



1. 根据课程联系vim的使用,无需总结,多敲多练
基础操作
-
启动/退出
- 启动:
vim 文件名 - 退出:正常模式输入
:q(不保存)或:wq(保存退出) - 强制退出:
:q!(放弃修改)
- 启动:
-
模式切换
i→ 进入插入模式(光标前插入)a→ 进入插入模式(光标后插入)Esc→ 返回正常模式:→ 进入命令行模式
-
光标移动
h j k l→ 左/下/上/右gg→ 跳转到文件首行G→ 跳转到文件末行Ctrl+f/Ctrl+b→ 向下/上翻页
-
文本编辑
dd→ 删除当前行yy→ 复制当前行p→ 粘贴u→ 撤销操作Ctrl+r→ 重做操作
进阶操作
-
查找替换
/关键词→ 正向搜索,n跳转下一个:%s/旧内容/新内容/g→ 全局替换(加c可确认每次替换)
-
分屏操作
:sp 文件名→ 水平分屏:vsp 文件名→ 垂直分屏Ctrl+w + 方向键→ 切换分屏
-
可视化模式
v→ 进入字符选择模式V→ 进入行选择模式Ctrl+v→ 进入块选择模式(列编辑)
常用配置(在 ~/.vimrc 中设置)
vim
1set number " 显示行号
2syntax on " 语法高亮
3set tabstop=4 " Tab 缩进为4空格
4set autoindent " 自动缩进
5set mouse=a " 启用鼠标支持(可选)
2. 创建一个文件,添加内容,并且演示课程命令cat,tail,more等等相关文本处理工具的用法,并且总结到博客,添加详细的注释信息
cat
连接多个文件并打印到标准输出
语法
file [options] <filename>...
选项
-b|--brief #只显示结果,不显示文件名
-f|--files-from FILE #从指定文件中获取要处理的文件名
-F|--separator STRING #指定分割符
-L|--dereference #跟随软链接
例子
# 合并显示多个文件
cat ./1.log ./2.log ./3.log
# 显示文件中的非打印字符、tab、换行符
cat -A test.log
# 压缩文件的空行
cat -s test.log
# 显示文件并在所有行开头附加行号
cat -n test.log
# 显示文件并在所有非空行开头附加行号
cat -b test.log
# 将标准输入的内容和文件内容一并显示
echo '######' |cat - test.log
tail
在屏幕上显示指定文件的末尾若干行
语法
tail (选项) (参数)
选项
-c, --bytes=NUM #输出文件尾部的NUM(NUM为整数)个字节内容。
-f, --follow[={name|descript}] #显示文件最新追加的内容。“name”表示以文件名的方式监视文件的变化。
-F #与 “--follow=name --retry” 功能相同。
例子
tail file #(显示文件file的最后10行)
tail -n +20 file #(显示文件file的内容,从第20行至文件末尾)
tail -c 10 file #(显示文件file的最后10个字节)
tail -25 mail.log # 显示 mail.log 最后的 25 行
tail -f mail.log # 等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止
tail -F mail.log # 等同于--follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
more
显示文件内容,每次显示一屏
语法
more(语法)(参数)
选项
-<数字>:指定每屏显示的行数;
-d:显示“[press space to continue,'q' to quit.]”和“[Press 'h' for instructions]”;
-c:不进行滚屏操作。每次刷新这个屏幕;
-s:将多个空行压缩成一行显示;
-u:禁止下划线;
例子
more -dc file #显示文件file的内容,但在显示之前先清屏,并且在屏幕的最下方显示完成的百分比。
more -c -10 file #显示文件file的内容,每10行显示一次,而且在显示之前先清屏。
3. 总结正则表达式的语法
基本正则表达式
#字符匹配
. #匹配任意单个字符,不含空格
[] #匹配指定范围内的任意字符,如:[a-z]、[A-Z]、[0-9]
[^] #匹配指定范围外的任意单个字符,取反
[:alnum:] #字母和数字,与[A-Za-z0-9]等价
[:alpa:] #字母,与[A-Za-z]等价
[:digit:] #数字,与[0-9]等价
[:xdigit:] #十六进制字符,与[0-9A-Fa-f]等价
[:blank:] #空格和制表符
[:lower:] #小写字母
[:upper:] #大写字母
[:space:] #空白字符,等价于[\t\r\n\v\f]
[:punct:] #标点符号
#匹配次数
#用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* #贪婪模式, 匹配*号前面的字符任意次,仅表示次数: 0 次或多次(>=0次), 与匹配文件的通配符意义不一样
.* #任意长度的任意字符,含空格
\? #匹配其前面的字符0或1次,即前面的字符可有可无
\+ #匹配其前面的字符至少1次
\{m,n\} #匹配至少m次,最多n次
\{m\} #匹配前面的字符m次
\{m,\} #匹配前面的字符至少m次,多则不限
#位置锚定
^ #行首锚定, 如:^root
$ #行尾锚定, 如:bash$
^PATTERN$ #用于模式匹配整行,如: ^$ 表示空间
\<或\b #词首锚定,用于单词模式的左侧
\>或\b #词尾锚定,用于单词模式的右侧
\<PATTERN\> #匹配整个单词
#分组
\(\) #将1个或多个字符捆绑在一起,当做一个整体进行处理,如: \(xy\)*ab
#分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为:\1,\2,\3....
