




 在部署Druid集群并进行灌库时,遇到了一系列问题,包括灌库脚本错误、连接S3问题、索引创建失败等。通过排查,发现错误源于灌库数据中的时间戳与JSON intervals不一致。解决方法是调整intervals以匹配数据中的时间戳。此外,还涉及到使用阿里云服务时的Hadoop MR作业、S3访问权限以及Yarn控制台的监控。
在部署Druid集群并进行灌库时,遇到了一系列问题,包括灌库脚本错误、连接S3问题、索引创建失败等。通过排查,发现错误源于灌库数据中的时间戳与JSON intervals不一致。解决方法是调整intervals以匹配数据中的时间戳。此外,还涉及到使用阿里云服务时的Hadoop MR作业、S3访问权限以及Yarn控制台的监控。
部门要搭建一套druid环境,买的是阿里云的服务
overload使用一台机器,middleManager使用两台机器
其他的查询组件也都部署在这三台机器上
因为这几个节点设计indexService,也就是灌库任务,我们主要关心灌库
下面是灌库过程中遇到的一堆坑
druid灌库会启动hadoop的mr任务,会读s3上数据,会将生成的segment写到deep storage上。
涉及最本质的三个问题:
1.数据从哪来
2.数据在哪计算
3.数据写哪去
阿里提供的druid集群,本身有一套自带的hadoop做mr计算,有自带的hdfs做deep storage
我们这次druid灌库一直都使用这个自带的hadoop和hdfs
1.准备好了灌库脚本和灌库数据,启动灌库命令后立刻报错
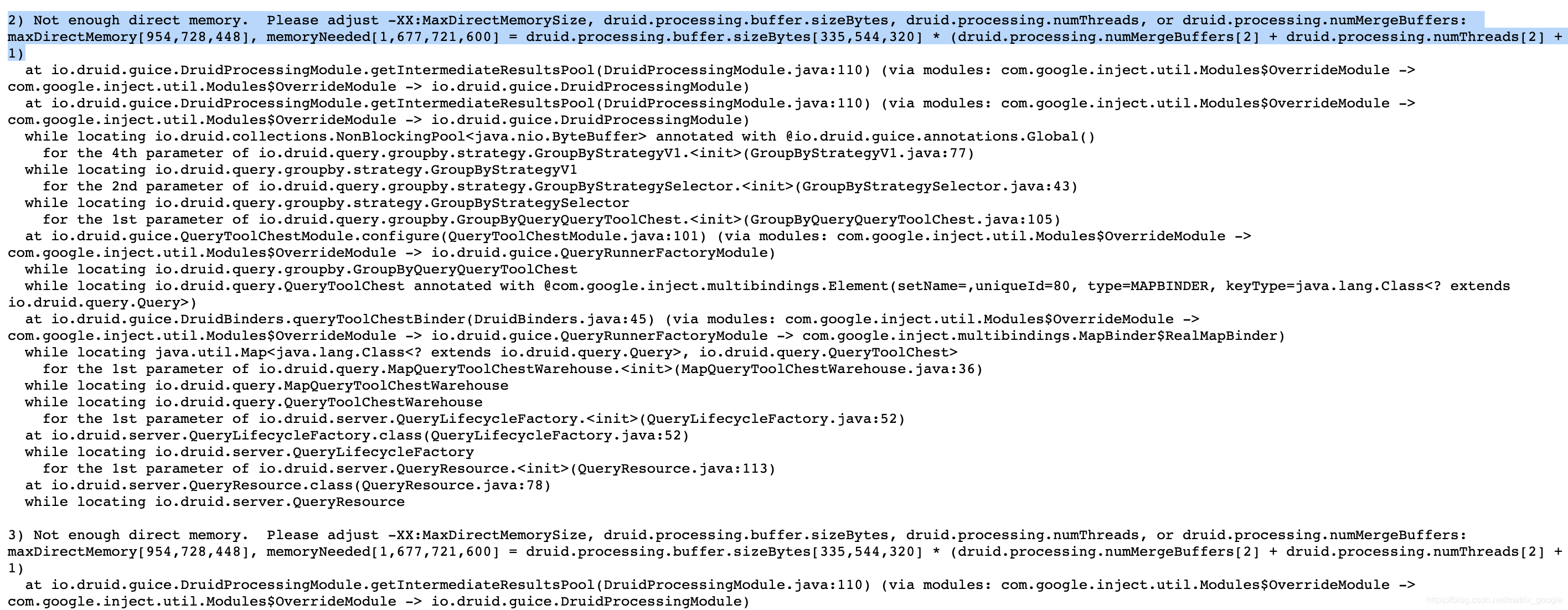
这个问题在另一篇文章中详细讨论
2.灌库任务无法连接s3
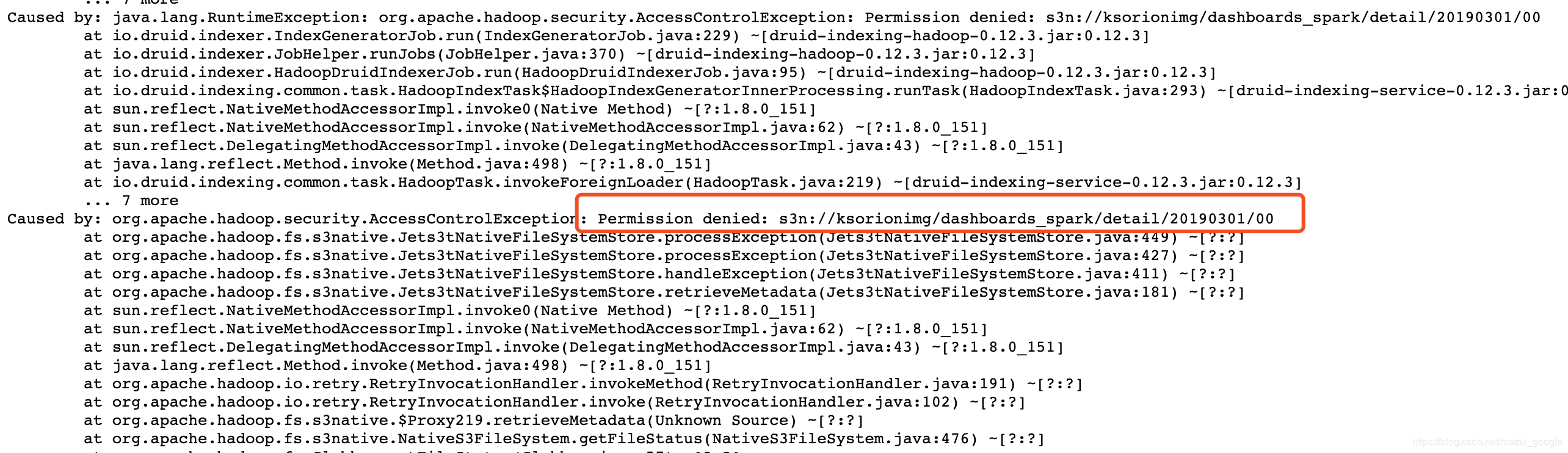
虽然在家目录的.aws配置了访问s3桶的秘钥,但是druid灌库json中也有这个秘钥配置,改成新的秘钥之后,问题解决
3.索引创建任务失败
权限问题解决后,继续提交灌库任务,报错如下:索引创建任务失败
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









