



1 环境配置
部署环境为8卡V100,cuda12.0,系统Ubuntu 20.04.6 LTS
!注意V100不能运行flash-attention
按照官方文档的快速开始
# 启动 docker container
docker run --runtime=nvidia -it --rm --shm-size="10g" --cap-add=SYS_ADMIN -v $PWD:/openrlhf nvcr.io/nvidia/pytorch:24.07-py3 bash
sudo pip uninstall xgboost transformer_engine flash_attn pynvml -y
# pip install
pip install openrlhf
# 如果你需要使用 vLLM 加速 (安装 vLLM 0.8.5.post1)
pip install openrlhf[vllm]
# 最新的 vLLM 也是支持的
pip install openrlhf[vllm_latest]
# pip install GitHub 上的最新版
pip install git+https://github.com/OpenRLHF/OpenRLHF.git
# 或者 git clone
git clone https://github.com/OpenRLHF/OpenRLHF.git
cd OpenRLHF
pip install -e .
这里由于我的机器已经在docker上了,就使用uv管理环境,但是在安装openrlhf[vllm]包时,会报错没有torch
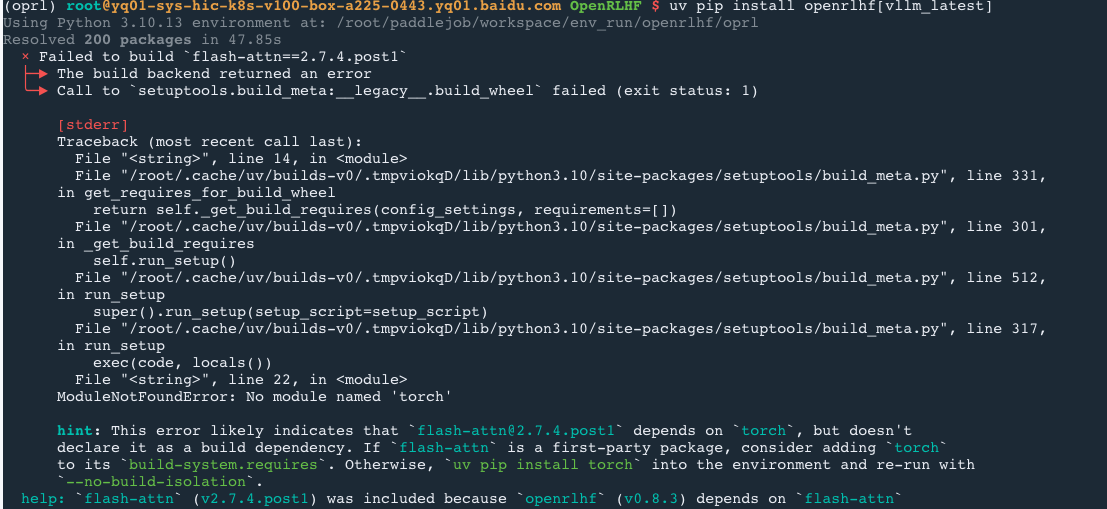
如果继续使用–no-build-isolation安装openrlhf。可以正常运行reward model
但是这种方法继续执行安装vllm的话,又会报flash-attn和torch版本不匹配的错误。因为安装vllm会自动安装对应的torch版本,覆盖掉之前与flash-attn匹配的torch版本。重点是vllm、torch和flash-attn版本的对应
果然装环境是最麻烦的😡,其实是flashattn和torch和vllm版本不一样
使用以下安装配置
首先建立环境
uv venv openrlhf --python=3.10
source openrlhf/bin/activate
# 先装好一个torch
uv pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
uv pip install setuptools
git clone https://github.com/OpenRLHF/OpenRLHF.git
uv pip install openrlhf[vllm_latest] --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple # 这里会自动安装torch
cd OpenRLHF
uv pip install -e . --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple # 目前最新版本的vllm是0.8.5.post1,安装vllm后会覆盖原来的torch
# 重新安装2.6.0版本的torch,cuda版本12.1
uv pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
目前匹配的版本:torch2.6.0➕cuda12.1➕flash-attn 2.7.4.post1➕vllm0.8.5.post1
以上过程哪个包不匹配重新安装哪个包(2025年6月18号最近又更新了新版本的包,如果上面安装vllm时没有指定版本会安装新版本的包,请在安装完成后将flash-attn和vllm降级回对应的版本)
当前机器配置为:Driver Version: 525.125.06 ➕ CUDA Version: 12.0 ➕Ubuntu 20.04.6 LTS
2 训练Reward model
后续运行reward model和开展ppo训练的时候,关于flash-attn的位置不会报错了
但是会继续出现其他错误:
- bfloat16精度不支持,将相关的参数去掉
- 权重文件下载缓慢,将权重下载好后上传到服务器,然后修改加载权重位置为实际路径
因为V100不支持flash-attn训练,所以我的启动命令为
deepspeed --module openrlhf.cli.train_rm \
--save_path ./checkpoint/llama3-8b-rm \
--save_steps -1 \
--logging_steps 1 \
--eval_steps -1 \
--train_batch_size 256 \
--micro_train_batch_size 1 \
--pretrain OpenRLHF/Llama-3-8b-sft-mixture \
--max_epochs 1 \
--max_len 8192 \
--zero_stage 3 \
--learning_rate 9e-6 \
--dataset OpenRLHF/preference_dataset_mixture2_and_safe_pku \
--apply_chat_template \
--chosen_key chosen \
--rejected_key rejected \
--gradient_checkpointing \
--load_checkpoint \
--use_wandb {自己的wandb}
去掉了bfloat和flash-attn相关指令。
上面的错误解决后,使用V100继续进行训练会出现卡住的情况,还不清楚具体问题出现在哪里,后续继续更新
————————————————————————————————————————