\1 #从左侧起,第1个左括号以及与之匹配右括号之间的模式所匹配到的字符
扩展正则表达式
#元字符
. #匹配任意单个字符,不含空格
[] #匹配指定范围内的任意字符,如:[a-z]、[A-Z]、[0-9]
[^] #匹配指定范围外的任意单个字符,取反
#次数匹配
* #贪婪模式, 匹配*号前面的字符任意次,仅表示次数: 0 次或多次(>=0次), 与匹配文件的通配符意义不一样
? #匹配其前面的字符0或1次,即前面的字符可有可无
+ #匹配其前面的字符至少1次
{m} #匹配前面的字符m次
{m,n} #匹配至少m次,最多n次
#锚定
^ #行首锚定, 如:^root
$ #行尾锚定, 如:bash$
\<,\b #词首锚定,用于单词模式的左侧
\>,\b #词尾锚定,用于单词模式的右侧
#分组
()
#或
a|b #a或b
C|cat #C或cat
4. 文本三剑客相关的总结,grep的用法,sed的语法和awk的语法(此部分需要多练习)
练习相关题目:https://www.cnblogs.com/zll1217/articles/15394141.html
grep
强大的文本搜索工具
语法
grep [option] pattern file
选项
a --text # 不要忽略二进制数据。
-A <显示行数> --after-context=<显示行数> # 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b --byte-offset # 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-B<显示行数> --before-context=<显示行数> # 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count # 计算符合范本样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> # 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> --directories=<动作> # 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> # 指定字符串作为查找文件内容的范本样式。
-E --extended-regexp # 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> --file=<规则文件> # 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F --fixed-regexp # 将范本样式视为固定字符串的列表。
-G --basic-regexp # 将范本样式视为普通的表示法来使用。
-h --no-filename # 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H --with-filename # 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i --ignore-case # 忽略字符大小写的差别。
-l --file-with-matches # 列出文件内容符合指定的范本样式的文件名称。
-L --files-without-match # 列出文件内容不符合指定的范本样式的文件名称。
-n --line-number # 在显示符合范本样式的那一列之前,标示出该列的编号。
-P --perl-regexp # PATTERN 是一个 Perl 正则表达式
-q --quiet或--silent # 不显示任何信息。
-R/-r --recursive # 此参数的效果和指定“-d recurse”参数相同。
-s --no-messages # 不显示错误信息。
-v --revert-match # 反转查找。
-V --version # 显示版本信息。
-w --word-regexp # 只显示全字符合的列。
-x --line-regexp # 只显示全列符合的列。
-y # 此参数效果跟“-i”相同。
-o # 只输出文件中匹配到的部分。
-m <num> --max-count=<num> # 找到num行结果后停止查找,用来限制匹配行数
sed
功能强大的流式文本编辑器
语法
sed [options] 'command' file(s)
sed [options] -f scriptfile file(s)
选项
a\ # 在当前行下面插入文本。
i\ # 在当前行上面插入文本。
c\ # 把选定的行改为新的文本。
d # 删除,删除选择的行。
D # 删除模板块的第一行。
s # 替换指定字符
h # 拷贝模板块的内容到内存中的缓冲区。
