




 文章介绍了使用Q-学习算法进行智能体路径规划的方法,适用于无人机在多障碍环境下的导航。通过MATLAB仿真,验证了算法在栅格环境中的有效性,能够使智能体避免碰撞并找到最优路径。
文章介绍了使用Q-学习算法进行智能体路径规划的方法,适用于无人机在多障碍环境下的导航。通过MATLAB仿真,验证了算法在栅格环境中的有效性,能够使智能体避免碰撞并找到最优路径。
✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab仿真内容点击👇
⛄ 内容介绍
科学技术日新月异,人类在航空航天领域和无人驾驶方面探索的步伐从未停止。无人机和无人车等智能体的应用范围逐渐扩大,这无形中对其智能化算法提出了更高的要求。智能体在动态障碍物的环境中完成路径规划任务,会存在一定的规划困难,需要对传统的算法进行更深层次的改进。另外,未来的智能体不能仅依赖于手动的编程,按部就班的完成任务,应该通过与环境交互自主完成障碍物的躲避、路径规划与导航等常规任务和使命。而强化学习算法为实现智能体自主化完成任务开辟了一条可行的技术道路。本文采用一种基于Q‑学习算法的路径规划方法,其方法为:第一步:获得基本信息;第二步:确定图中的障碍物坐标;第三步:对图形进行分割处理;第四步:利用Q‑学习算法规划路径;第五步:得出最优路径,根据学习结果用MATLAB绘制出最优的路径。有益效果:在栅格环境下进行仿真实验,并成功地应用在多障碍物环境下移动机器人路径规划,结果证明了算法的可行性。
⛄ 部分代码
function [state,reward]=MovRobot(state,action,actoffsets,WS) %更新机器人位置%更新机器人位置并保存Prestate=state;MaxX=30;MaxY=30;state=state+actoffsets(action,:);if(state(1)<1) state(1)=1; endif(state(2)<1) state(2)=1; endif(state(1)>MaxX) state(1)=MaxX; endif(state(2)>MaxY) state(2)=MaxY; endif(WS(state(1),state(2))==1) %发生碰撞reward=-.2; state=Prestate;elseif(WS(state(1),state(2))==0)reward=-.1; %正常移动elsereward=1; %到达目标endHRobot=plot(state(1),state(2)','marker','o','color',[0 0 0],'linewidth',0.5); %画机器人圆圈%pause(0.001);%设置机器人运行速度set(HRobot,'visible','off') %将前一步画的机器人取消显示
⛄ 运行结果
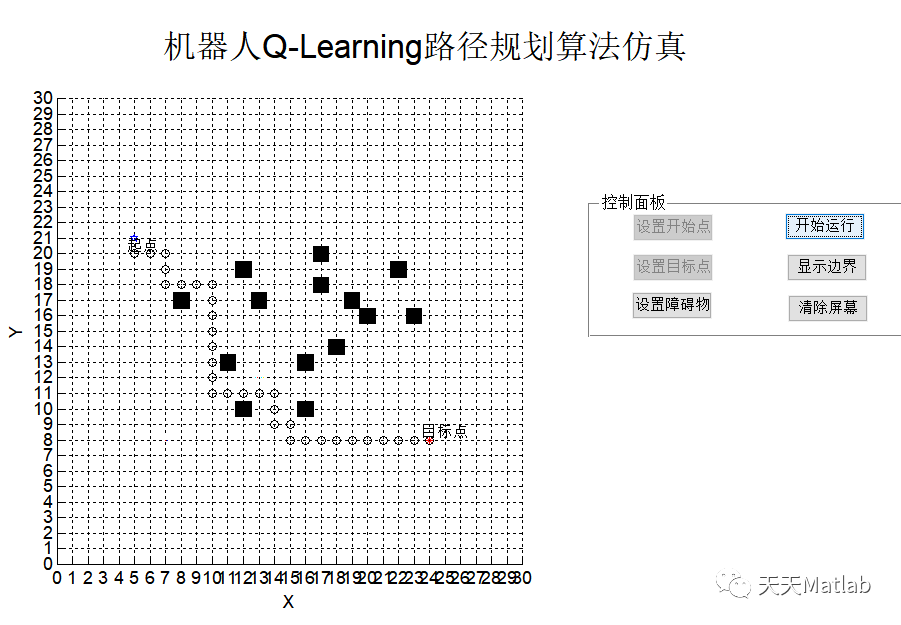
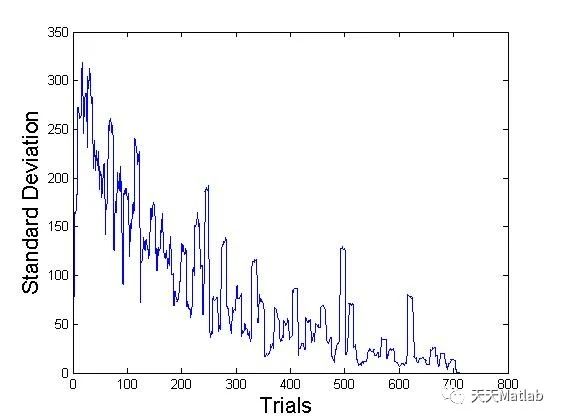
⛄ 参考文献
[1] 陈晓娥苏理. 一种基于环境栅格地图的多机器人路径规划方法[J]. 机械科学与技术, 2009, 028(010):1335-1339.
[2] 王启宇, 李刚俊. 基于典型栅格地图的轮式移动机器人路径规划与跟踪[J]. 西南科技大学学报, 2017, 32(4):4.
[3] 周东健, 张兴国, 马海波,等. 基于栅格地图-蚁群算法的机器人最优路径规划[J]. 南通大学学报:自然科学版, 2013, 12(4):4.
[4] 郭新兴. 基于强化学习的路径规划研究[D]. 西安电子科技大学, 2020.
[5] 千承辉, 马天录, 刘凯,等. 基于Q-学习算法的路径规划方法:, CN108594803A[P].
⛳️ 代码获取关注我
❤️部分理论引用网络文献,若有侵权联系博主删除
❤️ 关注我领取海量matlab电子书和数学建模资料



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











