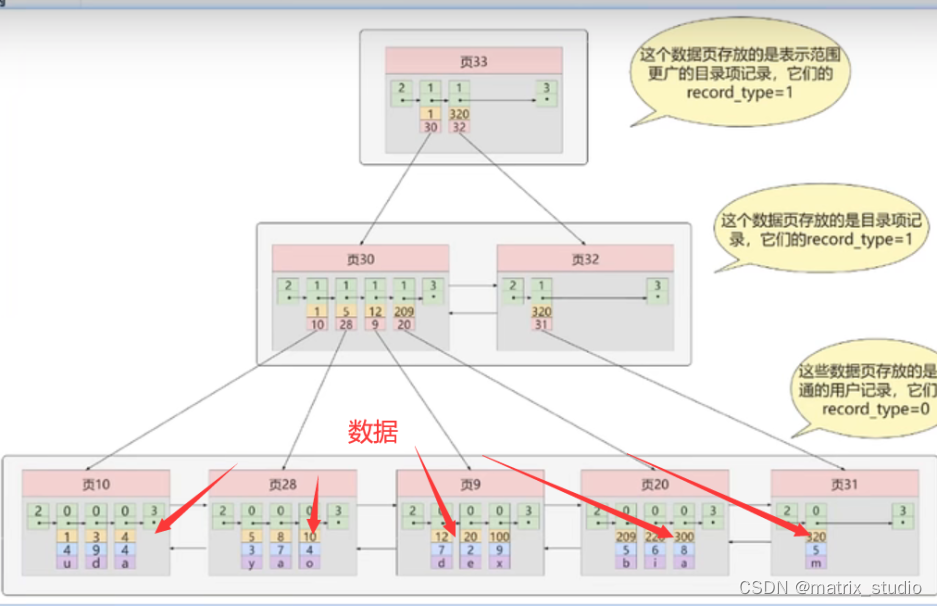
聚簇的含义:索引和数据聚合在一起
(定义主键自增的原因: 插入更高效,否则会出现页分裂的现象,严重影响性能)

(尽量不要出现页分裂的情况)
(只能支持一个排序标准,所以只能有一个主键)
二级索引(辅助索引,非聚簇索引)
(聚簇索引只能在搜索条件是主键时才生效,应为B+树中的数据是按照主键进行排列的,若以别的条件进行搜索,我们可以引入二级索引,即多建一个新的b+树,这个b+树是按照查询条件对应列来查找的,)
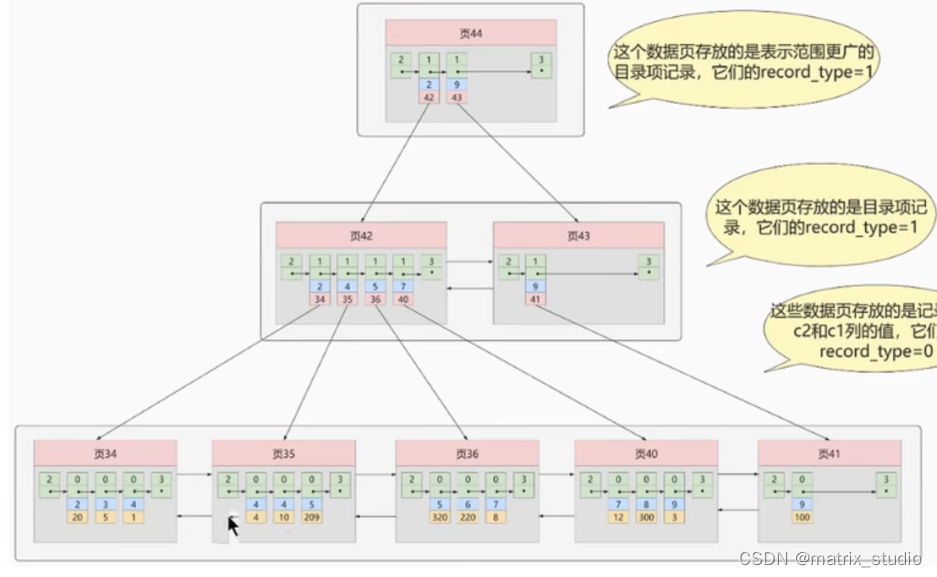
(相当于新的查询条件作为b+树的排序和页的分类标准)
(例如 : select * from user where c2= 4)
(最后将找到的结果,即为主键,去聚簇索引中查找到对应的所有数据 ,称为回表操作)
二者区别