H # 追加模板块的内容到内存中的缓冲区。
g # 获得内存缓冲区的内容,并替代当前模板块中的文本。
G # 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l # 列表不能打印字符的清单。
n # 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N # 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p # 打印模板块的行。
P # (大写) 打印模板块的第一行。
q # 退出Sed。
b lable # 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
r file # 从file中读行。
t label # if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
T label # 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file # 写并追加模板块到file末尾。
W file # 写并追加模板块的第一行到file末尾。
! # 表示后面的命令对所有没有被选定的行发生作用。
= # 打印当前行号码。
# # 把注释扩展到下一个换行符以前。
awk
文本和数据进行处理的编程语言
语法
awk [options] 'script' var=value file(s)
awk [options] -f scriptfile var=value file(s)
选项
-F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or --asign var=value 赋值一个用户定义变量。
-f scripfile or --file scriptfile 从脚本文件中读取awk命令。
内置变量:
FILENAME:当前文件名
FS:字段分隔符,默认是空格和制表符。
RS:行分隔符,用于分割每一行,默认是换行符。
OFS:输出字段的分隔符,用于打印时分隔字段,默认为空格。
ORS:输出记录的分隔符,用于打印时分隔记录,默认为换行符。
OFMT:数字输出的格式,默认为%.6g。
函数:
awk还提供了一些内置函数,方便对原始数据的处理。主要如下:
toupper():字符转为大写。
tolower():字符转为小写。
length():返回字符串长度。
substr():返回子字符串。
sin():正弦。
cos():余弦。
sqrt():平方根。
rand():随机数。
5. 总结程序的组成相关知识点
1. 基本元素
变量与常量:存储数据的标识符,变量值可变,常量不可变。
数据类型:基础类型(整数、浮点数、布尔、字符等)、复合类型(数组、结构体、枚举)、引用类型(指针、对象)。
运算符与表达式:算术、逻辑、比较运算符等,组合成表达式进行运算。
2. 控制结构
顺序结构:代码按顺序逐行执行。
条件分支:if-else、switch-case 实现逻辑判断。
循环结构:for、while、do-while 处理重复任务。
跳转语句:break、continue、return 等控制流程。
3. 函数与方法
定义与调用:封装代码块,通过参数传递数据,返回结果。
作用域:局部变量(函数内有效)与全局变量(整个程序有效)。
递归:函数调用自身解决分治问题。
4. 数据结构
线性结构:数组、链表、栈、队列。
非线性结构:树、图、哈希表(字典)、集合。
特性与应用:如栈的先进后出(LIFO),队列的先进先出(FIFO)等。
5. 程序结构
模块化:函数、类、模块分割功能,提高复用性。
面向对象:类与对象、封装、继承、多态。
包与命名空间:组织代码,避免命名冲突。
6. 输入输出(I/O)
标准I/O:控制台输入(如 input())、输出(如 print())。
文件操作:读写文本/二进制文件(open、read、write)。
网络通信:HTTP请求、Socket编程等。
7. 错误处理
异常机制:try-catch-finally 捕获和处理异常。
错误码:通过返回值表示执行状态。
断言:assert 验证程序逻辑正确性。
8. 内存管理
内存分配:堆(动态分配)、栈(自动分配局部变量)。
垃圾回收:自动回收无用内存(如Java、Python)。
指针/引用:直接操作内存地址(如C/C++)。
9. 注释与文档
代码注释:单行(//)、多行(/* */)、文档字符串(""")。
API文档:说明函数/类的用途、参数、返回值(如Javadoc、Doxygen)。
10. 执行流程
入口函数:如 main() 是程序起点。
并发模型:多线程、多进程、协程(异步编程)。
11. 编程范式
面向过程:以过程(函数)为核心,如C语言。
面向对象:以对象为核心,如Java、Python。
