






 本文通过使用Python进行房价预测,详细介绍了从数据读取到初步分析的过程。运用pandas、numpy、matplotlib和seaborn等库,对训练数据进行描述性统计分析,并通过散点图和分布图展示目标变量'SalePrice'的分布特性,揭示其偏态和峰度。同时,分析了'GrLivArea'与'SalePrice'之间的关系。
本文通过使用Python进行房价预测,详细介绍了从数据读取到初步分析的过程。运用pandas、numpy、matplotlib和seaborn等库,对训练数据进行描述性统计分析,并通过散点图和分布图展示目标变量'SalePrice'的分布特性,揭示其偏态和峰度。同时,分析了'GrLivArea'与'SalePrice'之间的关系。
参考:https://blog.youkuaiyun.com/Amy_mm/article/details/79538083
https://www.kaggle.com/pmarcelino/comprehensive-data-exploration-with-python(处理回归)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns # 统计绘图
from sklearn.preprocessing import StandardScaler
from scipy.stats import norm
from scipy import stats # 统计
import warnings
warnings.filterwarnings('ignore')
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
print(f"columns:{df_train.columns}")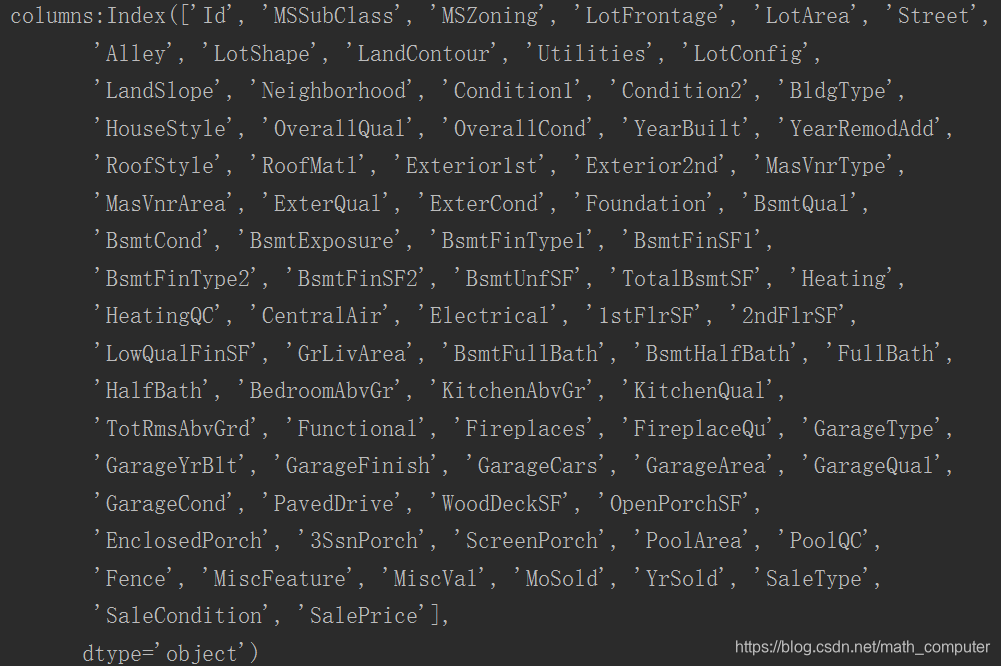
print(df_train['SalePrice'].describe())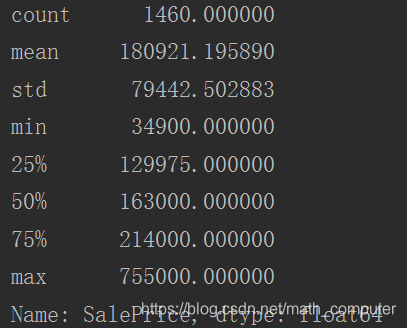
sns.distplot(df_train['SalePrice'])
plt.show()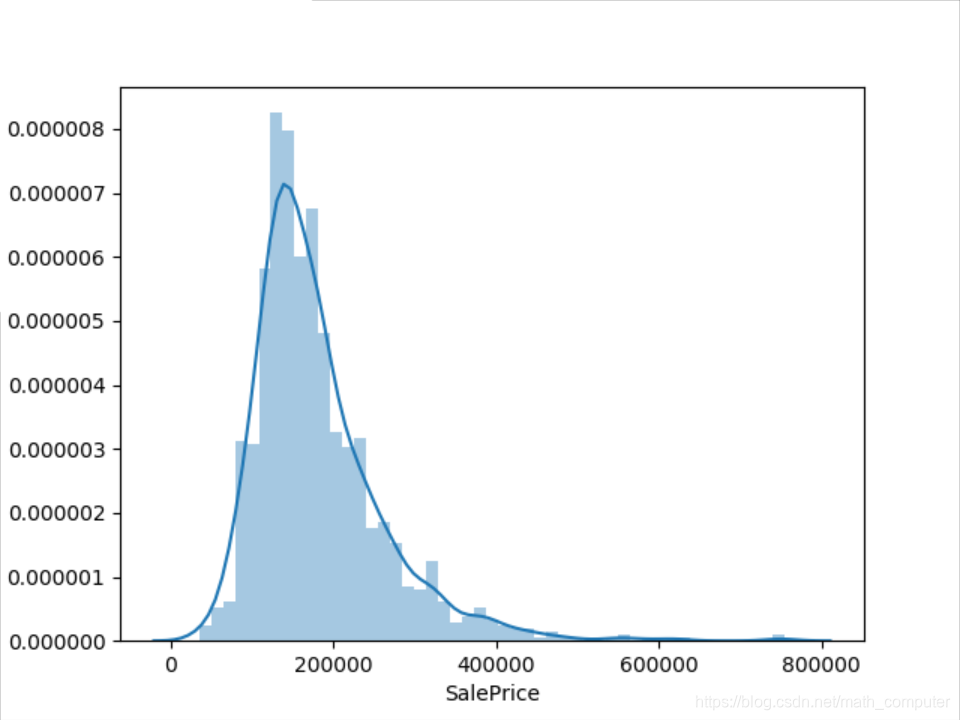
#show skewness and Kurtosis 偏态和峰度
print("Skewness : %f " % df_train['SalePrice'].skew())
print("Kurtosis : %f " % df_train['SalePrice'].kurt())![]()
# scatter plot Grlivearea / SalePrice
var = 'GrLivArea'
# pd.concat 函数可以将数据根据不同的轴作简单的融合 axis = 0-->代表行 axis = 1 --> 代表列
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0, 800000))
plt.show()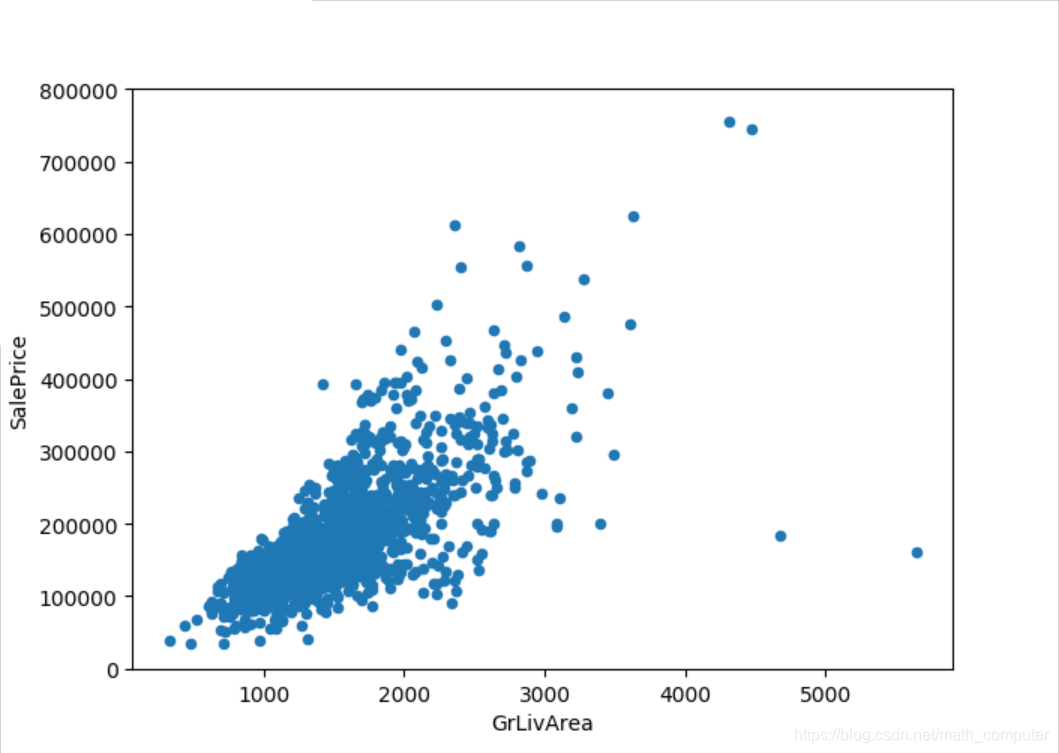

















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