更新,找到为什么卡住不会动了。有一张显卡坏了好像,导致那张卡的数据一直加载不出来
在运行指令前添加 CUDA_VISIBLE_DEVICES=4,5,6,7 ,只使用最后四张卡训练reward model。
3 更换A100训练Reward Model
之前使用V100显卡会爆炸显存,更换4张A800显卡进行训练
更换A800显卡后可以使用官方文档的训练reward model命令进行训练
换一种权重下载方式,使用huggingface官方下载
uv pip install -U huggingface_hub
huggingface-cli download OpenRLHF/Llama-3-8b-sft-mixture --local-dir /root/paddlejob/workspace/env_run/OpenRLHF/Llama-3-8b-sft-mixture --local-dir-use-symlinks False --resume-download
权重下载好之后,执行运行指令
deepspeed --module openrlhf.cli.train_rm \
--save_path ./checkpoint/llama3-8b-rm \
--save_steps -1 \
--logging_steps 1 \
--eval_steps -1 \
--train_batch_size 256\
--micro_train_batch_size 1 \
--pretrain ./Llama-3-8b-sft-mixture \
--max_epochs 1 \
--max_len 8192 \
--zero_stage 3 \
--learning_rate 9e-6 \
--dataset OpenRLHF/preference_dataset_mixture2_and_safe_pku \
--apply_chat_template \
--chosen_key chosen \
--rejected_key rejected \
--gradient_checkpointing \
--load_checkpoint \
--bf16 \
--flash_attn \
--packing_samples \
--use_wandb xxxxxxxxxxx
执行参数说明
参数说明
save_steps # 为-1表示不保存模型权重,否则的话每隔save_steps保存一次权重
logging_steps # 每隔多少次保存一次log
eval_steps # 每隔多少次执行评价,如果为-1,则每隔(数据总量/batchsize)评价一次
train_batch_size # 训练bs大小
micro_train_batch_size # micro batchsize
pretrain # 训练reward model使用的模型,使用相对于OpenRLHF文件夹的位置或者绝对位置
max_epochs # 训练epoch数量
max_len # 过滤掉长度大于8192的样本
zero_stage # 启用zero_stage 3来节省显存
apply_chat_template # tokenizer的一种处理格式,将输入的prompt应用特定的聊天模版
gradient_checkpointing # 是否启用gradient_checkpointing节省显存
load_checkpoint # 继续训练,加载模型权重
bf16 # 启用混合精度训练
flash_attn #是否启用flash_attn
packing_samples #启用packing_samples会默认启用flash_attn
4 运行PPO训练
ppo运行除了需要准备actor模型的权重,还需要准备reward模型的权重。依然需要使用huggingface_hub下载或者自定义。
1, 首先启动ray
ray start --head --node-ip-address 0.0.0.0 --num-gpus 4 # 先使用ray启动主节点
2,递交训练任务
ray job submit --address="http://127.0.0.1:8265" --runtime-env-json='{"working_dir": "./OpenRLHF", "excludes": ["Llama-3-8b-sft-mixture/*.safetensors", "Llama-3-8b-rm-700k/*.safetensors", "wandb/**/*","*.wandb"]}' -- python3 -m openrlhf.cli.train_ppo_ray --ref_num_nodes 1 --ref_num_gpus_per_node 4 --reward_num_nodes 1 --reward_num_gpus_per_node 4 --critic_num_nodes 1 --critic_num_gpus_per_node 4 --actor_num_nodes 1 --actor_num_gpus_per_node 4 --vllm_num_engines 4 --vllm_tensor_parallel_size 1 --colocate_all_models --vllm_gpu_memory_utilization 0.3 --pretrain /root/paddlejob/workspace/env_run/OpenRLHF/Llama-3-8b-sft-mixture --reward_pretrain /root/paddlejob/workspace/env_run/OpenRLHF/Llama-3-8b-rm-700k --save_path /openrlhf/examples/test_scripts/final/llama3-8b-rlhf --ckpt_path /openrlhf/examples/test_scripts/ckpt/llama3-8b-rlhf --save_hf_ckpt --micro_train_batch_size 1 --train_batch_size 32 --micro_rollout_batch_size 2 --rollout_batch_size 8 --n_samples_per_prompt 1 --max_epochs 1 --prompt_max_len 1024 --max_samples 100000 --generate_max_len 1024 --zero_stage 3 --bf16 --actor_learning_rate 5e-7 --critic_learning_rate 9e-6 --init_kl_coef 0.01 --prompt_data OpenRLHF/prompt-collection-v0.1 --input_key context_messages --apply_chat_template --normalize_reward --gradient_checkpointing --packing_samples --vllm_sync_backend nccl --enforce_eager --vllm_enable_sleep --deepspeed_enable_sleep --use_wandb xxxxxxx
执行参数说明
ray job submit --address="http://127.0.0.1:8265" \
--runtime-env-json='{"working_dir":"./OpenRLHF", "excludes": ["Llama-3-8b-sft-mixture/*.safetensors", "Llama-3-8b-rm-700k/*.safetensors", "wandb/**/*","*.wandb"]}' \
# ./OpenRLHF指定的是OpenRLHF的根目录,所有的相对文件是相对于这个路径,excludes字段是为了排除OpenRLHF中的部分文件夹,因为这些文件夹中包含一些很大的权重文件,直接上传到服务器节点会导致上传时间过长报错
-- python3 -m openrlhf.cli.train_ppo_ray \ # 运行脚本
--vllm_num_engines 4 \ # 指定vllm引擎初始化数量,ppo训练需要使用4个模型,因此规定为4
--vllm_tensor_parallel_size 1 \ # 每个引擎使用显卡的数量
--colocate_all_models \ # 如果启用,将模型尽可能压缩防止模型到更少的gpu上
--vllm_gpu_memory_utilization 0.5 \ # vllmGPU利用率,决定每个vllm引擎利用gpu的利用率,这也是一个解决OOM很关键的参数。
--pretrain /root/paddlejob/workspace/env_run/OpenRLHF/Llama-3-8b-sft-mixture \ # 使用绝对路径或者相对OpenRLHF的路径
--reward_pretrain /root/paddlejob/workspace/env_run/Llama-3-8b-rm-700k \
--save_path ./openrlhf/examples/test_scripts/final/llama3-8b-rlhf \
--ckpt_path ./openrlhf/examples/test_scripts/ckpt/llama3-8b-rlhf \
--save_hf_ckpt \
--micro_train_batch_size 8 \ # 运行时每张卡上的batchsize大小,比如设置为8,那么4张卡同时可以处理32个样本
--train_batch_size 128 \ # 没有找到具体在哪里出现了
--micro_rollout_batch_size 16 \ # 在采样经验的时候使用的bs大小,不参与后续训练过程中的bs
--rollout_batch_size 1024 \ #从所有样本中抽取1024个样本进行训练,在训练critic模型和actor模型时,一个epoch内,模型处理的所有样本数量为1024。比如micro_train_batch_size为8,那么一共可以划分为32个batch,因为1024/(8*4)=32,模型一次处理32个样本。如果OOM,需要调节的参数是micro_trainbs和rollout_bs,这两个主要控制每次更新模型的时候使用显存大小,还需要保证micro_rollout_bs是rollout_bs的因数。
--n_samples_per_prompt 1 \
--max_epochs 1 \
--prompt_max_len 1024 \
--max_samples 100000 \
--generate_max_len 1024 \
--zero_stage 3 \
--bf16 \
--actor_learning_rate 5e-7 \
--critic_learning_rate 9e-6 \
--init_kl_coef 0.01 \
--prompt_data OpenRLHF/prompt-collection-v0.1 \
--input_key context_messages \
--apply_chat_template \
--normalize_reward \
--gradient_checkpointing \
--packing_samples \
--vllm_sync_backend nccl \
--enforce_eager \
--vllm_enable_sleep \
--deepspeed_enable_sleep \
--use_wandb 6670f393b1f8b8eeeb7a21647429ff4b70b03d41


















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