函数式编程:强调不可变数据和纯函数,如Haskell、JavaScript。
12. 测试与调试
单元测试:验证函数/模块功能正确性(如JUnit、pytest)。
调试工具:断点、单步执行(IDE集成工具)。
日志记录:追踪程序运行状态(如Log4j、logging模块)。
13. 构建与依赖
构建工具:自动化编译(如Make、CMake、Gradle)。
包管理:安装第三方库(如pip、npm、Maven)。
环境配置:虚拟环境(venv)、容器化(Docker)。
14. 接口与库
API设计:定义模块/服务的交互规范。
第三方库:复用现有功能(如NumPy、Requests)。
框架集成:如Spring(Java)、Django(Python)。
6. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
一、变量命名规则
- 字符限制
- 仅包含字母、数字、下划线(
A-Z, a-z, 0-9, _)。 - 禁止以数字开头,如
2var无效。
- 仅包含字母、数字、下划线(
- 大小写敏感
VAR和var视为不同变量。
- 赋值语法
- 等号两侧无空格:
VAR=value(错误写法:VAR = value)。
- 等号两侧无空格:
- 引用变量
- 使用
$VAR或${VAR}(推荐后者避免歧义)。
- 使用
二、变量类型及使用
1. 环境变量 (Environment Variables)
- 作用:全局生效,传递给子进程(如脚本、命令)。
- 声明方式
1export VAR=value # 直接导出 2或 3VAR=value; export VAR - 示例
1export PATH="/usr/local/bin:$PATH" # 添加路径到环境变量 - 注意事项
- 使用
env或printenv查看所有环境变量。
- 使用
2. 位置变量 (Positional Parameters)
- 作用:获取脚本/函数参数,如
$1表示第一个参数。 - 特殊变量
$0:脚本/命令名称$#:参数个数$@:所有参数(每个参数独立)$*:所有参数(合并为单个字符串)
- 示例
1# 脚本内容 2echo "第一个参数: $1" 3echo "参数总数: $#" - 注意事项
- 参数超过9个时需用
${10},而非$10。
- 参数超过9个时需用
3. 只读变量 (Read-only Variables)
- 作用:防止变量被修改或删除。
- 声明方式
1readonly VAR=value 2或 3VAR=value; readonly VAR - 示例
1readonly PI=3.14 2PI=4.2 # 报错:无法修改只读变量 - 注意事项
- 不可用
unset删除只读变量。
- 不可用
4. 局部变量 (Local Variables)
- 作用:限制变量作用域为函数内部。
- 声明方式
1function my_func() { 2 local VAR=value # 仅函数内有效 3} - 示例
1function demo() { 2 local msg="Hello" 3 echo $msg 4} 5demo # 输出 "Hello" 6echo $msg # 输出空值(变量未定义) - 注意事项
- 避免函数内外变量命名冲突。
5. 状态变量 (Exit Status Variable)
- 作用:获取上一个命令的退出状态。
- 变量名:
$? - 取值规则
0:成功- 非
0:失败(具体值表示错误类型)
- 示例
1grep "pattern" file.txt 2if [ $? -eq 0 ]; then 3 echo "匹配成功" 4else 5 echo "匹配失败" 6fi - 注意事项
- 立即使用
$?,其值会被后续命令覆盖。
- 立即使用
三、总结
- 命名规范:字母/下划线开头,避免特殊字符。
- 变量类型选择:
- 需全局共享 → 环境变量
- 处理脚本参数 → 位置变量
- 防止误修改 → 只读变量
- 函数封装 → 局部变量
- 错误处理 → 状态变量
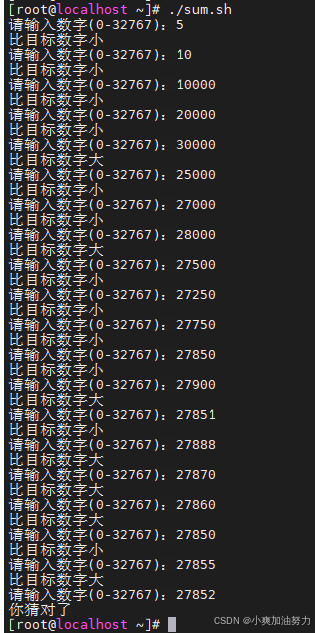
7. 编写一个脚本猜数字,每次提示用户比目标数字是大还是小,直到猜成功位置
vim sum.sh
#!/bin/bash
randomsum=$RANDOM
while true;do
read -p "请输入数字(0-32767):" sum
if [ $sum -gt $randomsum ];then
echo "比目标数字大"
else
if [ $sum -lt $randomsum ];then
echo "比目标数字小"
else
echo "你猜对了"
fi
fi
done

















 1788
1788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









