




 本文介绍了几种常用的机器学习模型性能评估指标,包括准确度、精确度、召回率、F1分数、平均精度(AP)、平均平均精度(mAP)及接收者操作特性曲线(ROC)。并详细解释了这些指标的意义、计算公式及其应用场景。
本文介绍了几种常用的机器学习模型性能评估指标,包括准确度、精确度、召回率、F1分数、平均精度(AP)、平均平均精度(mAP)及接收者操作特性曲线(ROC)。并详细解释了这些指标的意义、计算公式及其应用场景。
1. 基础概念
混淆矩阵:
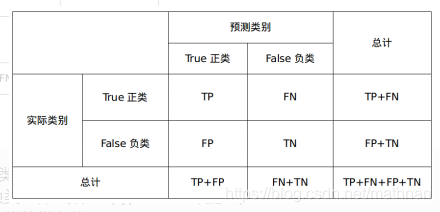
通过研究该混淆矩阵,可以构造如下几个指标:
(1) Accuracy(准确度):
- 意义:用于同时衡量分类器对于正负样本的分类正确性。
- 不足:当测试样本不平衡时,该指标会失去意义。例如:100个样本中负样本占有98个,那么分类器只需将所有样本分为负类即可达到98%的准确度。
- 公式:accuracy=TP+FNTP+FN+FP+TNaccuracy = \frac{TP + FN}{TP+FN+FP+TN}accuracy=TP+FN+FP+TNTP+FN
(2) Precesion(精确度):
- 意义:衡量分类器对于正样本的查准率,表示分类器对于正负样本的区分能力。当区分能力强时,容易将部分(与负样本相似度高)正样本排除。
- 公式:precesion=TPTP+FPprecesion = \frac{TP}{TP+FP}precesion=TP+FPTP
(3) Recall(召回率)、敏感性:
- 意义:衡量分类器对于正样本的查全率,表示分类器对于正样本的敏感度或覆盖度。当敏感度高时,容易将部分(与正样本相似度高)负样本也判断为正样本。
- 公式:recall=TPTP+FNrecall = \frac{TP}{TP+FN}recall=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 672
672




 到【灌水乐园】发言
到【灌水乐园】发言