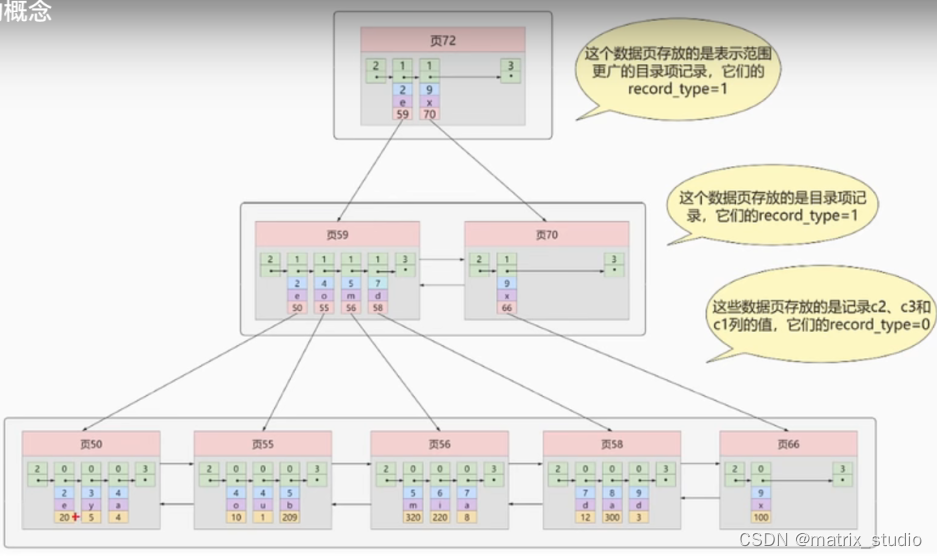
联合索引(非聚簇索引)
即为: 定义多个列为排序规则,为多个列建立索引
创建索引的三种方式
创建的前后表都能创建
(隐式创建)
- 声明有主键约束,唯一性约束,外键约束的字段时,会自动创建相应的索引
(显式创建)

# 单列索引
CREATE TABLE book(
book_id INT,
book_name VARCHAR(100),
# 声明索引
INDEX idx_name(book_name)
);
SHOW INDEX FROM book
# 性能分析
EXPLAIN SELECT * FROM book WHERE book_name-'111'
# 创建组合索引
CREATE TABLE test3(
id INT(11) NOT NULL,
name CHAR(30) NOT NULL,
age INT(11) NOT NULL,
info VARCHAR(255),
INDEX multi_idx(id,name,age)
);
# 创建全文索引
CREATE TABLE test4(
id INT NOT NULL,
name CHAR(30) NOT NULL,
age INT NOT NULL,
info VARCHAR(255),
FULLTEXT INDEX futxt_idx_info(info)
) ENGINE=MyISAM;
(Mysql 8 默认支持InnoDB存储引擎)
在已有表基础上添加索引
(Mysql 8 默认支持InnoDB存储引擎)
删除索引
(大量的增删改时索引会带来耗时,增删改前一般先删除索引)
SHOW INDEX FROM book
EXPLAIN SELECT * FROM book WHERE book_name-'111'
增加索引
ALTER TABLE book ADD UNIQUE b_name(book_name);
ALTER TABLE book DROP INDEX b_name



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









